 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Further With Winograd Convolutions: Tap-Wise Quantization for Efficient Inference on 4x4 Tile
Sep 26, 2022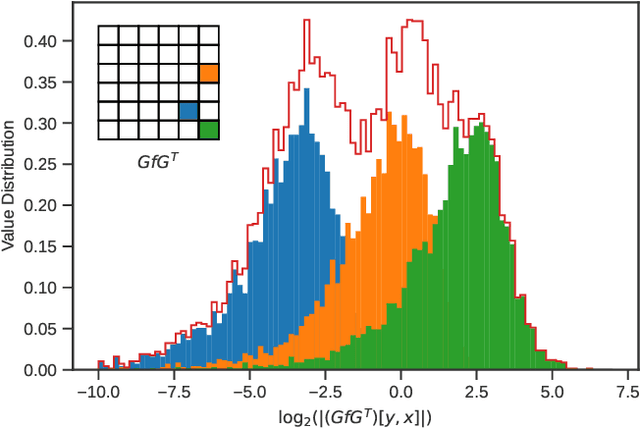

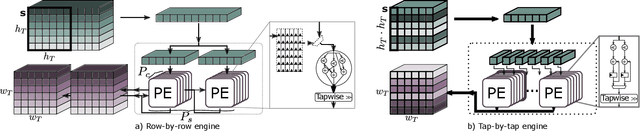
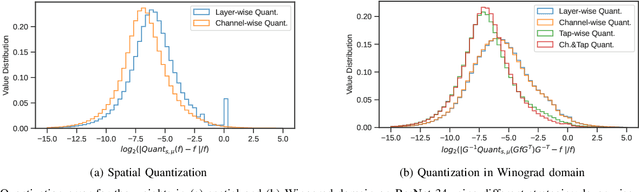
Most of today's computer vision pipelines are built around deep neural networks, where convolution operations require most of the generally high compute effort. The Winograd convolution algorithm computes convolutions with fewer MACs compared to the standard algorithm, reducing the operation count by a factor of 2.25x for 3x3 convolutions when using the version with 2x2-sized tiles $F_2$. Even though the gain is significant, the Winograd algorithm with larger tile sizes, i.e., $F_4$, offers even more potential in improving throughput and energy efficiency, as it reduces the required MACs by 4x. Unfortunately, the Winograd algorithm with larger tile sizes introduces numerical issues that prevent its use on integer domain-specific accelerators and higher computational overhead to transform input and output data between spatial and Winograd domains. To unlock the full potential of Winograd $F_4$, we propose a novel tap-wise quantization method that overcomes the numerical issues of using larger tiles, enabling integer-only inference. Moreover, we present custom hardware units that process the Winograd transformations in a power- and area-efficient way, and we show how to integrate such custom modules in an industrial-grade, programmable DSA. An extensive experimental evaluation on a large set of state-of-the-art computer vision benchmarks reveals that the tap-wise quantization algorithm makes the quantized Winograd $F_4$ network almost as accurate as the FP32 baseline. The Winograd-enhanced DSA achieves up to 1.85x gain in energy efficiency and up to 1.83x end-to-end speed-up for state-of-the-art segmentation and detection networks.
Dynamic ConvNets on Tiny Devices via Nested Sparsity
Mar 07, 2022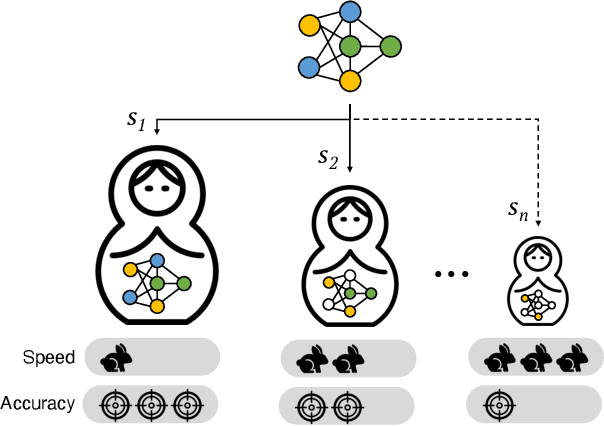
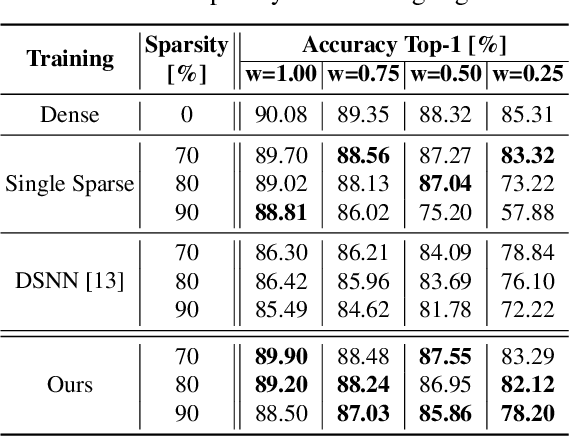
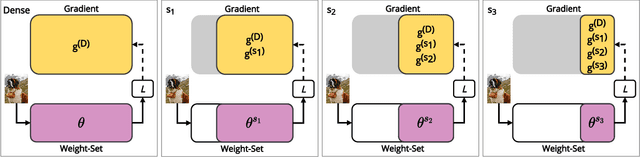

This work introduces a new training and compression pipeline to build Nested Sparse ConvNets, a class of dynamic Convolutional Neural Networks (ConvNets) suited for inference tasks deployed on resource-constrained devices at the edge of the Internet-of-Things. A Nested Sparse ConvNet consists of a single ConvNet architecture containing N sparse sub-networks with nested weights subsets, like a Matryoshka doll, and can trade accuracy for latency at run time, using the model sparsity as a dynamic knob. To attain high accuracy at training time, we propose a gradient masking technique that optimally routes the learning signals across the nested weights subsets. To minimize the storage footprint and efficiently process the obtained models at inference time, we introduce a new sparse matrix compression format with dedicated compute kernels that fruitfully exploit the characteristic of the nested weights subsets. Tested on image classification and object detection tasks on an off-the-shelf ARM-M7 Micro Controller Unit (MCU), Nested Sparse ConvNets outperform variable-latency solutions naively built assembling single sparse models trained as stand-alone instances, achieving (i) comparable accuracy, (ii) remarkable storage savings, and (iii) high performance. Moreover, when compared to state-of-the-art dynamic strategies, like dynamic pruning and layer width scaling, Nested Sparse ConvNets turn out to be Pareto optimal in the accuracy vs. latency space.