 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA decade of DCASE: Achievements, practices, evaluations and future challenges
Oct 07, 2024This paper introduces briefly the history and growth of the Detection and Classification of Acoustic Scenes and Events (DCASE) challenge, workshop, research area and research community. Created in 2013 as a data evaluation challenge, DCASE has become a major research topic in the Audio and Acoustic Signal Processing area. Its success comes from a combination of factors: the challenge offers a large variety of tasks that are renewed each year; and the workshop offers a channel for dissemination of related work, engaging a young and dynamic community. At the same time, DCASE faces its own challenges, growing and expanding to different areas. One of the core principles of DCASE is open science and reproducibility: publicly available datasets, baseline systems, technical reports and workshop publications. While the DCASE challenge and workshop are independent of IEEE SPS, the challenge receives annual endorsement from the AASP TC, and the DCASE community contributes significantly to the ICASSP flagship conference and the success of SPS in many of its activities.
Multi-label Zero-Shot Audio Classification with Temporal Attention
Aug 31, 2024Zero-shot learning models are capable of classifying new classes by transferring knowledge from the seen classes using auxiliary information. While most of the existing zero-shot learning methods focused on single-label classification tasks, the present study introduces a method to perform multi-label zero-shot audio classification. To address the challenge of classifying multi-label sounds while generalizing to unseen classes, we adapt temporal attention. The temporal attention mechanism assigns importance weights to different audio segments based on their acoustic and semantic compatibility, thus enabling the model to capture the varying dominance of different sound classes within an audio sample by focusing on the segments most relevant for each class. This leads to more accurate multi-label zero-shot classification than methods employing temporally aggregated acoustic features without weighting, which treat all audio segments equally. We evaluate our approach on a subset of AudioSet against a zero-shot model using uniformly aggregated acoustic features, a zero-rule baseline, and the proposed method in the supervised scenario. Our results show that temporal attention enhances the zero-shot audio classification performance in multi-label scenario.
Data-Efficient Low-Complexity Acoustic Scene Classification in the DCASE 2024 Challenge
May 16, 2024

This article describes the Data-Efficient Low-Complexity Acoustic Scene Classification Task in the DCASE 2024 Challenge and the corresponding baseline system. The task setup is a continuation of previous editions (2022 and 2023), which focused on recording device mismatches and low-complexity constraints. This year's edition introduces an additional real-world problem: participants must develop data-efficient systems for five scenarios, which progressively limit the available training data. The provided baseline system is based on an efficient, factorized CNN architecture constructed from inverted residual blocks and uses Freq-MixStyle to tackle the device mismatch problem. The baseline system's accuracy ranges from 42.40% on the smallest to 56.99% on the largest training set.
Positive and negative sampling strategies for self-supervised learning on audio-video data
Feb 05, 2024


In Self-Supervised Learning (SSL), Audio-Visual Correspondence (AVC) is a popular task to learn deep audio and video features from large unlabeled datasets. The key step in AVC is to randomly sample audio and video clips from the dataset and learn to minimize the feature distance between the positive pairs (corresponding audio-video pair) while maximizing the distance between the negative pairs (non-corresponding audio-video pairs). The learnt features are shown to be effective on various downstream tasks. However, these methods achieve subpar performance when the size of the dataset is rather small. In this paper, we investigate the effect of utilizing class label information in the AVC feature learning task. We modified various positive and negative data sampling techniques of SSL based on class label information to investigate the effect on the feature quality. We propose a new sampling approach which we call soft-positive sampling, where the positive pair for one audio sample is not from the exact corresponding video, but from a video of the same class. Experimental results suggest that when the dataset size is small in SSL setup, features learnt through the soft-positive sampling method significantly outperform those from the traditional SSL sampling approaches. This trend holds in both in-domain and out-of-domain downstream tasks, and even outperforms supervised classification. Finally, experiments show that class label information can easily be obtained using a publicly available classifier network and then can be used to boost the SSL performance without adding extra data annotation burden.
