 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry-Aware Fusion of Vision and Tactile Sensing via Bilateral Force Priors for Robotic Manipulation
Feb 14, 2026Insertion tasks in robotic manipulation demand precise, contact-rich interactions that vision alone cannot resolve. While tactile feedback is intuitively valuable, existing studies have shown that naïve visuo-tactile fusion often fails to deliver consistent improvements. In this work, we propose a Cross-Modal Transformer (CMT) for visuo-tactile fusion that integrates wrist-camera observations with tactile signals through structured self- and cross-attention. To stabilize tactile embeddings, we further introduce a physics-informed regularization that encourages bilateral force balance, reflecting principles of human motor control. Experiments on the TacSL benchmark show that CMT with symmetry regularization achieves a 96.59% insertion success rate, surpassing naïve and gated fusion baselines and closely matching the privileged "wrist + contact force" configuration (96.09%). These results highlight two central insights: (i) tactile sensing is indispensable for precise alignment, and (ii) principled multimodal fusion, further strengthened by physics-informed regularization, unlocks complementary strengths of vision and touch, approaching privileged performance under realistic sensing.
MCUBench: A Benchmark of Tiny Object Detectors on MCUs
Sep 27, 2024We introduce MCUBench, a benchmark featuring over 100 YOLO-based object detection models evaluated on the VOC dataset across seven different MCUs. This benchmark provides detailed data on average precision, latency, RAM, and Flash usage for various input resolutions and YOLO-based one-stage detectors. By conducting a controlled comparison with a fixed training pipeline, we collect comprehensive performance metrics. Our Pareto-optimal analysis shows that integrating modern detection heads and training techniques allows various YOLO architectures, including legacy models like YOLOv3, to achieve a highly efficient tradeoff between mean Average Precision (mAP) and latency. MCUBench serves as a valuable tool for benchmarking the MCU performance of contemporary object detectors and aids in model selection based on specific constraints.
Accelerating Deep Neural Networks via Semi-Structured Activation Sparsity
