 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoosh: A Sound Effects Foundation Model
Apr 02, 2026The audio research community depends on open generative models as foundational tools for building novel approaches and establishing baselines. In this report, we present Woosh, Sony AI's publicly released sound effect foundation model, detailing its architecture, training process, and an evaluation against other popular open models. Being optimized for sound effects, we provide (1) a high-quality audio encoder/decoder model and (2) a text-audio alignment model for conditioning, together with (3) text-to-audio and (4) video-to-audio generative models. Distilled text-to-audio and video-to-audio models are also included in the release, allowing for low-resource operation and fast inference. Our evaluation on both public and private data shows competitive or better performance for each module when compared to existing open alternatives like StableAudio-Open and TangoFlux. Inference code and model weights are available at https://github.com/SonyResearch/Woosh. Demo samples can be found at https://sonyresearch.github.io/Woosh/.
Creating a Good Teacher for Knowledge Distillation in Acoustic Scene Classification
Mar 14, 2025Knowledge Distillation (KD) is a widespread technique for compressing the knowledge of large models into more compact and efficient models. KD has proved to be highly effective in building well-performing low-complexity Acoustic Scene Classification (ASC) systems and was used in all the top-ranked submissions to this task of the annual DCASE challenge in the past three years. There is extensive research available on establishing the KD process, designing efficient student models, and forming well-performing teacher ensembles. However, less research has been conducted on investigating which teacher model attributes are beneficial for low-complexity students. In this work, we try to close this gap by studying the effects on the student's performance when using different teacher network architectures, varying the teacher model size, training them with different device generalization methods, and applying different ensembling strategies. The results show that teacher model sizes, device generalization methods, the ensembling strategy and the ensemble size are key factors for a well-performing student network.
Data-Efficient Low-Complexity Acoustic Scene Classification in the DCASE 2024 Challenge
May 16, 2024

This article describes the Data-Efficient Low-Complexity Acoustic Scene Classification Task in the DCASE 2024 Challenge and the corresponding baseline system. The task setup is a continuation of previous editions (2022 and 2023), which focused on recording device mismatches and low-complexity constraints. This year's edition introduces an additional real-world problem: participants must develop data-efficient systems for five scenarios, which progressively limit the available training data. The provided baseline system is based on an efficient, factorized CNN architecture constructed from inverted residual blocks and uses Freq-MixStyle to tackle the device mismatch problem. The baseline system's accuracy ranges from 42.40% on the smallest to 56.99% on the largest training set.
Dynamic Convolutional Neural Networks as Efficient Pre-trained Audio Models
Oct 24, 2023The introduction of large-scale audio datasets, such as AudioSet, paved the way for Transformers to conquer the audio domain and replace CNNs as the state-of-the-art neural network architecture for many tasks. Audio Spectrogram Transformers are excellent at exploiting large datasets, creating powerful pre-trained models that surpass CNNs when fine-tuned on downstream tasks. However, current popular Audio Spectrogram Transformers are demanding in terms of computational complexity compared to CNNs. Recently, we have shown that, by employing Transformer-to-CNN Knowledge Distillation, efficient CNNs can catch up with and even outperform Transformers on large datasets. In this work, we extend this line of research and increase the capacity of efficient CNNs by introducing dynamic CNN blocks, constructed of dynamic non-linearities, dynamic convolutions and attention mechanisms. We show that these dynamic CNNs outperform traditional efficient CNNs, in terms of the performance-complexity trade-off and parameter efficiency, at the task of audio tagging on the large-scale AudioSet. Our experiments further indicate that the introduced dynamic CNNs achieve better performance on downstream tasks and scale up well, attaining Transformer performance and even outperforming them on AudioSet and several downstream tasks.
