 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Recommender Models Inference: Automatic Asymmetric Data Flow Optimization
Jul 02, 2025Deep Recommender Models (DLRMs) inference is a fundamental AI workload accounting for more than 79% of the total AI workload in Meta's data centers. DLRMs' performance bottleneck is found in the embedding layers, which perform many random memory accesses to retrieve small embedding vectors from tables of various sizes. We propose the design of tailored data flows to speedup embedding look-ups. Namely, we propose four strategies to look up an embedding table effectively on one core, and a framework to automatically map the tables asymmetrically to the multiple cores of a SoC. We assess the effectiveness of our method using the Huawei Ascend AI accelerators, comparing it with the default Ascend compiler, and we perform high-level comparisons with Nvidia A100. Results show a speed-up varying from 1.5x up to 6.5x for real workload distributions, and more than 20x for extremely unbalanced distributions. Furthermore, the method proves to be much more independent of the query distribution than the baseline.
* 5 pages, 4 figures, conference: IEEE ICCD24
Late Breaking Results: The Art of Beating the Odds with Predictor-Guided Random Design Space Exploration
Feb 26, 2025



This work introduces an innovative method for improving combinational digital circuits through random exploration in MIG-based synthesis. High-quality circuits are crucial for performance, power, and cost, making this a critical area of active research. Our approach incorporates next-state prediction and iterative selection, significantly accelerating the synthesis process. This novel method achieves up to 14x synthesis speedup and up to 20.94% better MIG minimization on the EPFL Combinational Benchmark Suite compared to state-of-the-art techniques. We further explore various predictor models and show that increased prediction accuracy does not guarantee an equivalent increase in synthesis quality of results or speedup, observing that randomness remains a desirable factor.
Top-Theta Attention: Sparsifying Transformers by Compensated Thresholding
Feb 12, 2025The attention mechanism is essential for the impressive capabilities of transformer-based Large Language Models (LLMs). However, calculating attention is computationally intensive due to its quadratic dependency on the sequence length. We introduce a novel approach called Top-Theta Attention, or simply Top-$\theta$, which selectively prunes less essential attention elements by comparing them against carefully calibrated thresholds. This method greatly improves the efficiency of self-attention matrix multiplication while preserving model accuracy, reducing the number of required V cache rows by 3x during generative decoding and the number of attention elements by 10x during the prefill phase. Our method does not require model retraining; instead, it requires only a brief calibration phase to be resilient to distribution shifts, thus not requiring the thresholds for different datasets to be recalibrated. Unlike top-k attention, Top-$\theta$ eliminates full-vector dependency, making it suitable for tiling and scale-out and avoiding costly top-k search. A key innovation of our approach is the development of efficient numerical compensation techniques, which help preserve model accuracy even under aggressive pruning of attention scores.
Stella Nera: Achieving 161 TOp/s/W with Multiplier-free DNN Acceleration based on Approximate Matrix Multiplication
Nov 16, 2023From classical HPC to deep learning, MatMul is at the heart of today's computing. The recent Maddness method approximates MatMul without the need for multiplication by using a hash-based version of product quantization (PQ) indexing into a look-up table (LUT). Stella Nera is the first Maddness accelerator and it achieves 15x higher area efficiency (GMAC/s/mm^2) and more than 25x higher energy efficiency (TMAC/s/W) than direct MatMul accelerators implemented in the same technology. The hash function is a decision tree, which allows for an efficient hardware implementation as the multiply-accumulate operations are replaced by decision tree passes and LUT lookups. The entire Maddness MatMul can be broken down into parts that allow an effective implementation with small computing units and memories, allowing it to reach extreme efficiency while remaining generically applicable for MatMul tasks. In a commercial 14nm technology and scaled to 3nm, we achieve an energy efficiency of 161 TOp/s/W@0.55V with a Top-1 accuracy on CIFAR-10 of more than 92.5% using ResNet9.
