 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Musically Informed Evaluation of Piano Transcription Models
Jun 12, 2024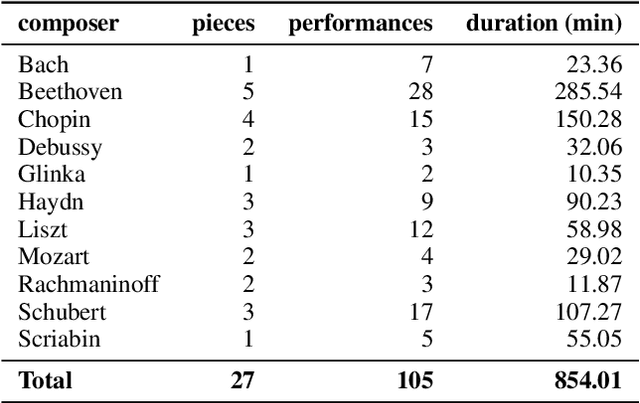
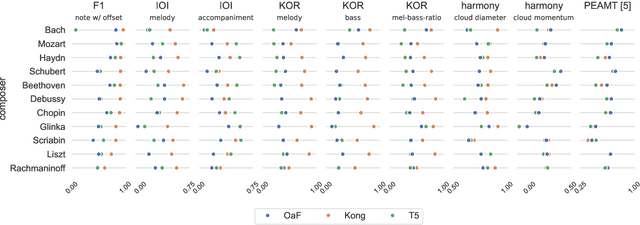
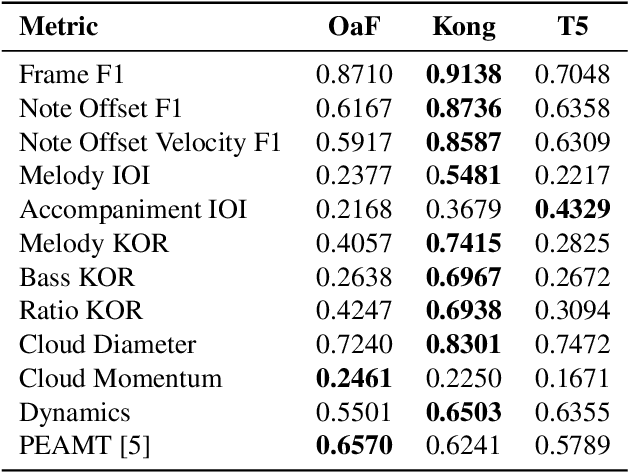
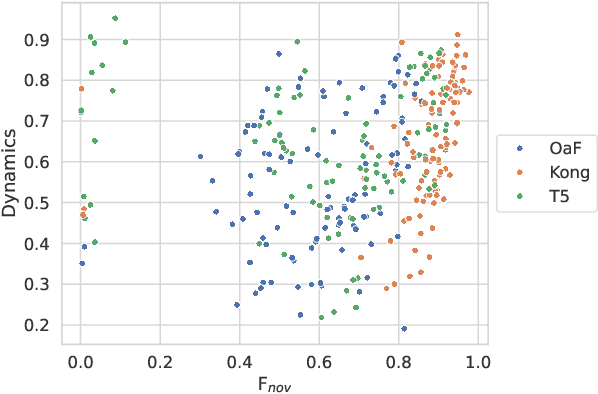
Automatic piano transcription models are typically evaluated using simple frame- or note-wise information retrieval (IR) metrics. Such benchmark metrics do not provide insights into the transcription quality of specific musical aspects such as articulation, dynamics, or rhythmic precision of the output, which are essential in the context of expressive performance analysis. Furthermore, in recent years, MAESTRO has become the de-facto training and evaluation dataset for such models. However, inference performance has been observed to deteriorate substantially when applied on out-of-distribution data, thereby questioning the suitability and reliability of transcribed outputs from such models for specific MIR tasks. In this work, we investigate the performance of three state-of-the-art piano transcription models in two experiments. In the first one, we propose a variety of musically informed evaluation metrics which, in contrast to the IR metrics, offer more detailed insight into the musical quality of the transcriptions. In the second experiment, we compare inference performance on real-world and perturbed audio recordings, and highlight musical dimensions which our metrics can help explain. Our experimental results highlight the weaknesses of existing piano transcription metrics and contribute to a more musically sound error analysis of transcription outputs.