Advancing Natural-Language Based Audio Retrieval with PaSST and Large Audio-Caption Data Sets
Aug 08, 2023This work presents a text-to-audio-retrieval system based on pre-trained text and spectrogram transformers. Our method projects recordings and textual descriptions into a shared audio-caption space in which related examples from different modalities are close. Through a systematic analysis, we examine how each component of the system influences retrieval performance. As a result, we identify two key components that play a crucial role in driving performance: the self-attention-based audio encoder for audio embedding and the utilization of additional human-generated and synthetic data sets during pre-training. We further experimented with augmenting ClothoV2 captions with available keywords to increase their variety; however, this only led to marginal improvements. Our system ranked first in the 2023's DCASE Challenge, and it outperforms the current state of the art on the ClothoV2 benchmark by 5.6 pp. mAP@10.
Domain Information Control at Inference Time for Acoustic Scene Classification
Jun 13, 2023Domain shift is considered a challenge in machine learning as it causes significant degradation of model performance. In the Acoustic Scene Classification task (ASC), domain shift is mainly caused by different recording devices. Several studies have already targeted domain generalization to improve the performance of ASC models on unseen domains, such as new devices. Recently, the Controllable Gate Adapter ConGater has been proposed in Natural Language Processing to address the biased training data problem. ConGater allows controlling the debiasing process at inference time. ConGater's main advantage is the continuous and selective debiasing of a trained model, during inference. In this work, we adapt ConGater to the audio spectrogram transformer for an acoustic scene classification task. We show that ConGater can be used to selectively adapt the learned representations to be invariant to device domain shifts such as recording devices. Our analysis shows that ConGater can progressively remove device information from the learned representations and improve the model generalization, especially under domain shift conditions (e.g. unseen devices). We show that information removal can be extended to both device and location domain. Finally, we demonstrate ConGater's ability to enhance specific device performance without further training.
Device-Robust Acoustic Scene Classification via Impulse Response Augmentation
May 12, 2023The ability to generalize to a wide range of recording devices is a crucial performance factor for audio classification models. The characteristics of different types of microphones introduce distributional shifts in the digitized audio signals due to their varying frequency responses. If this domain shift is not taken into account during training, the model's performance could degrade severely when it is applied to signals recorded by unseen devices. In particular, training a model on audio signals recorded with a small number of different microphones can make generalization to unseen devices difficult. To tackle this problem, we convolve audio signals in the training set with pre-recorded device impulse responses (DIRs) to artificially increase the diversity of recording devices. We systematically study the effect of DIR augmentation on the task of Acoustic Scene Classification using CNNs and Audio Spectrogram Transformers. The results show that DIR augmentation in isolation performs similarly to the state-of-the-art method Freq-MixStyle. However, we also show that DIR augmentation and Freq-MixStyle are complementary, achieving a new state-of-the-art performance on signals recorded by devices unseen during training.
Low-Complexity Audio Embedding Extractors
Mar 03, 2023Solving tasks such as speaker recognition, music classification, or semantic audio event tagging with deep learning models typically requires computationally demanding networks. General-purpose audio embeddings (GPAEs) are dense representations of audio signals that allow lightweight, shallow classifiers to tackle various audio tasks. The idea is that a single complex feature extractor would extract dense GPAEs, while shallow MLPs can produce task-specific predictions. If the extracted dense representations are general enough to allow the simple downstream classifiers to generalize to a variety of tasks in the audio domain, a single costly forward pass suffices to solve multiple tasks in parallel. In this work, we try to reduce the cost of GPAE extractors to make them suitable for resource-constrained devices. We use efficient MobileNets trained on AudioSet using Knowledge Distillation from a Transformer ensemble as efficient GPAE extractors. We explore how to obtain high-quality GPAEs from the model, study how model complexity relates to the quality of extracted GPAEs, and conclude that low-complexity models can generate competitive GPAEs, paving the way for analyzing audio streams on edge devices w.r.t. multiple audio classification and recognition tasks.
