 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHWGesture -- A dataset for multimodal understanding of clinical gestures
Sep 09, 2025Hand gesture understanding is essential for several applications in human-computer interaction, including automatic clinical assessment of hand dexterity. While deep learning has advanced static gesture recognition, dynamic gesture understanding remains challenging due to complex spatiotemporal variations. Moreover, existing datasets often lack multimodal and multi-view diversity, precise ground-truth tracking, and an action quality component embedded within gestures. This paper introduces EHWGesture, a multimodal video dataset for gesture understanding featuring five clinically relevant gestures. It includes over 1,100 recordings (6 hours), captured from 25 healthy subjects using two high-resolution RGB-Depth cameras and an event camera. A motion capture system provides precise ground-truth hand landmark tracking, and all devices are spatially calibrated and synchronized to ensure cross-modal alignment. Moreover, to embed an action quality task within gesture understanding, collected recordings are organized in classes of execution speed that mirror clinical evaluations of hand dexterity. Baseline experiments highlight the dataset's potential for gesture classification, gesture trigger detection, and action quality assessment. Thus, EHWGesture can serve as a comprehensive benchmark for advancing multimodal clinical gesture understanding.
A probabilistic framework for dynamic quantization
May 15, 2025We propose a probabilistic framework for dynamic quantization of neural networks that allows for a computationally efficient input-adaptive rescaling of the quantization parameters. Our framework applies a probabilistic model to the network's pre-activations through a lightweight surrogate, enabling the adaptive adjustment of the quantization parameters on a per-input basis without significant memory overhead. We validate our approach on a set of popular computer vision tasks and models, observing only a negligible loss in performance. Our method strikes the best performance and computational overhead tradeoff compared to standard quantization strategies.
From Vision to Sound: Advancing Audio Anomaly Detection with Vision-Based Algorithms
Feb 25, 2025Recent advances in Visual Anomaly Detection (VAD) have introduced sophisticated algorithms leveraging embeddings generated by pre-trained feature extractors. Inspired by these developments, we investigate the adaptation of such algorithms to the audio domain to address the problem of Audio Anomaly Detection (AAD). Unlike most existing AAD methods, which primarily classify anomalous samples, our approach introduces fine-grained temporal-frequency localization of anomalies within the spectrogram, significantly improving explainability. This capability enables a more precise understanding of where and when anomalies occur, making the results more actionable for end users. We evaluate our approach on industrial and environmental benchmarks, demonstrating the effectiveness of VAD techniques in detecting anomalies in audio signals. Moreover, they improve explainability by enabling localized anomaly identification, making audio anomaly detection systems more interpretable and practical.
