 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can Pretrained LLMs Go in Symbolic Music? Controlled Comparisons of Supervised and Preference-based Adaptation
Jan 30, 2026Music often shares notable parallels with language, motivating the use of pretrained large language models (LLMs) for symbolic music understanding and generation. Despite growing interest, the practical effectiveness of adapting instruction-tuned LLMs to symbolic music remains insufficiently characterized. We present a controlled comparative study of finetuning strategies for ABC-based generation and understanding, comparing an off-the-shelf instruction-tuned backbone to domain-adapted variants and a music-specialized LLM baseline. Across multiple symbolic music corpora and evaluation signals, we provide some insights into adaptation choices for symbolic music applications. We highlight the domain adaptation vs.~preserving prior information tradeoff as well as the distinct behaviour of metrics used to measure the domain adaptation for symbolic music.
MUSE-Explainer: Counterfactual Explanations for Symbolic Music Graph Classification Models
Sep 30, 2025Interpretability is essential for deploying deep learning models in symbolic music analysis, yet most research emphasizes model performance over explanation. To address this, we introduce MUSE-Explainer, a new method that helps reveal how music Graph Neural Network models make decisions by providing clear, human-friendly explanations. Our approach generates counterfactual explanations by making small, meaningful changes to musical score graphs that alter a model's prediction while ensuring the results remain musically coherent. Unlike existing methods, MUSE-Explainer tailors its explanations to the structure of musical data and avoids unrealistic or confusing outputs. We evaluate our method on a music analysis task and show it offers intuitive insights that can be visualized with standard music tools such as Verovio.
Language Models for Music Medicine Generation
Nov 13, 2024
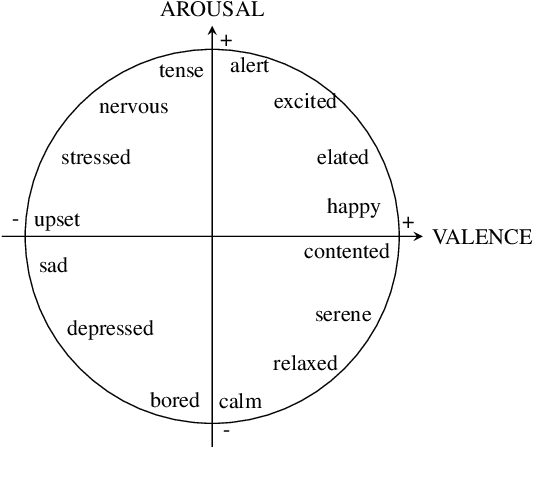
Music therapy has been shown in recent years to provide multiple health benefits related to emotional wellness. In turn, maintaining a healthy emotional state has proven to be effective for patients undergoing treatment, such as Parkinson's patients or patients suffering from stress and anxiety. We propose fine-tuning MusicGen, a music-generating transformer model, to create short musical clips that assist patients in transitioning from negative to desired emotional states. Using low-rank decomposition fine-tuning on the MTG-Jamendo Dataset with emotion tags, we generate 30-second clips that adhere to the iso principle, guiding patients through intermediate states in the valence-arousal circumplex. The generated music is evaluated using a music emotion recognition model to ensure alignment with intended emotions. By concatenating these clips, we produce a 15-minute "music medicine" resembling a music therapy session. Our approach is the first model to leverage Language Models to generate music medicine. Ultimately, the output is intended to be used as a temporary relief between music therapy sessions with a board-certified therapist.
GraphMuse: A Library for Symbolic Music Graph Processing
Jul 17, 2024

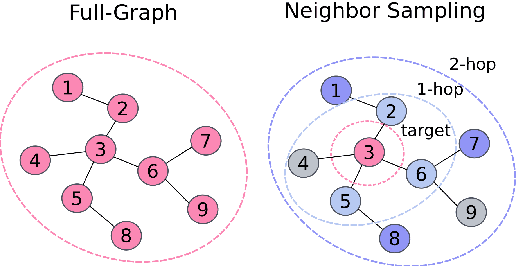

Graph Neural Networks (GNNs) have recently gained traction in symbolic music tasks, yet a lack of a unified framework impedes progress. Addressing this gap, we present GraphMuse, a graph processing framework and library that facilitates efficient music graph processing and GNN training for symbolic music tasks. Central to our contribution is a new neighbor sampling technique specifically targeted toward meaningful behavior in musical scores. Additionally, GraphMuse integrates hierarchical modeling elements that augment the expressivity and capabilities of graph networks for musical tasks. Experiments with two specific musical prediction tasks -- pitch spelling and cadence detection -- demonstrate significant performance improvement over previous methods. Our hope is that GraphMuse will lead to a boost in, and standardization of, symbolic music processing based on graph representations. The library is available at https://github.com/manoskary/graphmuse
Perception-Inspired Graph Convolution for Music Understanding Tasks
May 15, 2024