Learning General Audio Representations with Large-Scale Training of Patchout Audio Transformers
Nov 25, 2022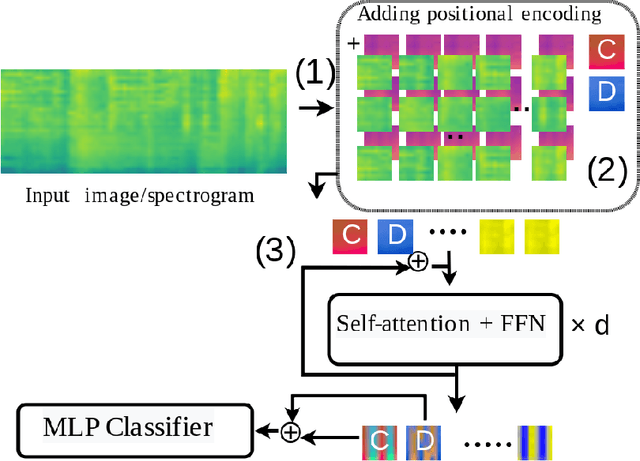


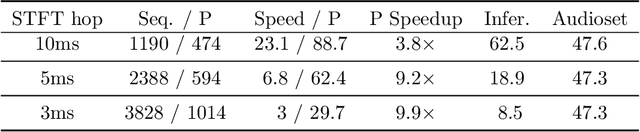
The success of supervised deep learning methods is largely due to their ability to learn relevant features from raw data. Deep Neural Networks (DNNs) trained on large-scale datasets are capable of capturing a diverse set of features, and learning a representation that can generalize onto unseen tasks and datasets that are from the same domain. Hence, these models can be used as powerful feature extractors, in combination with shallower models as classifiers, for smaller tasks and datasets where the amount of training data is insufficient for learning an end-to-end model from scratch. During the past years, Convolutional Neural Networks (CNNs) have largely been the method of choice for audio processing. However, recently attention-based transformer models have demonstrated great potential in supervised settings, outperforming CNNs. In this work, we investigate the use of audio transformers trained on large-scale datasets to learn general-purpose representations. We study how the different setups in these audio transformers affect the quality of their embeddings. We experiment with the models' time resolution, extracted embedding level, and receptive fields in order to see how they affect performance on a variety of tasks and datasets, following the HEAR 2021 NeurIPS challenge evaluation setup. Our results show that representations extracted by audio transformers outperform CNN representations. Furthermore, we will show that transformers trained on Audioset can be extremely effective representation extractors for a wide range of downstream tasks.
Efficient Large-scale Audio Tagging via Transformer-to-CNN Knowledge Distillation
Nov 09, 2022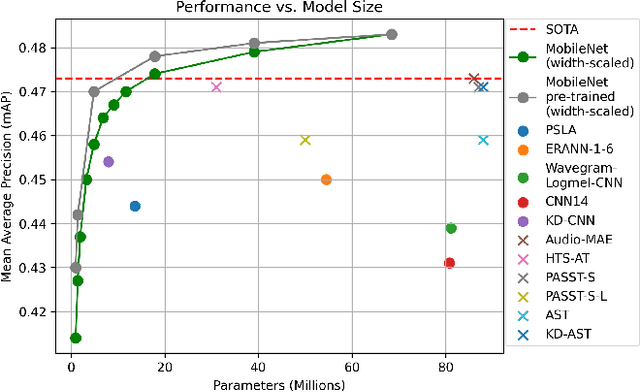



Audio Spectrogram Transformer models rule the field of Audio Tagging, outrunning previously dominating Convolutional Neural Networks (CNNs). Their superiority is based on the ability to scale up and exploit large-scale datasets such as AudioSet. However, Transformers are demanding in terms of model size and computational requirements compared to CNNs. We propose a training procedure for efficient CNNs based on offline Knowledge Distillation (KD) from high-performing yet complex transformers. The proposed training schema and the efficient CNN design based on MobileNetV3 results in models outperforming previous solutions in terms of parameter and computational efficiency and prediction performance. We provide models of different complexity levels, scaling from low-complexity models up to a new state-of-the-art performance of .483 mAP on AudioSet. Source Code available at: https://github.com/fschmid56/EfficientAT