PaSTe: Improving the Efficiency of Visual Anomaly Detection at the Edge
Oct 15, 2024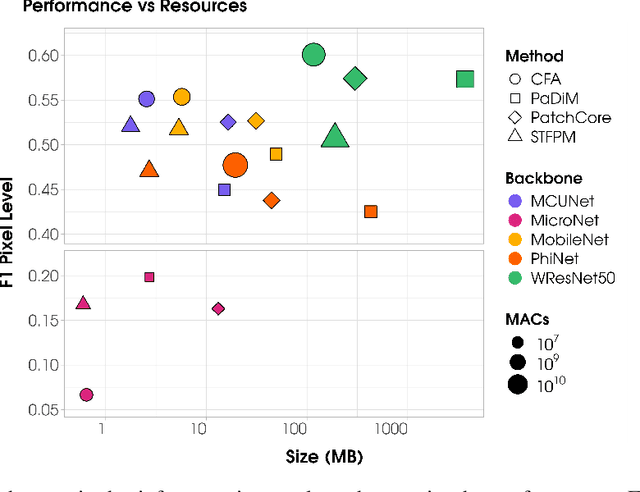
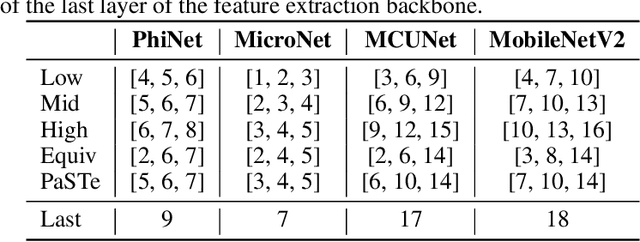
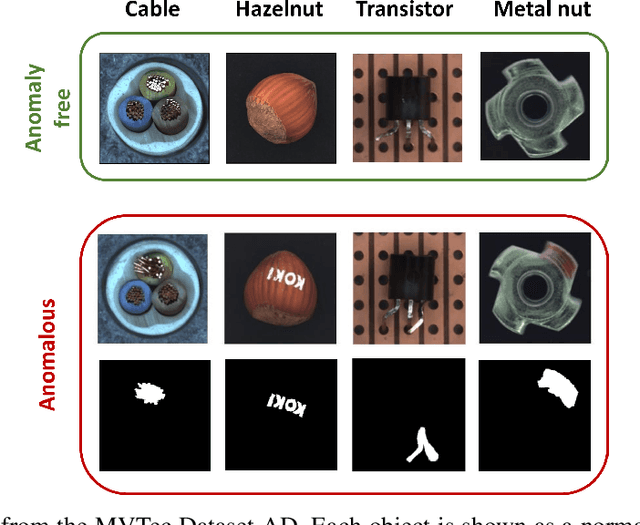
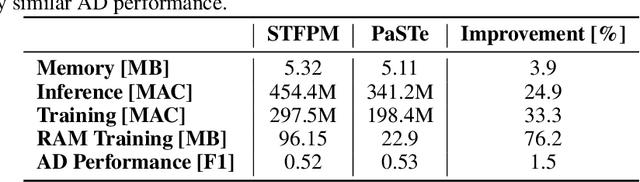
Visual Anomaly Detection (VAD) has gained significant research attention for its ability to identify anomalous images and pinpoint the specific areas responsible for the anomaly. A key advantage of VAD is its unsupervised nature, which eliminates the need for costly and time-consuming labeled data collection. However, despite its potential for real-world applications, the literature has given limited focus to resource-efficient VAD, particularly for deployment on edge devices. This work addresses this gap by leveraging lightweight neural networks to reduce memory and computation requirements, enabling VAD deployment on resource-constrained edge devices. We benchmark the major VAD algorithms within this framework and demonstrate the feasibility of edge-based VAD using the well-known MVTec dataset. Furthermore, we introduce a novel algorithm, Partially Shared Teacher-student (PaSTe), designed to address the high resource demands of the existing Student Teacher Feature Pyramid Matching (STFPM) approach. Our results show that PaSTe decreases the inference time by 25%, while reducing the training time by 33% and peak RAM usage during training by 76%. These improvements make the VAD process significantly more efficient, laying a solid foundation for real-world deployment on edge devices.
Replay Consolidation with Label Propagation for Continual Object Detection
Sep 09, 2024


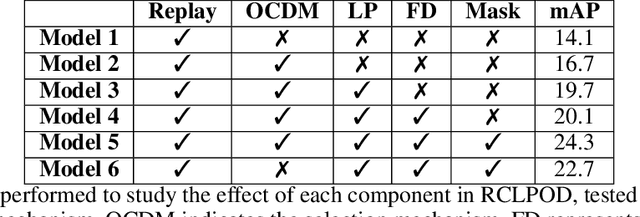
Object Detection is a highly relevant computer vision problem with many applications such as robotics and autonomous driving. Continual Learning~(CL) considers a setting where a model incrementally learns new information while retaining previously acquired knowledge. This is particularly challenging since Deep Learning models tend to catastrophically forget old knowledge while training on new data. In particular, Continual Learning for Object Detection~(CLOD) poses additional difficulties compared to CL for Classification. In CLOD, images from previous tasks may contain unknown classes that could reappear labeled in future tasks. These missing annotations cause task interference issues for replay-based approaches. As a result, most works in the literature have focused on distillation-based approaches. However, these approaches are effective only when there is a strong overlap of classes across tasks. To address the issues of current methodologies, we propose a novel technique to solve CLOD called Replay Consolidation with Label Propagation for Object Detection (RCLPOD). Based on the replay method, our solution avoids task interference issues by enhancing the buffer memory samples. Our method is evaluated against existing techniques in CLOD literature, demonstrating its superior performance on established benchmarks like VOC and COCO.
