 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Event Detection with Boundary-Aware Optimization and Inference
Jan 07, 2026Temporal detection problems appear in many fields including time-series estimation, activity recognition and sound event detection (SED). In this work, we propose a new approach to temporal event modeling by explicitly modeling event onsets and offsets, and by introducing boundary-aware optimization and inference strategies that substantially enhance temporal event detection. The presented methodology incorporates new temporal modeling layers - Recurrent Event Detection (RED) and Event Proposal Network (EPN) - which, together with tailored loss functions, enable more effective and precise temporal event detection. We evaluate the proposed method in the SED domain using a subset of the temporally-strongly annotated portion of AudioSet. Experimental results show that our approach not only outperforms traditional frame-wise SED models with state-of-the-art post-processing, but also removes the need for post-processing hyperparameter tuning, and scales to achieve new state-of-the-art performance across all AudioSet Strong classes.
On Temporal Guidance and Iterative Refinement in Audio Source Separation
Jul 23, 2025Spatial semantic segmentation of sound scenes (S5) involves the accurate identification of active sound classes and the precise separation of their sources from complex acoustic mixtures. Conventional systems rely on a two-stage pipeline - audio tagging followed by label-conditioned source separation - but are often constrained by the absence of fine-grained temporal information critical for effective separation. In this work, we address this limitation by introducing a novel approach for S5 that enhances the synergy between the event detection and source separation stages. Our key contributions are threefold. First, we fine-tune a pre-trained Transformer to detect active sound classes. Second, we utilize a separate instance of this fine-tuned Transformer to perform sound event detection (SED), providing the separation module with detailed, time-varying guidance. Third, we implement an iterative refinement mechanism that progressively enhances separation quality by recursively reusing the separator's output from previous iterations. These advancements lead to significant improvements in both audio tagging and source separation performance, as demonstrated by our system's second-place finish in Task 4 of the DCASE Challenge 2025. Our implementation and model checkpoints are available in our GitHub repository: https://github.com/theMoro/dcase25task4 .
TACOS: Temporally-aligned Audio CaptiOnS for Language-Audio Pretraining
May 12, 2025Learning to associate audio with textual descriptions is valuable for a range of tasks, including pretraining, zero-shot classification, audio retrieval, audio captioning, and text-conditioned audio generation. Existing contrastive language-audio pretrained models are typically trained using global, clip-level descriptions, which provide only weak temporal supervision. We hypothesize that CLAP-like language-audio models - particularly, if they are expected to produce frame-level embeddings - can benefit from a stronger temporal supervision. To confirm our hypothesis, we curate a novel dataset of approximately 12,000 audio recordings from Freesound, each annotated with single-sentence free-text descriptions linked to a specific temporal segment in an audio recording. We use large language models to clean these annotations by removing references to non-audible events, transcribed speech, typos, and annotator language bias. We further propose a frame-wise contrastive training strategy that learns to align text descriptions with temporal regions in an audio recording and demonstrate that our model has better temporal text-audio alignment abilities compared to models trained only on global captions when evaluated on the AudioSet Strong benchmark. The dataset and our source code are available on Zenodo and GitHub, respectively.
Exploring Performance-Complexity Trade-Offs in Sound Event Detection
Mar 14, 2025We target the problem of developing new low-complexity networks for the sound event detection task. Our goal is to meticulously analyze the performance-complexity trade-off, aiming to be competitive with the large state-of-the-art models, at a fraction of the computational requirements. We find that low-complexity convolutional models previously proposed for audio tagging can be effectively adapted for event detection (which requires frame-wise prediction) by adjusting convolutional strides, removing the global pooling, and, importantly, adding a sequence model before the (now frame-wise) classification heads. Systematic experiments reveal that the best choice for the sequence model type depends on which complexity metric is most important for the given application. We also investigate the impact of enhanced training strategies such as knowledge distillation. In the end, we show that combined with an optimized training strategy, we can reach event detection performance comparable to state-of-the-art transformers while requiring only around 5% of the parameters. We release all our pre-trained models and the code for reproducing this work to support future research in low-complexity sound event detection at https://github.com/theMoro/EfficientSED.
Creating a Good Teacher for Knowledge Distillation in Acoustic Scene Classification
Mar 14, 2025Knowledge Distillation (KD) is a widespread technique for compressing the knowledge of large models into more compact and efficient models. KD has proved to be highly effective in building well-performing low-complexity Acoustic Scene Classification (ASC) systems and was used in all the top-ranked submissions to this task of the annual DCASE challenge in the past three years. There is extensive research available on establishing the KD process, designing efficient student models, and forming well-performing teacher ensembles. However, less research has been conducted on investigating which teacher model attributes are beneficial for low-complexity students. In this work, we try to close this gap by studying the effects on the student's performance when using different teacher network architectures, varying the teacher model size, training them with different device generalization methods, and applying different ensembling strategies. The results show that teacher model sizes, device generalization methods, the ensembling strategy and the ensemble size are key factors for a well-performing student network.
Effective Pre-Training of Audio Transformers for Sound Event Detection
Sep 14, 2024