Going Further With Winograd Convolutions: Tap-Wise Quantization for Efficient Inference on 4x4 Tile
Sep 26, 2022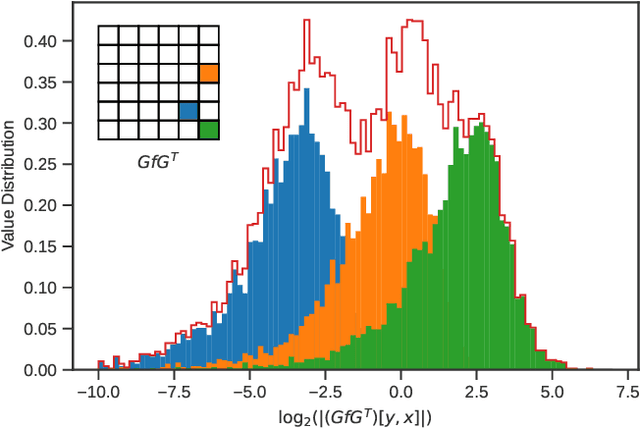

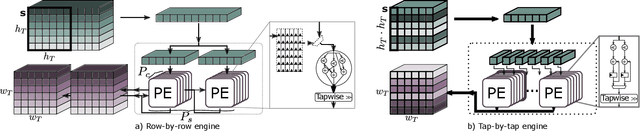
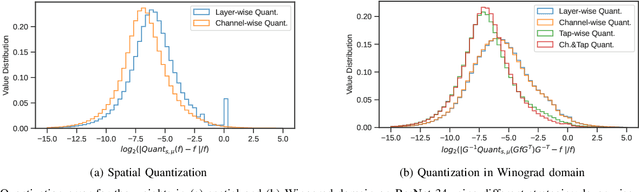
Most of today's computer vision pipelines are built around deep neural networks, where convolution operations require most of the generally high compute effort. The Winograd convolution algorithm computes convolutions with fewer MACs compared to the standard algorithm, reducing the operation count by a factor of 2.25x for 3x3 convolutions when using the version with 2x2-sized tiles $F_2$. Even though the gain is significant, the Winograd algorithm with larger tile sizes, i.e., $F_4$, offers even more potential in improving throughput and energy efficiency, as it reduces the required MACs by 4x. Unfortunately, the Winograd algorithm with larger tile sizes introduces numerical issues that prevent its use on integer domain-specific accelerators and higher computational overhead to transform input and output data between spatial and Winograd domains. To unlock the full potential of Winograd $F_4$, we propose a novel tap-wise quantization method that overcomes the numerical issues of using larger tiles, enabling integer-only inference. Moreover, we present custom hardware units that process the Winograd transformations in a power- and area-efficient way, and we show how to integrate such custom modules in an industrial-grade, programmable DSA. An extensive experimental evaluation on a large set of state-of-the-art computer vision benchmarks reveals that the tap-wise quantization algorithm makes the quantized Winograd $F_4$ network almost as accurate as the FP32 baseline. The Winograd-enhanced DSA achieves up to 1.85x gain in energy efficiency and up to 1.83x end-to-end speed-up for state-of-the-art segmentation and detection networks.