Zero-Shot Audio Classification using Image Embeddings
Jun 10, 2022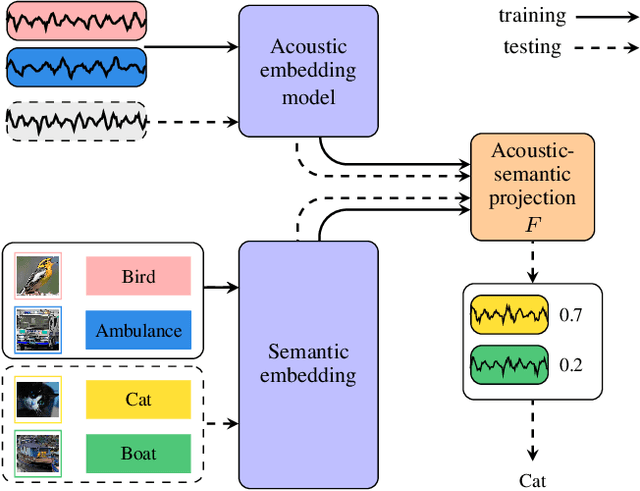
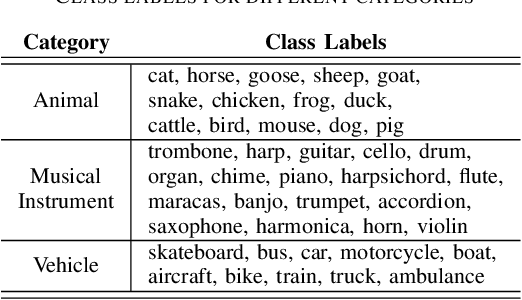
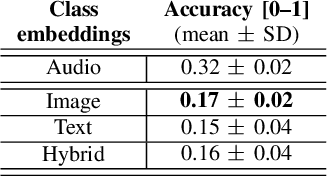
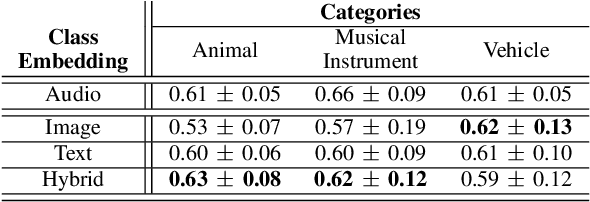
Supervised learning methods can solve the given problem in the presence of a large set of labeled data. However, the acquisition of a dataset covering all the target classes typically requires manual labeling which is expensive and time-consuming. Zero-shot learning models are capable of classifying the unseen concepts by utilizing their semantic information. The present study introduces image embeddings as side information on zero-shot audio classification by using a nonlinear acoustic-semantic projection. We extract the semantic image representations from the Open Images dataset and evaluate the performance of the models on an audio subset of AudioSet using semantic information in different domains; image, audio, and textual. We demonstrate that the image embeddings can be used as semantic information to perform zero-shot audio classification. The experimental results show that the image and textual embeddings display similar performance both individually and together. We additionally calculate the semantic acoustic embeddings from the test samples to provide an upper limit to the performance. The results show that the classification performance is highly sensitive to the semantic relation between test and training classes and textual and image embeddings can reach up to the semantic acoustic embeddings when the seen and unseen classes are semantically similar.
Low-complexity acoustic scene classification in DCASE 2022 Challenge
Jun 08, 2022

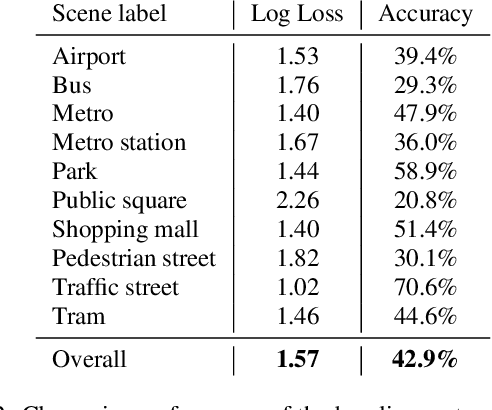
This paper analyzes the outcome of the Low-Complexity Acoustic Scene Classification task in DCASE 2022 Challenge. The task is a continuation from the previous years. In this edition, the requirement for low-complexity solutions were modified including: a limit of 128 K on the number of parameters, including the zero-valued ones, imposed INT8 numerical format, and a limit of 30 million multiply-accumulate operations at inference time. The provided baseline system is a convolutional neural network which employs post-training quantization of parameters, resulting in 46512 parameters, and 29.23 million multiply-and-accumulate operations, well under the set limits of 128K and 30 million, respectively. The baseline system has a 42.9% accuracy and a log-loss of 1.575 on the development data consisting of audio from 9 different devices. An analysis of the submitted systems will be provided after the challenge deadline.