Latent Distillation for Continual Object Detection at the Edge
Sep 03, 2024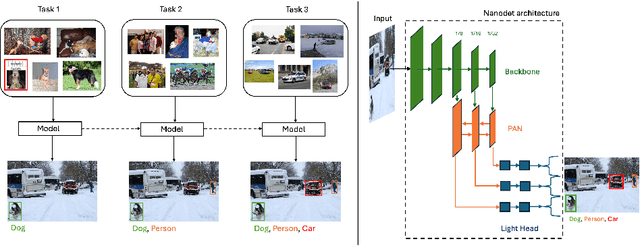
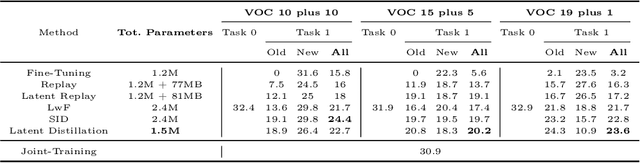
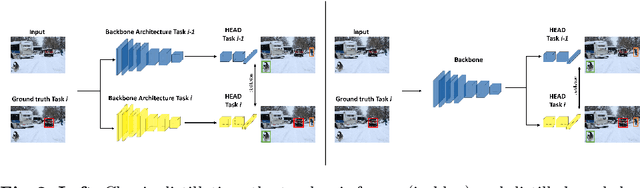
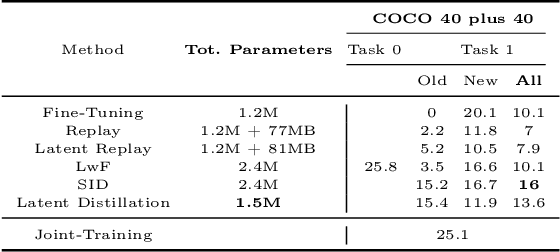
While numerous methods achieving remarkable performance exist in the Object Detection literature, addressing data distribution shifts remains challenging. Continual Learning (CL) offers solutions to this issue, enabling models to adapt to new data while maintaining performance on previous data. This is particularly pertinent for edge devices, common in dynamic environments like automotive and robotics. In this work, we address the memory and computation constraints of edge devices in the Continual Learning for Object Detection (CLOD) scenario. Specifically, (i) we investigate the suitability of an open-source, lightweight, and fast detector, namely NanoDet, for CLOD on edge devices, improving upon larger architectures used in the literature. Moreover, (ii) we propose a novel CL method, called Latent Distillation~(LD), that reduces the number of operations and the memory required by state-of-the-art CL approaches without significantly compromising detection performance. Our approach is validated using the well-known VOC and COCO benchmarks, reducing the distillation parameter overhead by 74\% and the Floating Points Operations~(FLOPs) by 56\% per model update compared to other distillation methods.