Sub-mW Keyword Spotting on an MCU: Analog Binary Feature Extraction and Binary Neural Networks
Jan 10, 2022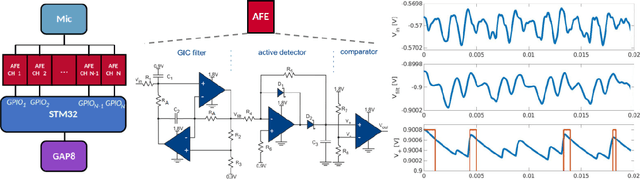

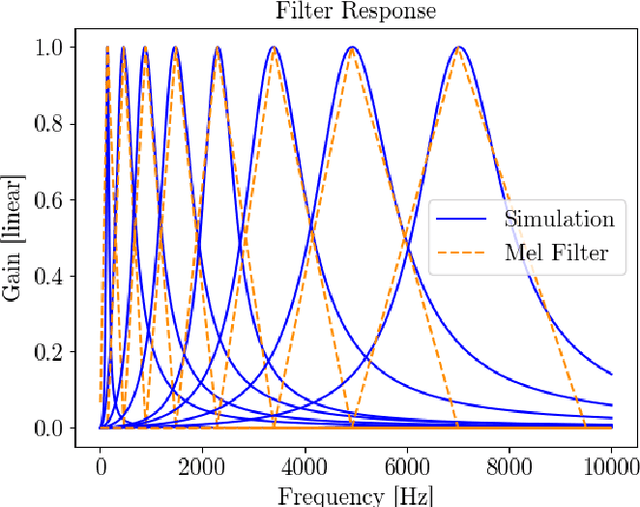
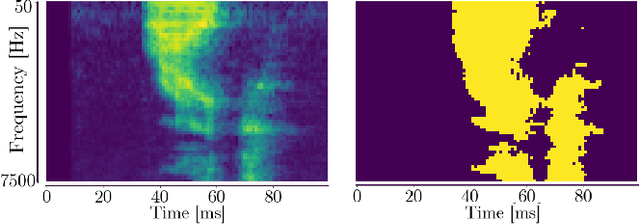
Keyword spotting (KWS) is a crucial function enabling the interaction with the many ubiquitous smart devices in our surroundings, either activating them through wake-word or directly as a human-computer interface. For many applications, KWS is the entry point for our interactions with the device and, thus, an always-on workload. Many smart devices are mobile and their battery lifetime is heavily impacted by continuously running services. KWS and similar always-on services are thus the focus when optimizing the overall power consumption. This work addresses KWS energy-efficiency on low-cost microcontroller units (MCUs). We combine analog binary feature extraction with binary neural networks. By replacing the digital preprocessing with the proposed analog front-end, we show that the energy required for data acquisition and preprocessing can be reduced by 29x, cutting its share from a dominating 85% to a mere 16% of the overall energy consumption for our reference KWS application. Experimental evaluations on the Speech Commands Dataset show that the proposed system outperforms state-of-the-art accuracy and energy efficiency, respectively, by 1% and 4.3x on a 10-class dataset while providing a compelling accuracy-energy trade-off including a 2% accuracy drop for a 71x energy reduction.
Sound Event Detection with Binary Neural Networks on Tightly Power-Constrained IoT Devices
Jan 12, 2021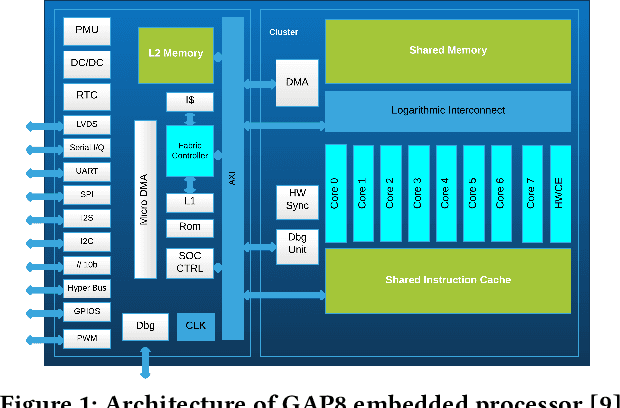
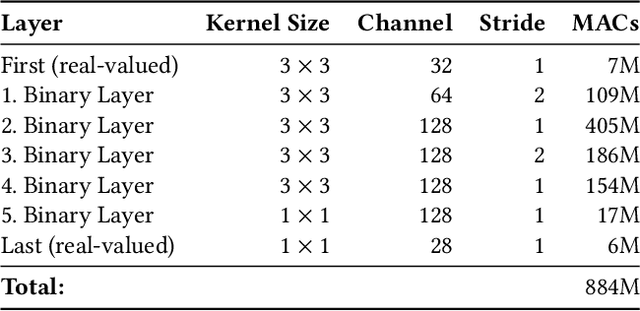
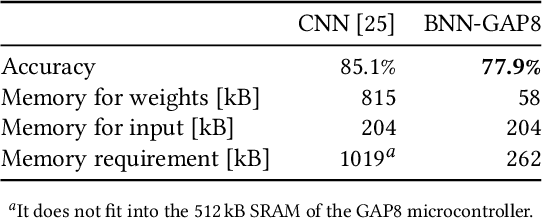
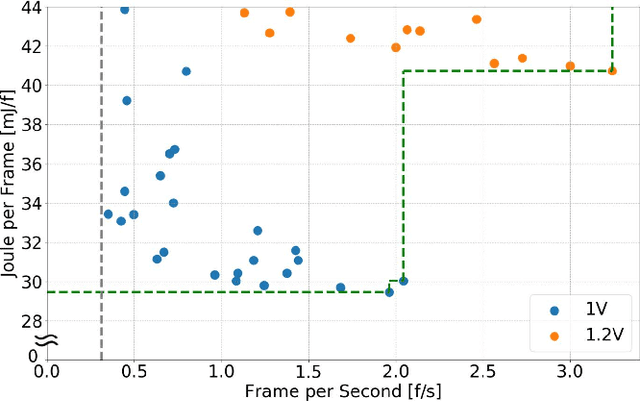