Sound Event Detection: A Tutorial
Jul 12, 2021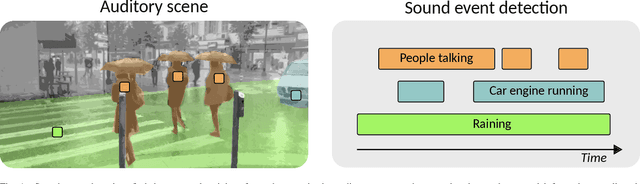
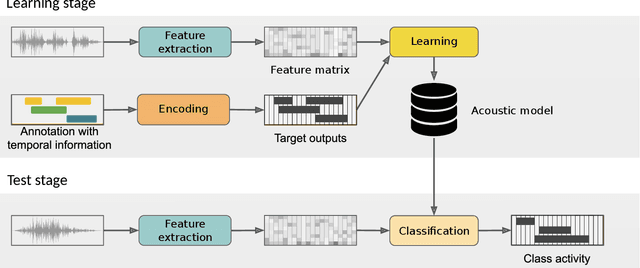
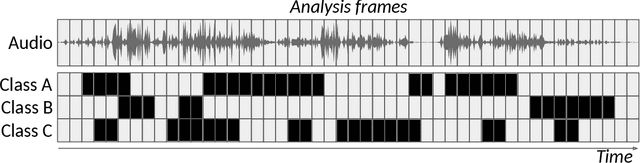
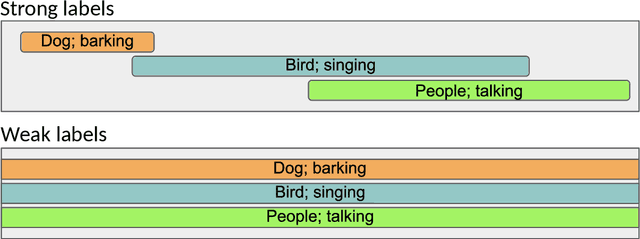
The goal of automatic sound event detection (SED) methods is to recognize what is happening in an audio signal and when it is happening. In practice, the goal is to recognize at what temporal instances different sounds are active within an audio signal. This paper gives a tutorial presentation of sound event detection, including its definition, signal processing and machine learning approaches, evaluation, and future perspectives.
Low-complexity acoustic scene classification for multi-device audio: analysis of DCASE 2021 Challenge systems
May 28, 2021

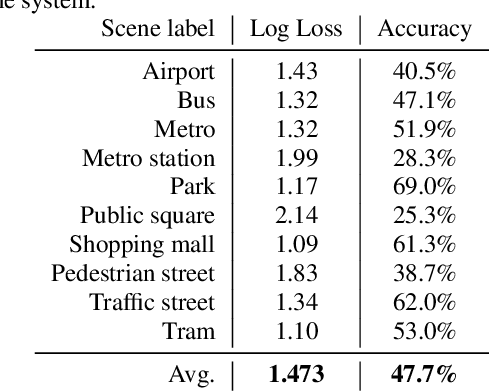
This paper presents the details of Task 1A Acoustic Scene Classification in the DCASE 2021 Challenge. The task consisted of classification of data from multiple devices, requiring good generalization properties, using low-complexity solutions. The provided baseline system is based on a CNN architecture and post-training parameters quantization. The system is trained using all the available training data, without any specific technique for handling device mismatch, and obtains an overall accuracy of 47.7%, with a log loss of 1.473. Details on the challenge results will be added after the challenge deadline.