We propose a pre-training pipeline for audio spectrogram transformers for frame-level sound event detection tasks. On top of common pre-training steps, we add a meticulously designed training routine on AudioSet frame-level annotations. This includes a balanced sampler, aggressive data augmentation, and ensemble knowledge distillation. For five transformers, we obtain a substantial performance improvement over previously available checkpoints both on AudioSet frame-level predictions and on frame-level sound event detection downstream tasks, confirming our pipeline's effectiveness. We publish the resulting checkpoints that researchers can directly fine-tune to build high-performance models for sound event detection tasks.
Improving Query-by-Vocal Imitation with Contrastive Learning and Audio Pretraining
Aug 21, 2024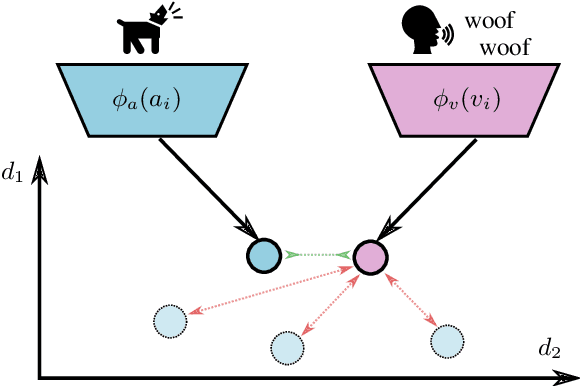



Query-by-Vocal Imitation (QBV) is about searching audio files within databases using vocal imitations created by the user's voice. Since most humans can effectively communicate sound concepts through voice, QBV offers the more intuitive and convenient approach compared to text-based search. To fully leverage QBV, developing robust audio feature representations for both the vocal imitation and the original sound is crucial. In this paper, we present a new system for QBV that utilizes the feature extraction capabilities of Convolutional Neural Networks pre-trained with large-scale general-purpose audio datasets. We integrate these pre-trained models into a dual encoder architecture and fine-tune them end-to-end using contrastive learning. A distinctive aspect of our proposed method is the fine-tuning strategy of pre-trained models using an adapted NT-Xent loss for contrastive learning, creating a shared embedding space for reference recordings and vocal imitations. The proposed system significantly enhances audio retrieval performance, establishing a new state of the art on both coarse- and fine-grained QBV tasks.
Estimated Audio-Caption Correspondences Improve Language-Based Audio Retrieval
Aug 21, 2024Dual-encoder-based audio retrieval systems are commonly optimized with contrastive learning on a set of matching and mismatching audio-caption pairs. This leads to a shared embedding space in which corresponding items from the two modalities end up close together. Since audio-caption datasets typically only contain matching pairs of recordings and descriptions, it has become common practice to create mismatching pairs by pairing the audio with a caption randomly drawn from the dataset. This is not ideal because the randomly sampled caption could, just by chance, partly or entirely describe the audio recording. However, correspondence information for all possible pairs is costly to annotate and thus typically unavailable; we, therefore, suggest substituting it with estimated correspondences. To this end, we propose a two-staged training procedure in which multiple retrieval models are first trained as usual, i.e., without estimated correspondences. In the second stage, the audio-caption correspondences predicted by these models then serve as prediction targets. We evaluate our method on the ClothoV2 and the AudioCaps benchmark and show that it improves retrieval performance, even in a restricting self-distillation setting where a single model generates and then learns from the estimated correspondences. We further show that our method outperforms the current state of the art by 1.6 pp. mAP@10 on the ClothoV2 benchmark.
Multi-Iteration Multi-Stage Fine-Tuning of Transformers for Sound Event Detection with Heterogeneous Datasets
Jul 17, 2024A central problem in building effective sound event detection systems is the lack of high-quality, strongly annotated sound event datasets. For this reason, Task 4 of the DCASE 2024 challenge proposes learning from two heterogeneous datasets, including audio clips labeled with varying annotation granularity and with different sets of possible events. We propose a multi-iteration, multi-stage procedure for fine-tuning Audio Spectrogram Transformers on the joint DESED and MAESTRO Real datasets. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, achieving a new single-model, state-of-the-art performance on the public evaluation set of DESED with a PSDS1 of 0.692. A single model and an ensemble, both based on our proposed training procedure, ranked first in Task 4 of the DCASE Challenge 2024.
Data-Efficient Low-Complexity Acoustic Scene Classification in the DCASE 2024 Challenge
May 16, 2024

This article describes the Data-Efficient Low-Complexity Acoustic Scene Classification Task in the DCASE 2024 Challenge and the corresponding baseline system. The task setup is a continuation of previous editions (2022 and 2023), which focused on recording device mismatches and low-complexity constraints. This year's edition introduces an additional real-world problem: participants must develop data-efficient systems for five scenarios, which progressively limit the available training data. The provided baseline system is based on an efficient, factorized CNN architecture constructed from inverted residual blocks and uses Freq-MixStyle to tackle the device mismatch problem. The baseline system's accuracy ranges from 42.40% on the smallest to 56.99% on the largest training set.