Sound event detection (SED) is a hot topic in consumer and smart city applications. Existing approaches based on Deep Neural Networks are very effective, but highly demanding in terms of memory, power, and throughput when targeting ultra-low power always-on devices. Latency, availability, cost, and privacy requirements are pushing recent IoT systems to process the data on the node, close to the sensor, with a very limited energy supply, and tight constraints on the memory size and processing capabilities precluding to run state-of-the-art DNNs. In this paper, we explore the combination of extreme quantization to a small-footprint binary neural network (BNN) with the highly energy-efficient, RISC-V-based (8+1)-core GAP8 microcontroller. Starting from an existing CNN for SED whose footprint (815 kB) exceeds the 512 kB of memory available on our platform, we retrain the network using binary filters and activations to match these memory constraints. (Fully) binary neural networks come with a natural drop in accuracy of 12-18% on the challenging ImageNet object recognition challenge compared to their equivalent full-precision baselines. This BNN reaches a 77.9% accuracy, just 7% lower than the full-precision version, with 58 kB (7.2 times less) for the weights and 262 kB (2.4 times less) memory in total. With our BNN implementation, we reach a peak throughput of 4.6 GMAC/s and 1.5 GMAC/s over the full network, including preprocessing with Mel bins, which corresponds to an efficiency of 67.1 GMAC/s/W and 31.3 GMAC/s/W, respectively. Compared to the performance of an ARM Cortex-M4 implementation, our system has a 10.3 times faster execution time and a 51.1 times higher energy-efficiency.
Hyperdrive: A Systolically Scalable Binary-Weight CNN Inference Engine for mW IoT End-Nodes
Jun 13, 2018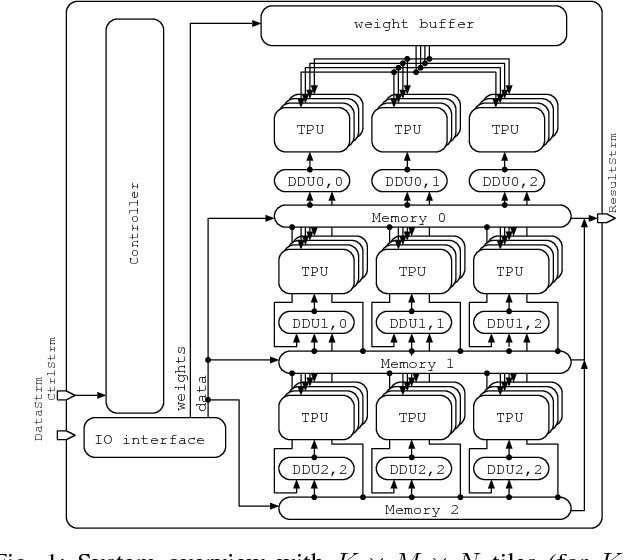
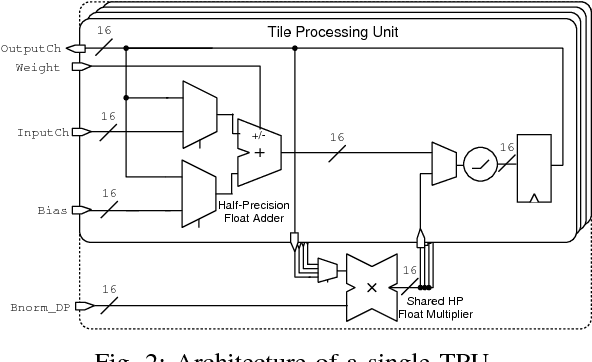
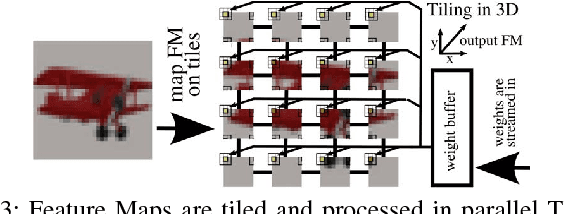
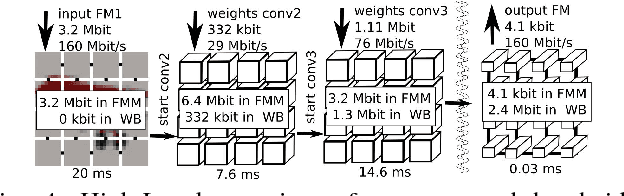