The ACCompanion: Combining Reactivity, Robustness, and Musical Expressivity in an Automatic Piano Accompanist
Apr 24, 2023This paper introduces the ACCompanion, an expressive accompaniment system. Similarly to a musician who accompanies a soloist playing a given musical piece, our system can produce a human-like rendition of the accompaniment part that follows the soloist's choices in terms of tempo, dynamics, and articulation. The ACCompanion works in the symbolic domain, i.e., it needs a musical instrument capable of producing and playing MIDI data, with explicitly encoded onset, offset, and pitch for each played note. We describe the components that go into such a system, from real-time score following and prediction to expressive performance generation and online adaptation to the expressive choices of the human player. Based on our experience with repeated live demonstrations in front of various audiences, we offer an analysis of the challenges of combining these components into a system that is highly reactive and precise, while still a reliable musical partner, robust to possible performance errors and responsive to expressive variations.
The match file format: Encoding Alignments between Scores and Performances
Jun 02, 2022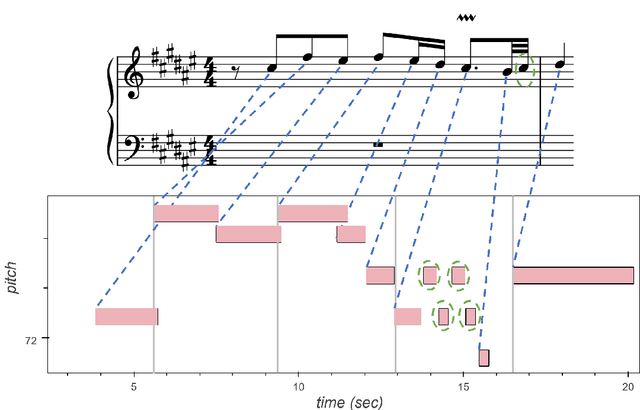


This paper presents the specifications of match: a file format that extends a MIDI human performance with note-, beat-, and downbeat-level alignments to a corresponding musical score. This enables advanced analyses of the performance that are relevant for various tasks, such as expressive performance modeling, score following, music transcription, and performer classification. The match file includes a set of score-related descriptors that makes it usable also as a bare-bones score representation. For applications that require the use of structural score elements (e.g., voices, parts, beams, slurs), the match file can be easily combined with the symbolic score. To support the practical application of our work, we release a corrected and upgraded version of the Vienna4x22 dataset of scores and performances aligned with match files.
Partitura: A Python Package for Symbolic Music Processing
Jun 02, 2022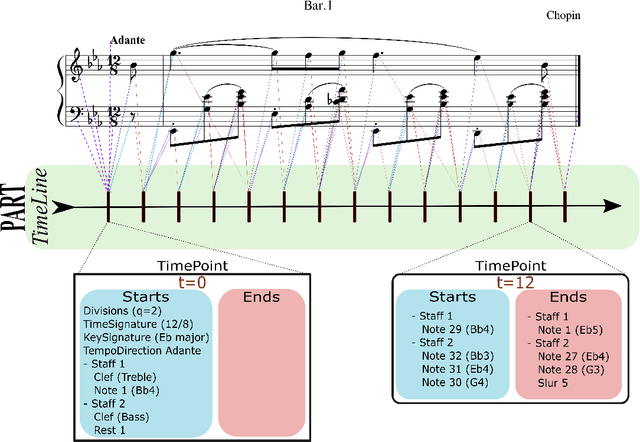

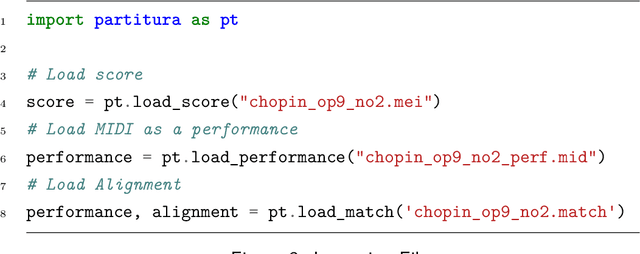
Partitura is a lightweight Python package for handling symbolic musical information. It provides easy access to features commonly used in music information retrieval tasks, like note arrays (lists of timed pitched events) and 2D piano roll matrices, as well as other score elements such as time and key signatures, performance directives, and repeat structures. Partitura can load musical scores (in MEI, MusicXML, Kern, and MIDI formats), MIDI performances, and score-to-performance alignments. The package includes some tools for music analysis, such as automatic pitch spelling, key signature identification, and voice separation. Partitura is an open-source project and is available at https://github.com/CPJKU/partitura/.
Beyond synchronization: Body gestures and gaze direction in duo performance
Jan 31, 2022In this chapter, we focus on two main categories of visual interaction: body gestures and gaze direction. Our focus on body gestures is motivated by research showing that gesture patterns often change during joint action tasks to become more predictable (van der Wel et al., 2016). Moreover, coordination sometimes emerges between musicians at the level of body sway (Chang et al., 2017). Our focus on gaze direction was motivated by the fact that gaze can serve simultaneously as a means of obtaining information about the world and as a means of communicating one's own attention and intent.
partitura: A Python Package for Handling Symbolic Musical Data
Jan 31, 2022This demo paper introduces partitura, a Python package for handling symbolic musical information. The principal aim of this package is to handle richly structured musical information as conveyed by modern staff music notation. It provides a much wider range of possibilities to deal with music than the more reductive (but very common) piano roll-oriented approach inspired by the MIDI standard. The package is an open source project and is available on GitHub.
