 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deep Learning Models for Privacy-preserving People Counting on Low-resolution Infrared Arrays
Apr 12, 2023


Ultra-low-resolution Infrared (IR) array sensors offer a low-cost, energy-efficient, and privacy-preserving solution for people counting, with applications such as occupancy monitoring. Previous work has shown that Deep Learning (DL) can yield superior performance on this task. However, the literature was missing an extensive comparative analysis of various efficient DL architectures for IR array-based people counting, that considers not only their accuracy, but also the cost of deploying them on memory- and energy-constrained Internet of Things (IoT) edge nodes. In this work, we address this need by comparing 6 different DL architectures on a novel dataset composed of IR images collected from a commercial 8x8 array, which we made openly available. With a wide architectural exploration of each model type, we obtain a rich set of Pareto-optimal solutions, spanning cross-validated balanced accuracy scores in the 55.70-82.70% range. When deployed on a commercial Microcontroller (MCU) by STMicroelectronics, the STM32L4A6ZG, these models occupy 0.41-9.28kB of memory, and require 1.10-7.74ms per inference, while consuming 17.18-120.43 $\mu$J of energy. Our models are significantly more accurate than a previous deterministic method (up to +39.9%), while being up to 3.53x faster and more energy efficient. Further, our models' accuracy is comparable to state-of-the-art DL solutions on similar resolution sensors, despite a much lower complexity. All our models enable continuous, real-time inference on a MCU-based IoT node, with years of autonomous operation without battery recharging.
Human Activity Recognition on Microcontrollers with Quantized and Adaptive Deep Neural Networks
Sep 02, 2022
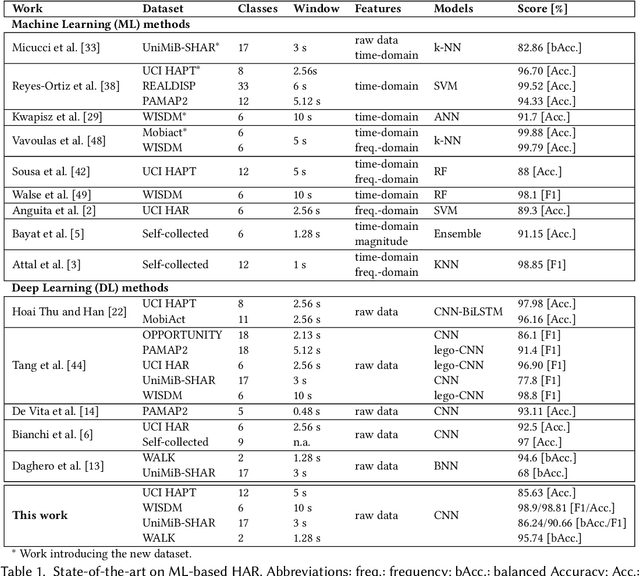