Deep neural networks have achieved impressive results in computer vision and machine learning. Unfortunately, state-of-the-art networks are extremely compute- and memory-intensive which makes them unsuitable for mW-devices such as IoT end-nodes. Aggressive quantization of these networks dramatically reduces the computation and memory footprint. Binary-weight neural networks (BWNs) follow this trend, pushing weight quantization to the limit. Hardware accelerators for BWNs presented up to now have focused on core efficiency, disregarding I/O bandwidth and system-level efficiency that are crucial for deployment of accelerators in ultra-low power devices. We present Hyperdrive: a BWN accelerator dramatically reducing the I/O bandwidth exploiting a novel binary-weight streaming approach, and capable of handling high-resolution images by virtue of its systolic-scalable architecture. We achieve a 5.9 TOp/s/W system-level efficiency (i.e. including I/Os)---2.2x higher than state-of-the-art BNN accelerators, even if our core uses resource-intensive FP16 arithmetic for increased robustness.
XNORBIN: A 95 TOp/s/W Hardware Accelerator for Binary Convolutional Neural Networks
Mar 05, 2018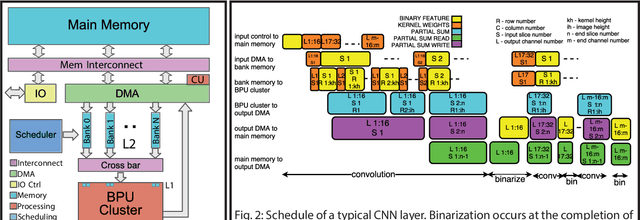
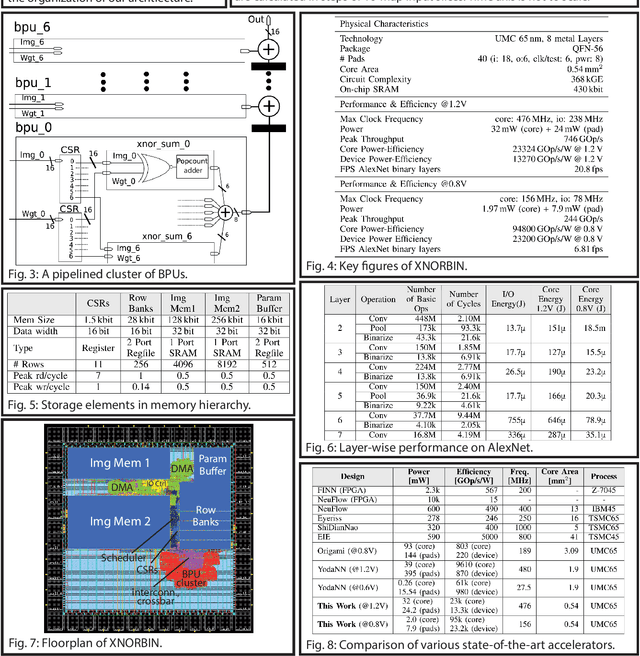
Deploying state-of-the-art CNNs requires power-hungry processors and off-chip memory. This precludes the implementation of CNNs in low-power embedded systems. Recent research shows CNNs sustain extreme quantization, binarizing their weights and intermediate feature maps, thereby saving 8-32\x memory and collapsing energy-intensive sum-of-products into XNOR-and-popcount operations. We present XNORBIN, an accelerator for binary CNNs with computation tightly coupled to memory for aggressive data reuse. Implemented in UMC 65nm technology XNORBIN achieves an energy efficiency of 95 TOp/s/W and an area efficiency of 2.0 TOp/s/MGE at 0.8 V.
