Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXNORBIN: A 95 TOp/s/W Hardware Accelerator for Binary Convolutional Neural Networks
Paper and Code
Mar 05, 2018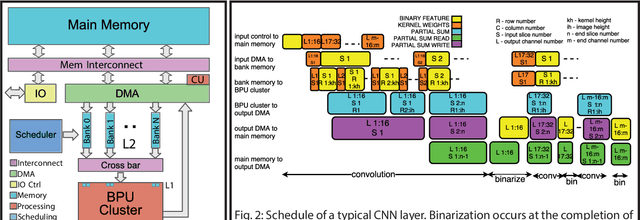
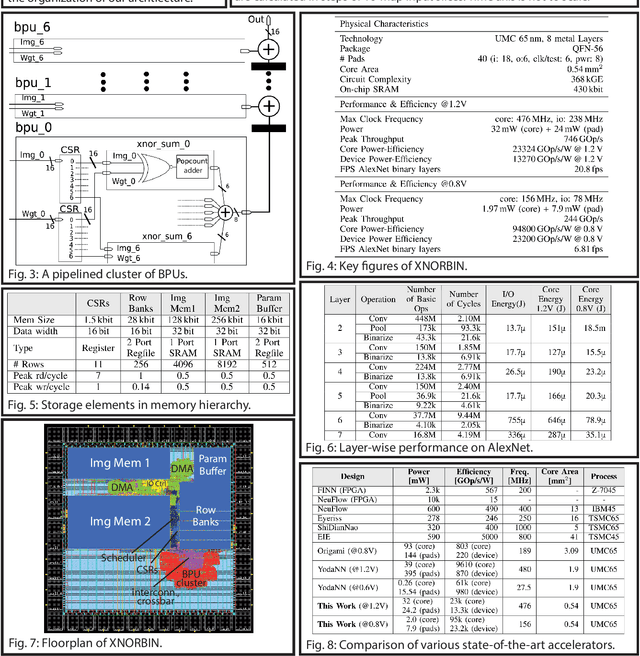
Deploying state-of-the-art CNNs requires power-hungry processors and off-chip memory. This precludes the implementation of CNNs in low-power embedded systems. Recent research shows CNNs sustain extreme quantization, binarizing their weights and intermediate feature maps, thereby saving 8-32\x memory and collapsing energy-intensive sum-of-products into XNOR-and-popcount operations. We present XNORBIN, an accelerator for binary CNNs with computation tightly coupled to memory for aggressive data reuse. Implemented in UMC 65nm technology XNORBIN achieves an energy efficiency of 95 TOp/s/W and an area efficiency of 2.0 TOp/s/MGE at 0.8 V.
View paper on