We propose a new graph convolutional block, called MusGConv, specifically designed for the efficient processing of musical score data and motivated by general perceptual principles. It focuses on two fundamental dimensions of music, pitch and rhythm, and considers both relative and absolute representations of these components. We evaluate our approach on four different musical understanding problems: monophonic voice separation, harmonic analysis, cadence detection, and composer identification which, in abstract terms, translate to different graph learning problems, namely, node classification, link prediction, and graph classification. Our experiments demonstrate that MusGConv improves the performance on three of the aforementioned tasks while being conceptually very simple and efficient. We interpret this as evidence that it is beneficial to include perception-informed processing of fundamental musical concepts when developing graph network applications on musical score data.
SMUG-Explain: A Framework for Symbolic Music Graph Explanations
May 15, 2024In this work, we present Score MUsic Graph (SMUG)-Explain, a framework for generating and visualizing explanations of graph neural networks applied to arbitrary prediction tasks on musical scores. Our system allows the user to visualize the contribution of input notes (and note features) to the network output, directly in the context of the musical score. We provide an interactive interface based on the music notation engraving library Verovio. We showcase the usage of SMUG-Explain on the task of cadence detection in classical music. All code is available on https://github.com/manoskary/SMUG-Explain.
Sounding Out Reconstruction Error-Based Evaluation of Generative Models of Expressive Performance
Dec 31, 2023Generative models of expressive piano performance are usually assessed by comparing their predictions to a reference human performance. A generative algorithm is taken to be better than competing ones if it produces performances that are closer to a human reference performance. However, expert human performers can (and do) interpret music in different ways, making for different possible references, and quantitative closeness is not necessarily aligned with perceptual similarity, raising concerns about the validity of this evaluation approach. In this work, we present a number of experiments that shed light on this problem. Using precisely measured high-quality performances of classical piano music, we carry out a listening test indicating that listeners can sometimes perceive subtle performance difference that go unnoticed under quantitative evaluation. We further present tests that indicate that such evaluation frameworks show a lot of variability in reliability and validity across different reference performances and pieces. We discuss these results and their implications for quantitative evaluation, and hope to foster a critical appreciation of the uncertainties involved in quantitative assessments of such performances within the wider music information retrieval (MIR) community.
8+8=4: Formalizing Time Units to Handle Symbolic Music Durations
Oct 23, 2023This paper focuses on the nominal durations of musical events (notes and rests) in a symbolic musical score, and on how to conveniently handle these in computer applications. We propose the usage of a temporal unit that is directly related to the graphical symbols in musical scores and pair this with a set of operations that cover typical computations in music applications. We formalize this time unit and the more commonly used approach in a single mathematical framework, as semirings, algebraic structures that enable an abstract description of algorithms/processing pipelines. We then discuss some practical use cases and highlight when our system can improve such pipelines by making them more efficient in terms of data type used and the number of computations.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 10, 2023Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.
* To be published in the Proceedings of the 24th International Society for Music Information Retrieval Conference (ISMIR 2023), Milan, Italy
Roman Numeral Analysis with Graph Neural Networks: Onset-wise Predictions from Note-wise Features
Jul 12, 2023Roman Numeral analysis is the important task of identifying chords and their functional context in pieces of tonal music. This paper presents a new approach to automatic Roman Numeral analysis in symbolic music. While existing techniques rely on an intermediate lossy representation of the score, we propose a new method based on Graph Neural Networks (GNNs) that enable the direct description and processing of each individual note in the score. The proposed architecture can leverage notewise features and interdependencies between notes but yield onset-wise representation by virtue of our novel edge contraction algorithm. Our results demonstrate that ChordGNN outperforms existing state-of-the-art models, achieving higher accuracy in Roman Numeral analysis on the reference datasets. In addition, we investigate variants of our model using proposed techniques such as NADE, and post-processing of the chord predictions. The full source code for this work is available at https://github.com/manoskary/chordgnn