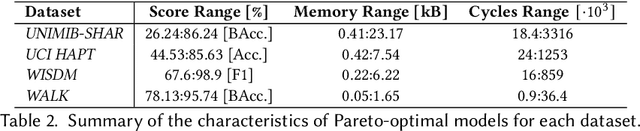
Human Activity Recognition (HAR) based on inertial data is an increasingly diffused task on embedded devices, from smartphones to ultra low-power sensors. Due to the high computational complexity of deep learning models, most embedded HAR systems are based on simple and not-so-accurate classic machine learning algorithms. This work bridges the gap between on-device HAR and deep learning, proposing a set of efficient one-dimensional Convolutional Neural Networks (CNNs) deployable on general purpose microcontrollers (MCUs). Our CNNs are obtained combining hyper-parameters optimization with sub-byte and mixed-precision quantization, to find good trade-offs between classification results and memory occupation. Moreover, we also leverage adaptive inference as an orthogonal optimization to tune the inference complexity at runtime based on the processed input, hence producing a more flexible HAR system. With experiments on four datasets, and targeting an ultra-low-power RISC-V MCU, we show that (i) We are able to obtain a rich set of Pareto-optimal CNNs for HAR, spanning more than 1 order of magnitude in terms of memory, latency and energy consumption; (ii) Thanks to adaptive inference, we can derive >20 runtime operating modes starting from a single CNN, differing by up to 10% in classification scores and by more than 3x in inference complexity, with a limited memory overhead; (iii) on three of the four benchmarks, we outperform all previous deep learning methods, reducing the memory occupation by more than 100x. The few methods that obtain better performance (both shallow and deep) are not compatible with MCU deployment. (iv) All our CNNs are compatible with real-time on-device HAR with an inference latency <16ms. Their memory occupation varies in 0.05-23.17 kB, and their energy consumption in 0.005 and 61.59 uJ, allowing years of continuous operation on a small battery supply.
Adaptive Random Forests for Energy-Efficient Inference on Microcontrollers
May 27, 2022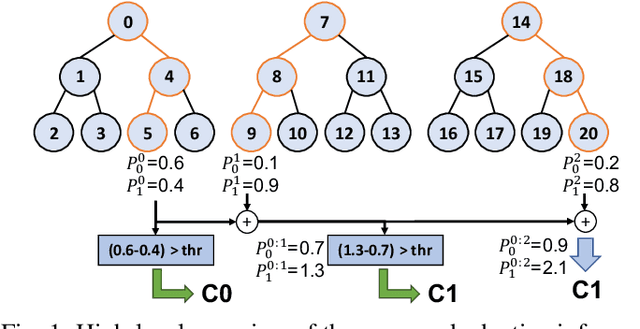
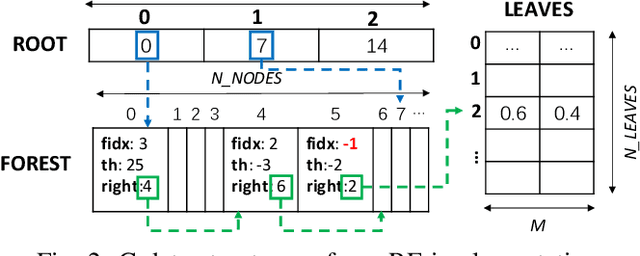
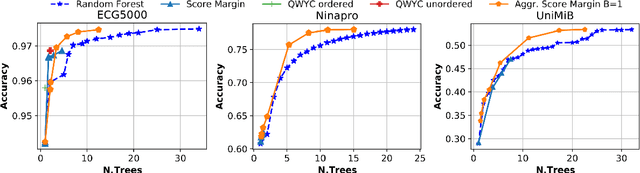

Random Forests (RFs) are widely used Machine Learning models in low-power embedded devices, due to their hardware friendly operation and high accuracy on practically relevant tasks. The accuracy of a RF often increases with the number of internal weak learners (decision trees), but at the cost of a proportional increase in inference latency and energy consumption. Such costs can be mitigated considering that, in most applications, inputs are not all equally difficult to classify. Therefore, a large RF is often necessary only for (few) hard inputs, and wasteful for easier ones. In this work, we propose an early-stopping mechanism for RFs, which terminates the inference as soon as a high-enough classification confidence is reached, reducing the number of weak learners executed for easy inputs. The early-stopping confidence threshold can be controlled at runtime, in order to favor either energy saving or accuracy. We apply our method to three different embedded classification tasks, on a single-core RISC-V microcontroller, achieving an energy reduction from 38% to more than 90% with a drop of less than 0.5% in accuracy. We also show that our approach outperforms previous adaptive ML methods for RFs.
* Published in: 2021 IFIP/IEEE 29th International Conference on Very Large Scale Integration (VLSI-SoC), 2021
Ultra-compact Binary Neural Networks for Human Activity Recognition on RISC-V Processors
May 25, 2022