tinyCLAP: Distilling Constrastive Language-Audio Pretrained Models
Nov 24, 2023



Contrastive Language-Audio Pretraining (CLAP) became of crucial importance in the field of audio and speech processing. Its employment ranges from sound event detection to text-to-audio generation. However, one of the main limitations is the considerable amount of data required in the training process and the overall computational complexity during inference. This paper investigates how we can reduce the complexity of contrastive language-audio pre-trained models, yielding an efficient model that we call tinyCLAP. We derive an unimodal distillation loss from first principles and explore how the dimensionality of the shared, multimodal latent space can be reduced via pruning. TinyCLAP uses only 6% of the original Microsoft CLAP parameters with a minimal reduction (less than 5%) in zero-shot classification performance across the three sound event detection datasets on which it was tested
Low-complexity acoustic scene classification in DCASE 2022 Challenge
Jun 08, 2022

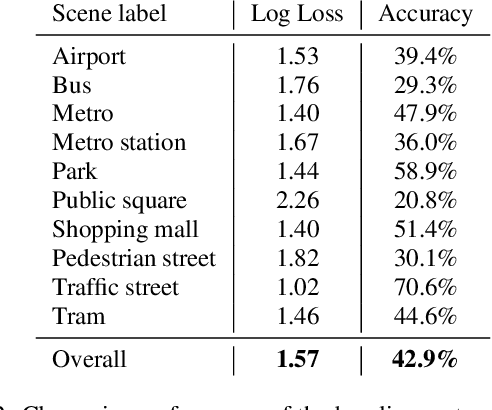
This paper analyzes the outcome of the Low-Complexity Acoustic Scene Classification task in DCASE 2022 Challenge. The task is a continuation from the previous years. In this edition, the requirement for low-complexity solutions were modified including: a limit of 128 K on the number of parameters, including the zero-valued ones, imposed INT8 numerical format, and a limit of 30 million multiply-accumulate operations at inference time. The provided baseline system is a convolutional neural network which employs post-training quantization of parameters, resulting in 46512 parameters, and 29.23 million multiply-and-accumulate operations, well under the set limits of 128K and 30 million, respectively. The baseline system has a 42.9% accuracy and a log-loss of 1.575 on the development data consisting of audio from 9 different devices. An analysis of the submitted systems will be provided after the challenge deadline.
Sub-mW Keyword Spotting on an MCU: Analog Binary Feature Extraction and Binary Neural Networks
Jan 10, 2022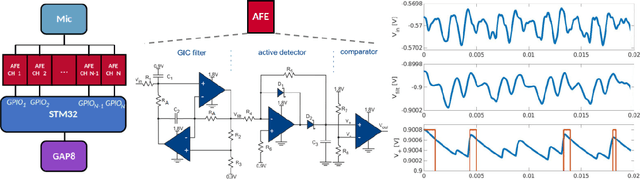

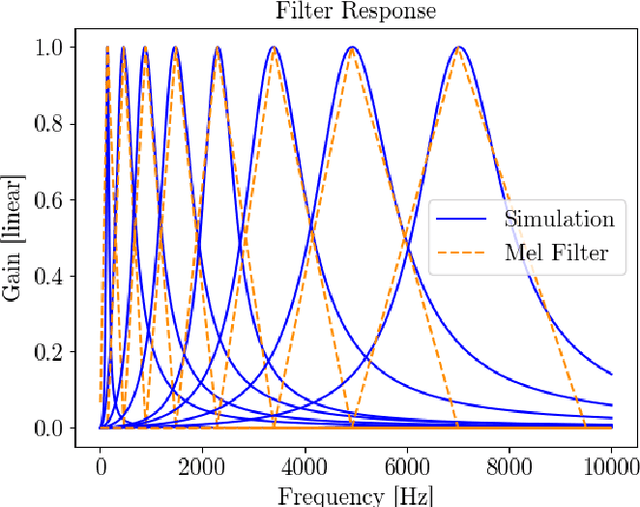
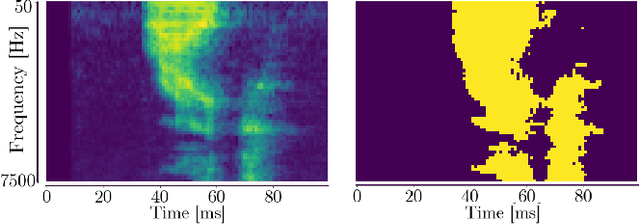
Keyword spotting (KWS) is a crucial function enabling the interaction with the many ubiquitous smart devices in our surroundings, either activating them through wake-word or directly as a human-computer interface. For many applications, KWS is the entry point for our interactions with the device and, thus, an always-on workload. Many smart devices are mobile and their battery lifetime is heavily impacted by continuously running services. KWS and similar always-on services are thus the focus when optimizing the overall power consumption. This work addresses KWS energy-efficiency on low-cost microcontroller units (MCUs). We combine analog binary feature extraction with binary neural networks. By replacing the digital preprocessing with the proposed analog front-end, we show that the energy required for data acquisition and preprocessing can be reduced by 29x, cutting its share from a dominating 85% to a mere 16% of the overall energy consumption for our reference KWS application. Experimental evaluations on the Speech Commands Dataset show that the proposed system outperforms state-of-the-art accuracy and energy efficiency, respectively, by 1% and 4.3x on a 10-class dataset while providing a compelling accuracy-energy trade-off including a 2% accuracy drop for a 71x energy reduction.
