 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Performance-Complexity Trade-Offs in Sound Event Detection
Mar 14, 2025We target the problem of developing new low-complexity networks for the sound event detection task. Our goal is to meticulously analyze the performance-complexity trade-off, aiming to be competitive with the large state-of-the-art models, at a fraction of the computational requirements. We find that low-complexity convolutional models previously proposed for audio tagging can be effectively adapted for event detection (which requires frame-wise prediction) by adjusting convolutional strides, removing the global pooling, and, importantly, adding a sequence model before the (now frame-wise) classification heads. Systematic experiments reveal that the best choice for the sequence model type depends on which complexity metric is most important for the given application. We also investigate the impact of enhanced training strategies such as knowledge distillation. In the end, we show that combined with an optimized training strategy, we can reach event detection performance comparable to state-of-the-art transformers while requiring only around 5% of the parameters. We release all our pre-trained models and the code for reproducing this work to support future research in low-complexity sound event detection at https://github.com/theMoro/EfficientSED.
Effective Pre-Training of Audio Transformers for Sound Event Detection
Sep 14, 2024


We propose a pre-training pipeline for audio spectrogram transformers for frame-level sound event detection tasks. On top of common pre-training steps, we add a meticulously designed training routine on AudioSet frame-level annotations. This includes a balanced sampler, aggressive data augmentation, and ensemble knowledge distillation. For five transformers, we obtain a substantial performance improvement over previously available checkpoints both on AudioSet frame-level predictions and on frame-level sound event detection downstream tasks, confirming our pipeline's effectiveness. We publish the resulting checkpoints that researchers can directly fine-tune to build high-performance models for sound event detection tasks.
Beat this! Accurate beat tracking without DBN postprocessing
Jul 31, 2024



We propose a system for tracking beats and downbeats with two objectives: generality across a diverse music range, and high accuracy. We achieve generality by training on multiple datasets -- including solo instrument recordings, pieces with time signature changes, and classical music with high tempo variations -- and by removing the commonly used Dynamic Bayesian Network (DBN) postprocessing, which introduces constraints on the meter and tempo. For high accuracy, among other improvements, we develop a loss function tolerant to small time shifts of annotations, and an architecture alternating convolutions with transformers either over frequency or time. Our system surpasses the current state of the art in F1 score despite using no DBN. However, it can still fail, especially for difficult and underrepresented genres, and performs worse on continuity metrics, so we publish our model, code, and preprocessed datasets, and invite others to beat this.
Perception-Inspired Graph Convolution for Music Understanding Tasks
May 15, 2024



We propose a new graph convolutional block, called MusGConv, specifically designed for the efficient processing of musical score data and motivated by general perceptual principles. It focuses on two fundamental dimensions of music, pitch and rhythm, and considers both relative and absolute representations of these components. We evaluate our approach on four different musical understanding problems: monophonic voice separation, harmonic analysis, cadence detection, and composer identification which, in abstract terms, translate to different graph learning problems, namely, node classification, link prediction, and graph classification. Our experiments demonstrate that MusGConv improves the performance on three of the aforementioned tasks while being conceptually very simple and efficient. We interpret this as evidence that it is beneficial to include perception-informed processing of fundamental musical concepts when developing graph network applications on musical score data.
SMUG-Explain: A Framework for Symbolic Music Graph Explanations
May 15, 2024In this work, we present Score MUsic Graph (SMUG)-Explain, a framework for generating and visualizing explanations of graph neural networks applied to arbitrary prediction tasks on musical scores. Our system allows the user to visualize the contribution of input notes (and note features) to the network output, directly in the context of the musical score. We provide an interactive interface based on the music notation engraving library Verovio. We showcase the usage of SMUG-Explain on the task of cadence detection in classical music. All code is available on https://github.com/manoskary/SMUG-Explain.
8+8=4: Formalizing Time Units to Handle Symbolic Music Durations
Oct 23, 2023This paper focuses on the nominal durations of musical events (notes and rests) in a symbolic musical score, and on how to conveniently handle these in computer applications. We propose the usage of a temporal unit that is directly related to the graphical symbols in musical scores and pair this with a set of operations that cover typical computations in music applications. We formalize this time unit and the more commonly used approach in a single mathematical framework, as semirings, algebraic structures that enable an abstract description of algorithms/processing pipelines. We then discuss some practical use cases and highlight when our system can improve such pipelines by making them more efficient in terms of data type used and the number of computations.
Predicting Music Hierarchies with a Graph-Based Neural Decoder
Jun 29, 2023



This paper describes a data-driven framework to parse musical sequences into dependency trees, which are hierarchical structures used in music cognition research and music analysis. The parsing involves two steps. First, the input sequence is passed through a transformer encoder to enrich it with contextual information. Then, a classifier filters the graph of all possible dependency arcs to produce the dependency tree. One major benefit of this system is that it can be easily integrated into modern deep-learning pipelines. Moreover, since it does not rely on any particular symbolic grammar, it can consider multiple musical features simultaneously, make use of sequential context information, and produce partial results for noisy inputs. We test our approach on two datasets of musical trees -- time-span trees of monophonic note sequences and harmonic trees of jazz chord sequences -- and show that our approach outperforms previous methods.
Musical Voice Separation as Link Prediction: Modeling a Musical Perception Task as a Multi-Trajectory Tracking Problem
Apr 28, 2023