A Convolutional Approach to Melody Line Identification in Symbolic Scores
Jun 24, 2019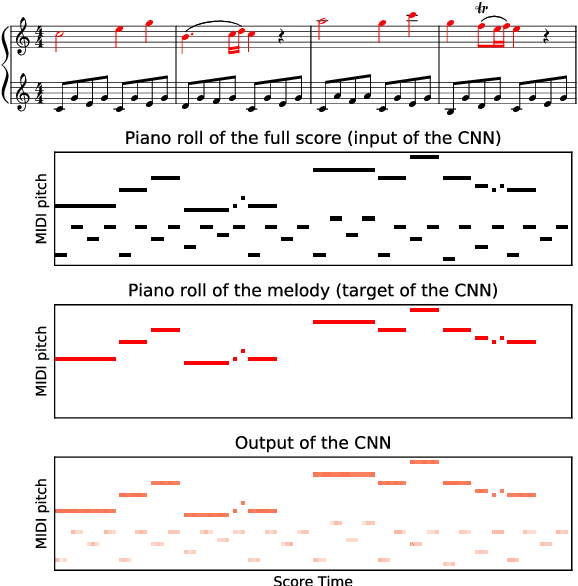


In many musical traditions, the melody line is of primary significance in a piece. Human listeners can readily distinguish melodies from accompaniment; however, making this distinction given only the written score -- i.e. without listening to the music performed -- can be a difficult task. Solving this task is of great importance for both Music Information Retrieval and musicological applications. In this paper, we propose an automated approach to identifying the most salient melody line in a symbolic score. The backbone of the method consists of a convolutional neural network (CNN) estimating the probability that each note in the score (more precisely: each pixel in a piano roll encoding of the score) belongs to the melody line. We train and evaluate the method on various datasets, using manual annotations where available and solo instrument parts where not. We also propose a method to inspect the CNN and to analyze the influence exerted by notes on the prediction of other notes; this method can be applied whenever the output of a neural network has the same size as the input.
User Curated Shaping of Expressive Performances
Jun 14, 2019
Musicians produce individualized, expressive performances by manipulating parameters such as dynamics, tempo and articulation. This manipulation of expressive parameters is informed by elements of score information such as pitch, meter, and tempo and dynamics markings (among others). In this paper we present an interactive interface that gives users the opportunity to explore the relationship between structural elements of a score and expressive parameters. This interface draws on the basis function models, a data-driven framework for expressive performance. In this framework, expressive parameters are modeled as a function of score features, i.e., numerical encodings of specific aspects of a musical score, using neural networks. With the proposed interface, users are able to weight the contribution of individual score features and understand how an expressive performance is constructed.
What were you expecting? Using Expectancy Features to Predict Expressive Performances of Classical Piano Music
Sep 11, 2017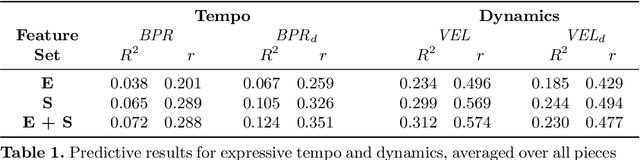
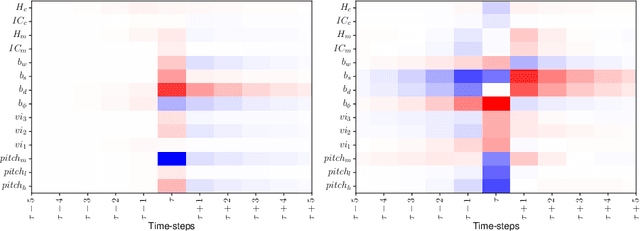
In this paper we present preliminary work examining the relationship between the formation of expectations and the realization of musical performances, paying particular attention to expressive tempo and dynamics. To compute features that reflect what a listener is expecting to hear, we employ a computational model of auditory expectation called the Information Dynamics of Music model (IDyOM). We then explore how well these expectancy features -- when combined with score descriptors using the Basis-Function modeling approach -- can predict expressive tempo and dynamics in a dataset of Mozart piano sonata performances. Our results suggest that using expectancy features significantly improves the predictions for tempo.