Sep 27, 2023The demand for efficient processing of deep neural networks (DNNs) on embedded devices is a significant challenge limiting their deployment. Exploiting sparsity in the network's feature maps is one of the ways to reduce its inference latency. It is known that unstructured sparsity results in lower accuracy degradation with respect to structured sparsity but the former needs extensive inference engine changes to get latency benefits. To tackle this challenge, we propose a solution to induce semi-structured activation sparsity exploitable through minor runtime modifications. To attain high speedup levels at inference time, we design a sparse training procedure with awareness of the final position of the activations while computing the General Matrix Multiplication (GEMM). We extensively evaluate the proposed solution across various models for image classification and object detection tasks. Remarkably, our approach yields a speed improvement of $1.25 \times$ with a minimal accuracy drop of $1.1\%$ for the ResNet18 model on the ImageNet dataset. Furthermore, when combined with a state-of-the-art structured pruning method, the resulting models provide a good latency-accuracy trade-off, outperforming models that solely employ structured pruning techniques.
YOLOBench: Benchmarking Efficient Object Detectors on Embedded Systems
Jul 26, 2023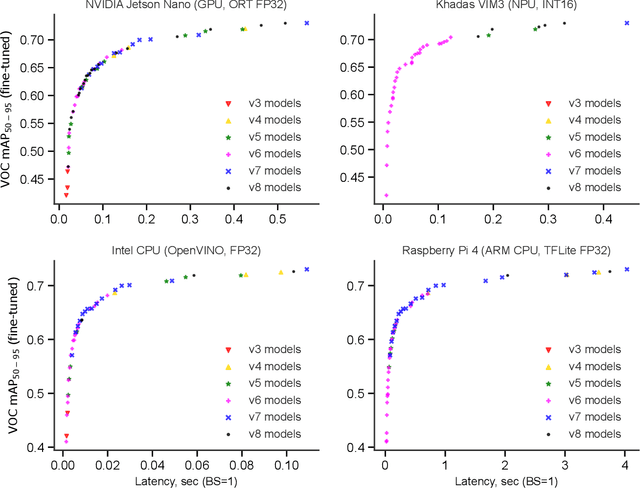
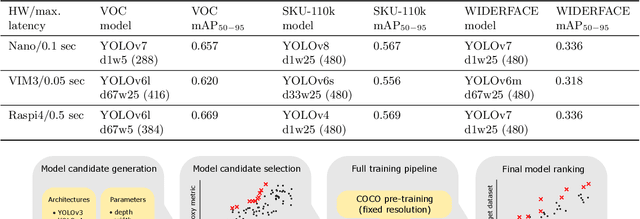
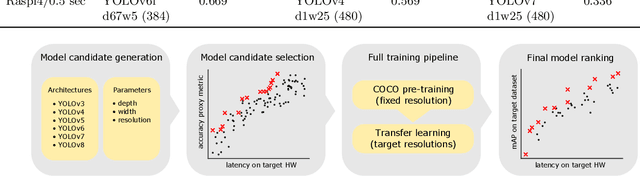
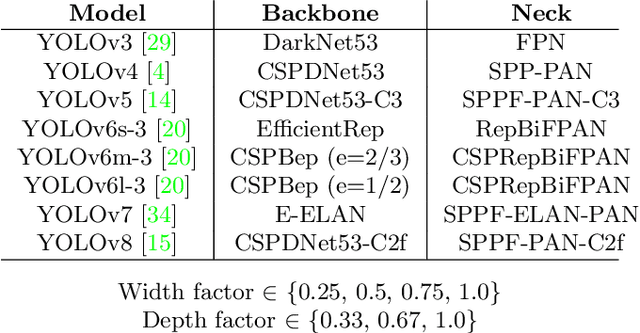
We present YOLOBench, a benchmark comprised of 550+ YOLO-based object detection models on 4 different datasets and 4 different embedded hardware platforms (x86 CPU, ARM CPU, Nvidia GPU, NPU). We collect accuracy and latency numbers for a variety of YOLO-based one-stage detectors at different model scales by performing a fair, controlled comparison of these detectors with a fixed training environment (code and training hyperparameters). Pareto-optimality analysis of the collected data reveals that, if modern detection heads and training techniques are incorporated into the learning process, multiple architectures of the YOLO series achieve a good accuracy-latency trade-off, including older models like YOLOv3 and YOLOv4. We also evaluate training-free accuracy estimators used in neural architecture search on YOLOBench and demonstrate that, while most state-of-the-art zero-cost accuracy estimators are outperformed by a simple baseline like MAC count, some of them can be effectively used to predict Pareto-optimal detection models. We showcase that by using a zero-cost proxy to identify a YOLO architecture competitive against a state-of-the-art YOLOv8 model on a Raspberry Pi 4 CPU. The code and data are available at https://github.com/Deeplite/deeplite-torch-zoo
Dynamic ConvNets on Tiny Devices via Nested Sparsity
Mar 07, 2022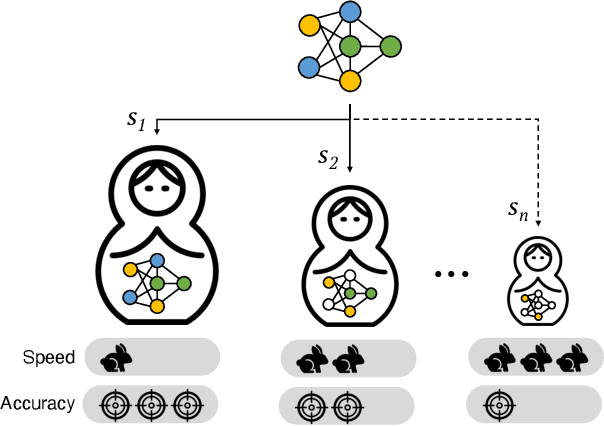
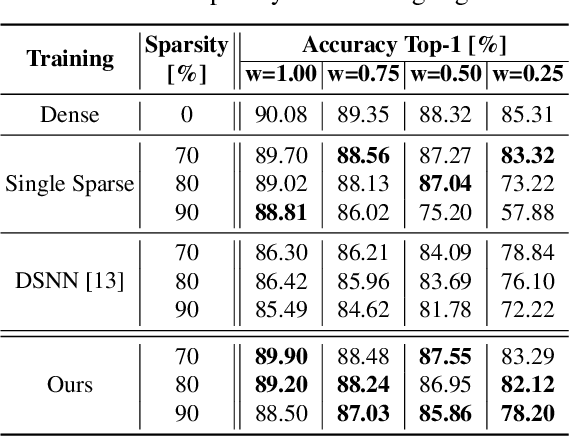
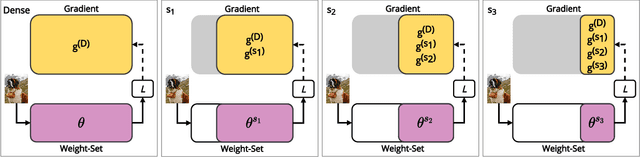