Audio-visual scene classification: analysis of DCASE 2021 Challenge submissions
May 28, 2021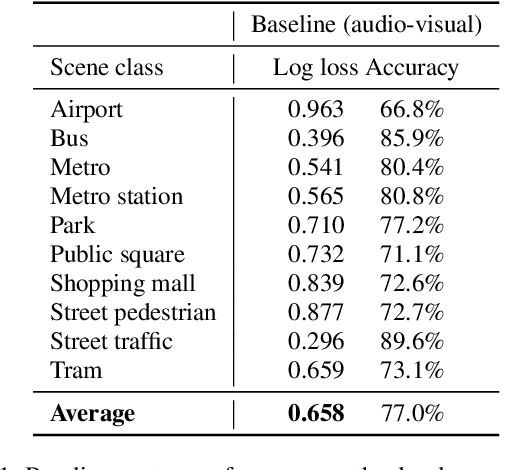
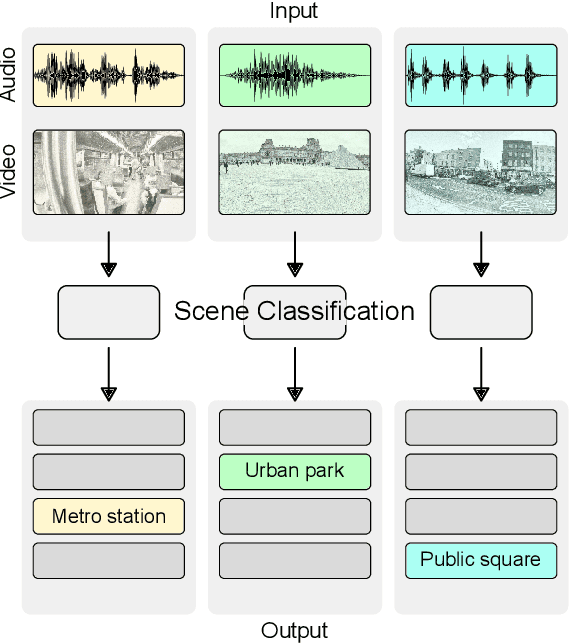
This paper presents the details of the Audio-Visual Scene Classification task in the DCASE 2021 Challenge (Task 1 Subtask B). The task is concerned with classification using audio and video modalities, using a dataset of synchronized recordings. Here we describe the datasets and baseline systems. After the challenge submission deadline, challenge results and analysis of the submissions will be added.
Active Learning for Sound Event Detection
Feb 12, 2020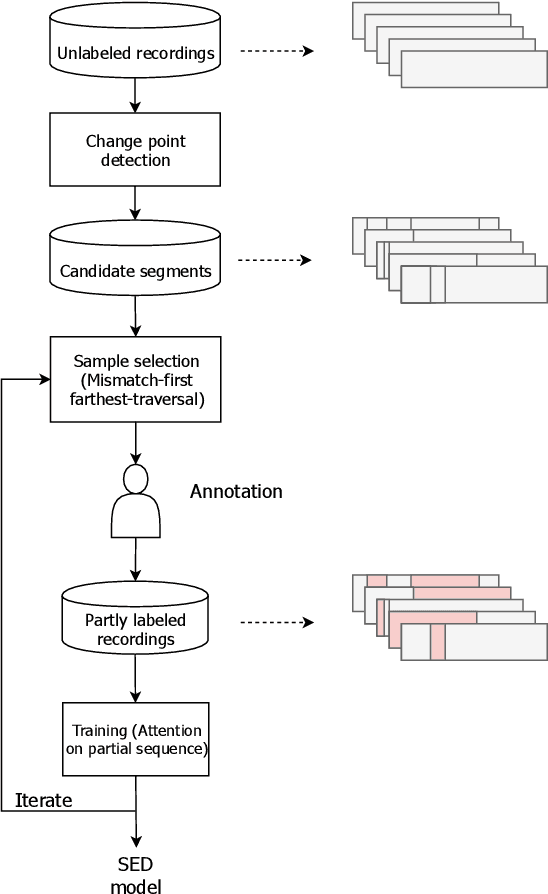
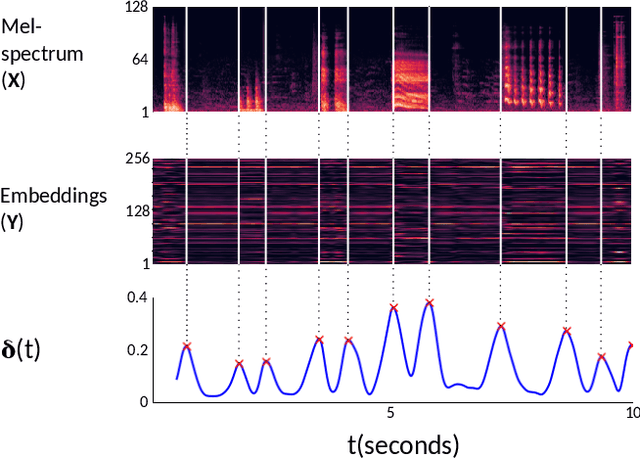
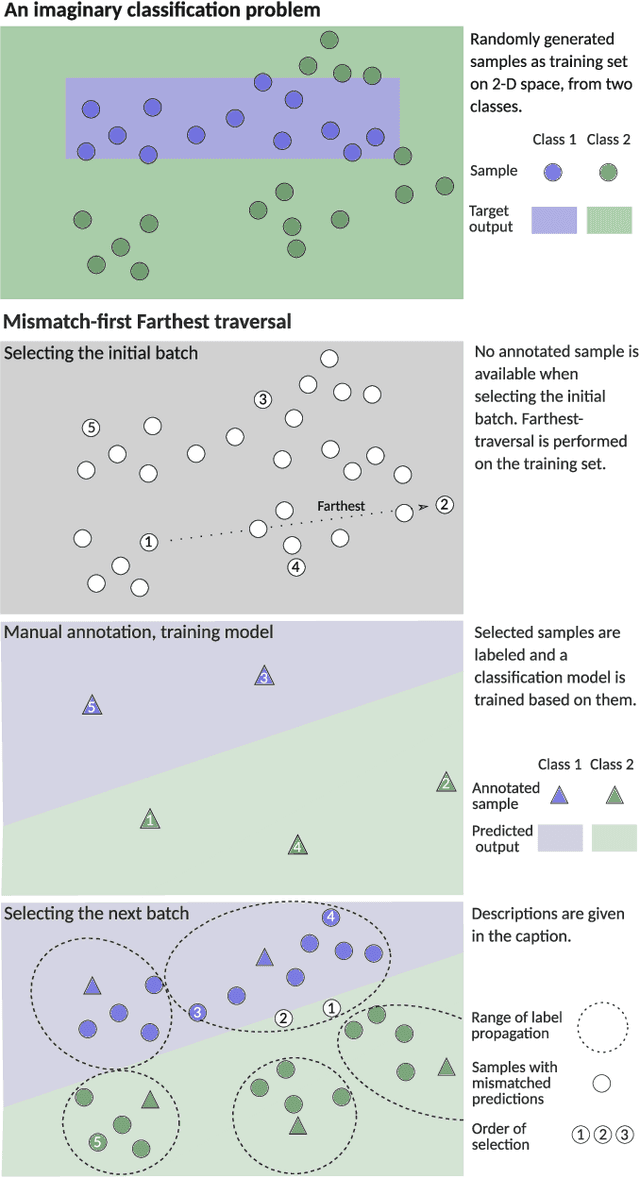
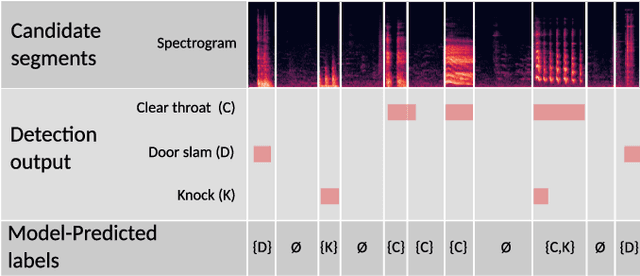
This paper proposes an active learning system for sound event detection (SED). It aims at maximizing the accuracy of a learned SED model with limited annotation effort. The proposed system analyzes an initially unlabeled audio dataset, from which it selects sound segments for manual annotation. The candidate segments are generated based on a proposed change point detection approach, and the selection is based on the principle of mismatch-first farthest-traversal. During the training of SED models, recordings are used as training inputs, preserving the long-term context for annotated segments. The proposed system clearly outperforms reference methods in the two datasets used for evaluation (TUT Rare Sound 2017 and TAU Spatial Sound 2019). Training with recordings as context outperforms training with only annotated segments. Mismatch-first farthest-traversal outperforms reference sample selection methods based on random sampling and uncertainty sampling. Remarkably, the required annotation effort can be greatly reduced on the dataset where target sound events are rare: by annotating only 2% of the training data, the achieved SED performance is similar to annotating all the training data.