From Bach to the Beatles: The simulation of human tonal expectation using ecologically-trained predictive models
Jul 19, 2017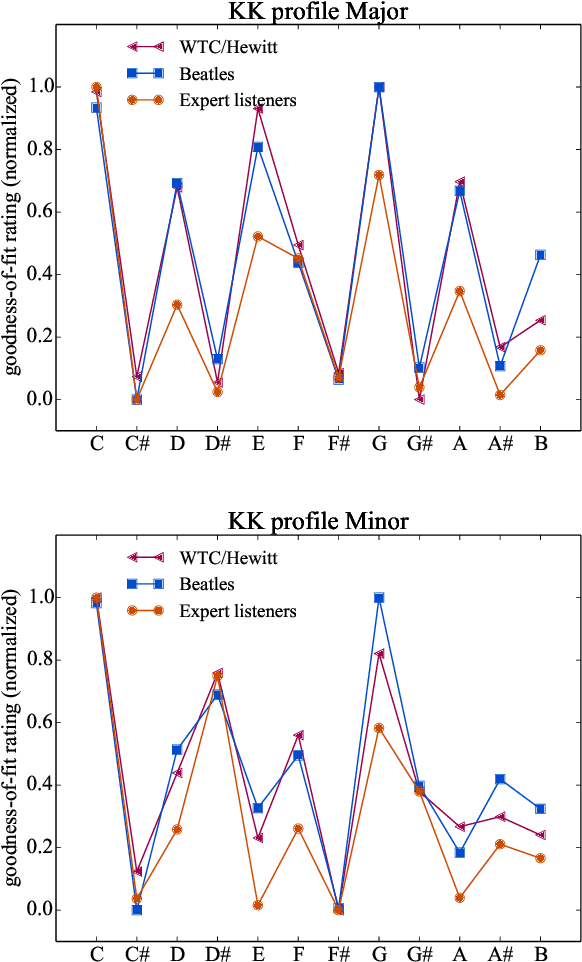

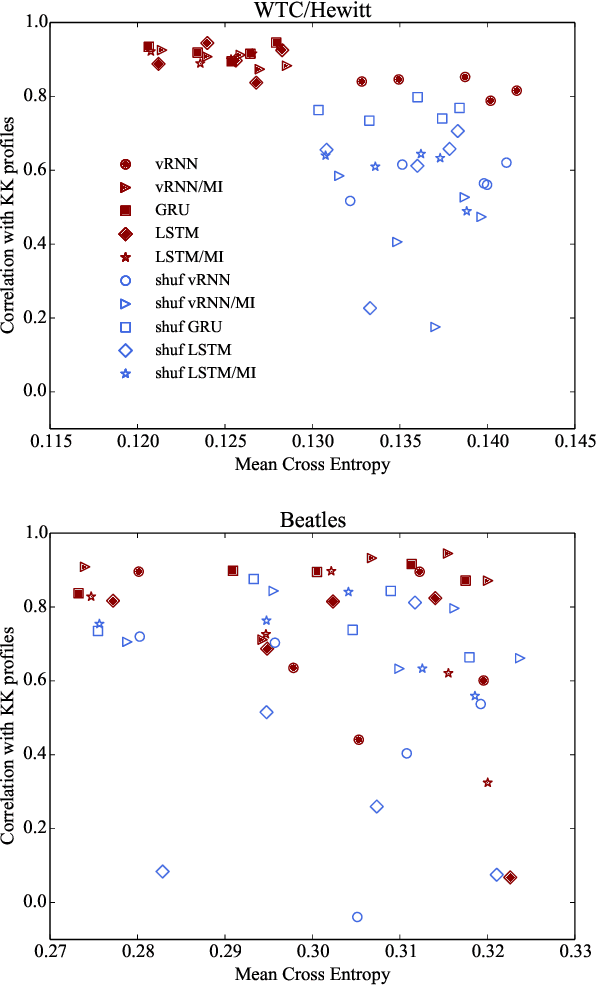
Tonal structure is in part conveyed by statistical regularities between musical events, and research has shown that computational models reflect tonal structure in music by capturing these regularities in schematic constructs like pitch histograms. Of the few studies that model the acquisition of perceptual learning from musical data, most have employed self-organizing models that learn a topology of static descriptions of musical contexts. Also, the stimuli used to train these models are often symbolic rather than acoustically faithful representations of musical material. In this work we investigate whether sequential predictive models of musical memory (specifically, recurrent neural networks), trained on audio from commercial CD recordings, induce tonal knowledge in a similar manner to listeners (as shown in behavioral studies in music perception). Our experiments indicate that various types of recurrent neural networks produce musical expectations that clearly convey tonal structure. Furthermore, the results imply that although implicit knowledge of tonal structure is a necessary condition for accurate musical expectation, the most accurate predictive models also use other cues beyond the tonal structure of the musical context.