This work introduces a new training and compression pipeline to build Nested Sparse ConvNets, a class of dynamic Convolutional Neural Networks (ConvNets) suited for inference tasks deployed on resource-constrained devices at the edge of the Internet-of-Things. A Nested Sparse ConvNet consists of a single ConvNet architecture containing N sparse sub-networks with nested weights subsets, like a Matryoshka doll, and can trade accuracy for latency at run time, using the model sparsity as a dynamic knob. To attain high accuracy at training time, we propose a gradient masking technique that optimally routes the learning signals across the nested weights subsets. To minimize the storage footprint and efficiently process the obtained models at inference time, we introduce a new sparse matrix compression format with dedicated compute kernels that fruitfully exploit the characteristic of the nested weights subsets. Tested on image classification and object detection tasks on an off-the-shelf ARM-M7 Micro Controller Unit (MCU), Nested Sparse ConvNets outperform variable-latency solutions naively built assembling single sparse models trained as stand-alone instances, achieving (i) comparable accuracy, (ii) remarkable storage savings, and (iii) high performance. Moreover, when compared to state-of-the-art dynamic strategies, like dynamic pruning and layer width scaling, Nested Sparse ConvNets turn out to be Pareto optimal in the accuracy vs. latency space.
EAST: Encoding-Aware Sparse Training for Deep Memory Compression of ConvNets
Dec 20, 2019

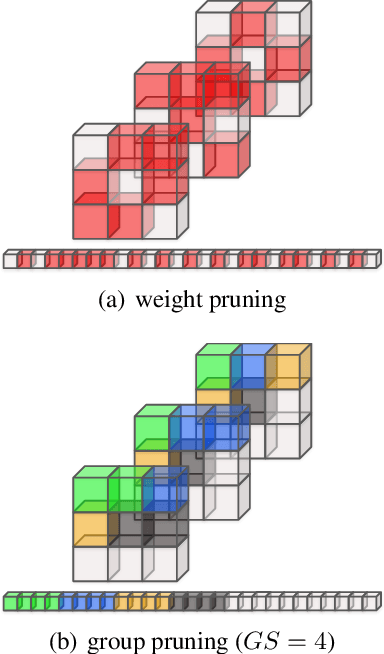
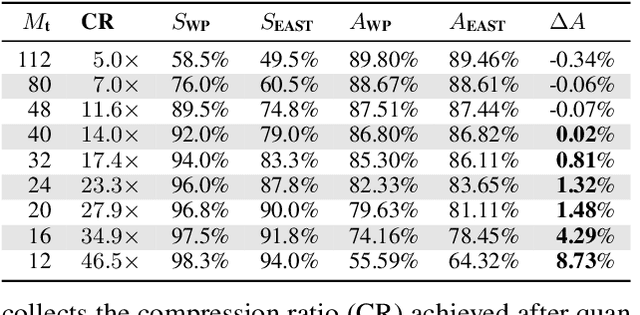
The implementation of Deep Convolutional Neural Networks (ConvNets) on tiny end-nodes with limited non-volatile memory space calls for smart compression strategies capable of shrinking the footprint yet preserving predictive accuracy. There exist a number of strategies for this purpose, from those that play with the topology of the model or the arithmetic precision, e.g. pruning and quantization, to those that operate a model agnostic compression, e.g. weight encoding. The tighter the memory constraint, the higher the probability that these techniques alone cannot meet the requirement, hence more awareness and cooperation across different optimizations become mandatory. This work addresses the issue by introducing EAST, Encoding-Aware Sparse Training, a novel memory-constrained training procedure that leads quantized ConvNets towards deep memory compression. EAST implements an adaptive group pruning designed to maximize the compression rate of the weight encoding scheme (the LZ4 algorithm in this work). If compared to existing methods, EAST meets the memory constraint with lower sparsity, hence ensuring higher accuracy. Results conducted on a state-of-the-art ConvNet (ResNet-9) deployed on a low-power microcontroller (ARM Cortex-M4) validate the proposal.