YodaNN: An Architecture for Ultra-Low Power Binary-Weight CNN Acceleration
Feb 24, 2017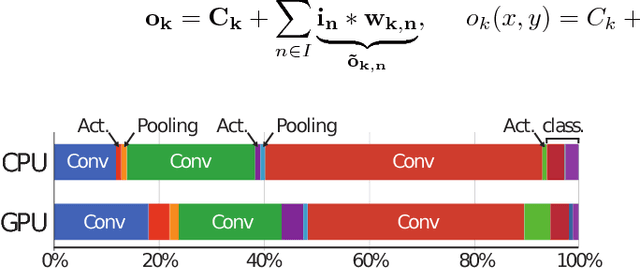

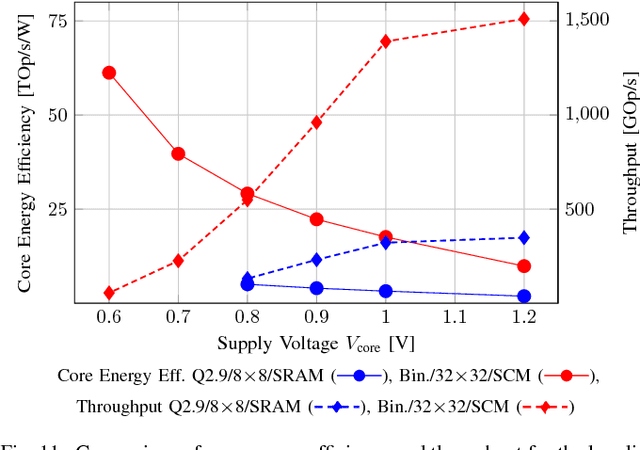
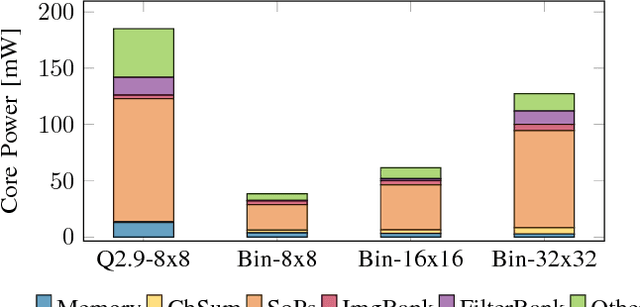
Convolutional neural networks (CNNs) have revolutionized the world of computer vision over the last few years, pushing image classification beyond human accuracy. The computational effort of today's CNNs requires power-hungry parallel processors or GP-GPUs. Recent developments in CNN accelerators for system-on-chip integration have reduced energy consumption significantly. Unfortunately, even these highly optimized devices are above the power envelope imposed by mobile and deeply embedded applications and face hard limitations caused by CNN weight I/O and storage. This prevents the adoption of CNNs in future ultra-low power Internet of Things end-nodes for near-sensor analytics. Recent algorithmic and theoretical advancements enable competitive classification accuracy even when limiting CNNs to binary (+1/-1) weights during training. These new findings bring major optimization opportunities in the arithmetic core by removing the need for expensive multiplications, as well as reducing I/O bandwidth and storage. In this work, we present an accelerator optimized for binary-weight CNNs that achieves 1510 GOp/s at 1.2 V on a core area of only 1.33 MGE (Million Gate Equivalent) or 0.19 mm$^2$ and with a power dissipation of 895 {\mu}W in UMC 65 nm technology at 0.6 V. Our accelerator significantly outperforms the state-of-the-art in terms of energy and area efficiency achieving 61.2 TOp/s/W@0.6 V and 1135 GOp/s/MGE@1.2 V, respectively.