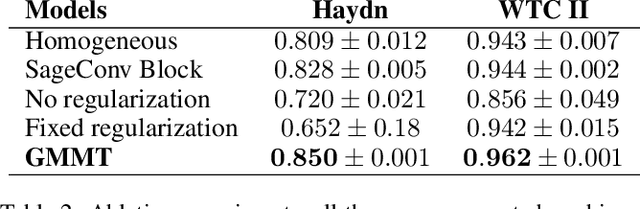
This paper targets the perceptual task of separating the different interacting voices, i.e., monophonic melodic streams, in a polyphonic musical piece. We target symbolic music, where notes are explicitly encoded, and model this task as a Multi-Trajectory Tracking (MTT) problem from discrete observations, i.e., notes in a pitch-time space. Our approach builds a graph from a musical piece, by creating one node for every note, and separates the melodic trajectories by predicting a link between two notes if they are consecutive in the same voice/stream. This kind of local, greedy prediction is made possible by node embeddings created by a heterogeneous graph neural network that can capture inter- and intra-trajectory information. Furthermore, we propose a new regularization loss that encourages the output to respect the MTT premise of at most one incoming and one outgoing link for every node, favouring monophonic (voice) trajectories; this loss function might also be useful in other general MTT scenarios. Our approach does not use domain-specific heuristics, is scalable to longer sequences and a higher number of voices, and can handle complex cases such as voice inversions and overlaps. We reach new state-of-the-art results for the voice separation task in classical music of different styles.
The ACCompanion: Combining Reactivity, Robustness, and Musical Expressivity in an Automatic Piano Accompanist
Apr 24, 2023This paper introduces the ACCompanion, an expressive accompaniment system. Similarly to a musician who accompanies a soloist playing a given musical piece, our system can produce a human-like rendition of the accompaniment part that follows the soloist's choices in terms of tempo, dynamics, and articulation. The ACCompanion works in the symbolic domain, i.e., it needs a musical instrument capable of producing and playing MIDI data, with explicitly encoded onset, offset, and pitch for each played note. We describe the components that go into such a system, from real-time score following and prediction to expressive performance generation and online adaptation to the expressive choices of the human player. Based on our experience with repeated live demonstrations in front of various audiences, we offer an analysis of the challenges of combining these components into a system that is highly reactive and precise, while still a reliable musical partner, robust to possible performance errors and responsive to expressive variations.
Concept-Based Techniques for "Musicologist-friendly" Explanations in a Deep Music Classifier
Aug 29, 2022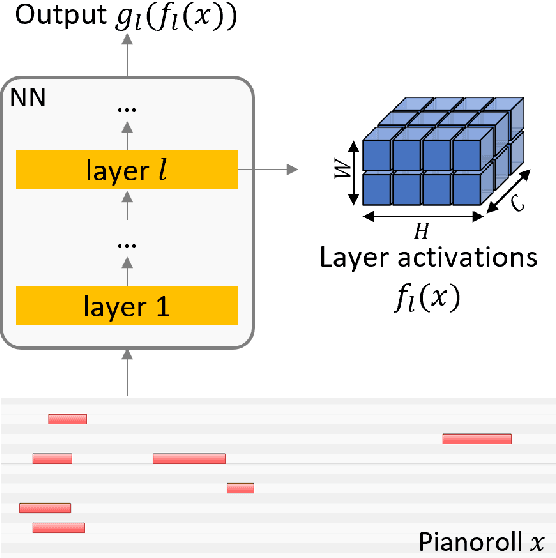

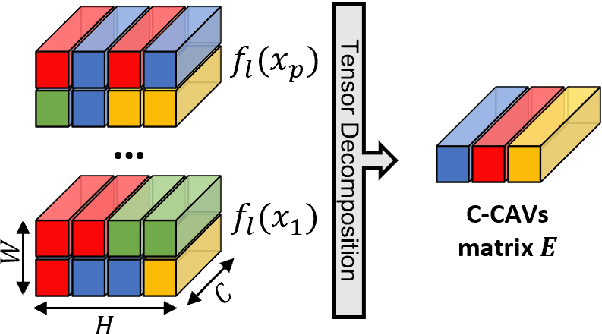
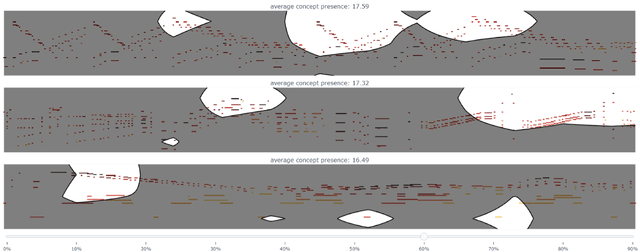
Current approaches for explaining deep learning systems applied to musical data provide results in a low-level feature space, e.g., by highlighting potentially relevant time-frequency bins in a spectrogram or time-pitch bins in a piano roll. This can be difficult to understand, particularly for musicologists without technical knowledge. To address this issue, we focus on more human-friendly explanations based on high-level musical concepts. Our research targets trained systems (post-hoc explanations) and explores two approaches: a supervised one, where the user can define a musical concept and test if it is relevant to the system; and an unsupervised one, where musical excerpts containing relevant concepts are automatically selected and given to the user for interpretation. We demonstrate both techniques on an existing symbolic composer classification system, showcase their potential, and highlight their intrinsic limitations.