PhiNets: a scalable backbone for low-power AI at the edge
Oct 01, 2021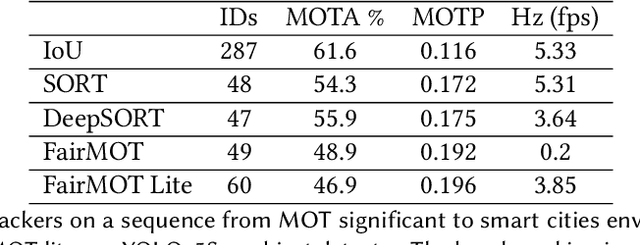
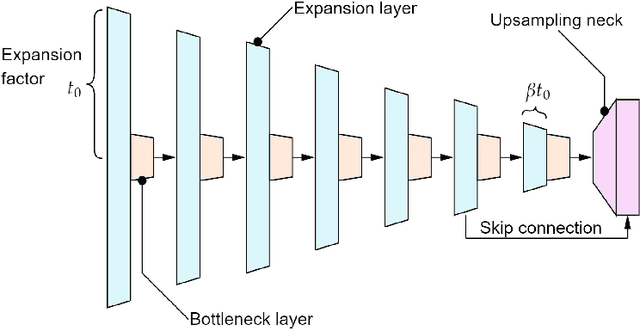
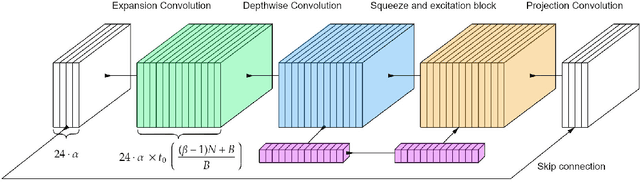

In the Internet of Things era, where we see many interconnected and heterogeneous mobile and fixed smart devices, distributing the intelligence from the cloud to the edge has become a necessity. Due to limited computational and communication capabilities, low memory and limited energy budget, bringing artificial intelligence algorithms to peripheral devices, such as the end-nodes of a sensor network, is a challenging task and requires the design of innovative methods. In this work, we present PhiNets, a new scalable backbone optimized for deep-learning-based image processing on resource-constrained platforms. PhiNets are based on inverted residual blocks specifically designed to decouple the computational cost, working memory, and parameter memory, thus exploiting all the available resources. With a YoloV2 detection head and Simple Online and Realtime Tracking, the proposed architecture has achieved the state-of-the-art results in (i) detection on the COCO and VOC2012 benchmarks, and (ii) tracking on the MOT15 benchmark. PhiNets reduce the parameter count of 87% to 93% with respect to previous state-of-the-art models (EfficientNetv1, MobileNetv2) and achieve better performance with lower computational cost. Moreover, we demonstrate our approach on a prototype node based on a STM32H743 microcontroller (MCU) with 2MB of internal Flash and 1MB of RAM and achieve power requirements in the order of 10 mW. The code for the PhiNets is publicly available on GitHub.