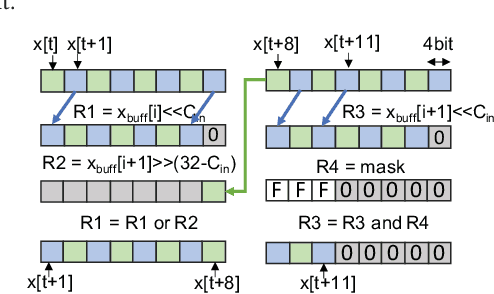

Human Activity Recognition (HAR) is a relevant inference task in many mobile applications. State-of-the-art HAR at the edge is typically achieved with lightweight machine learning models such as decision trees and Random Forests (RFs), whereas deep learning is less common due to its high computational complexity. In this work, we propose a novel implementation of HAR based on deep neural networks, and precisely on Binary Neural Networks (BNNs), targeting low-power general purpose processors with a RISC-V instruction set. BNNs yield very small memory footprints and low inference complexity, thanks to the replacement of arithmetic operations with bit-wise ones. However, existing BNN implementations on general purpose processors impose constraints tailored to complex computer vision tasks, which result in over-parametrized models for simpler problems like HAR. Therefore, we also introduce a new BNN inference library, which targets ultra-compact models explicitly. With experiments on a single-core RISC-V processor, we show that BNNs trained on two HAR datasets obtain higher classification accuracy compared to a state-of-the-art baseline based on RFs. Furthermore, our BNN reaches the same accuracy of a RF with either less memory (up to 91%) or more energy-efficiency (up to 70%), depending on the complexity of the features extracted by the RF.
* Published in: 2021 18th ACM International Conference on Computing Frontiers (CF)
Privacy-preserving Social Distance Monitoring on Microcontrollers with Low-Resolution Infrared Sensors and CNNs
Apr 22, 2022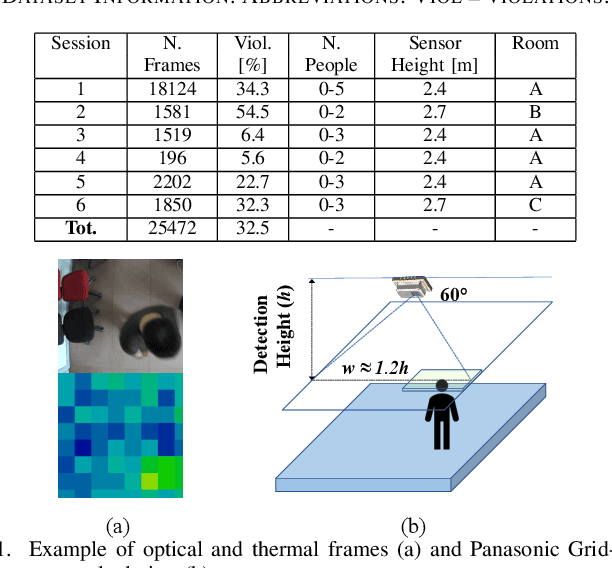


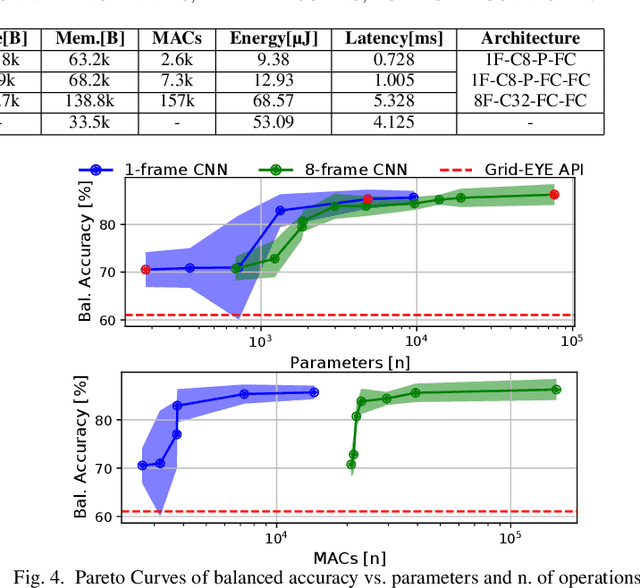
Low-resolution infrared (IR) array sensors offer a low-cost, low-power, and privacy-preserving alternative to optical cameras and smartphones/wearables for social distance monitoring in indoor spaces, permitting the recognition of basic shapes, without revealing the personal details of individuals. In this work, we demonstrate that an accurate detection of social distance violations can be achieved processing the raw output of a 8x8 IR array sensor with a small-sized Convolutional Neural Network (CNN). Furthermore, the CNN can be executed directly on a Microcontroller (MCU)-based sensor node. With results on a newly collected open dataset, we show that our best CNN achieves 86.3% balanced accuracy, significantly outperforming the 61% achieved by a state-of-the-art deterministic algorithm. Changing the architectural parameters of the CNN, we obtain a rich Pareto set of models, spanning 70.5-86.3% accuracy and 0.18-75k parameters. Deployed on a STM32L476RG MCU, these models have a latency of 0.73-5.33ms, with an energy consumption per inference of 9.38-68.57{\mu}J.
Energy-efficient and Privacy-aware Social Distance Monitoring with Low-resolution Infrared Sensors and Adaptive Inference
Apr 22, 2022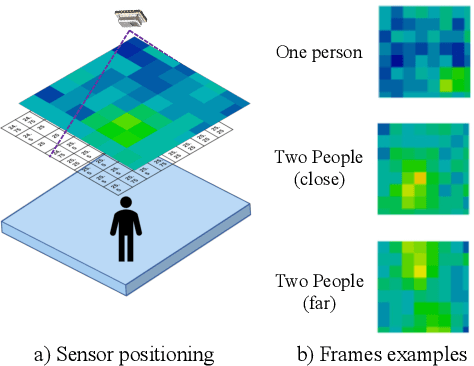

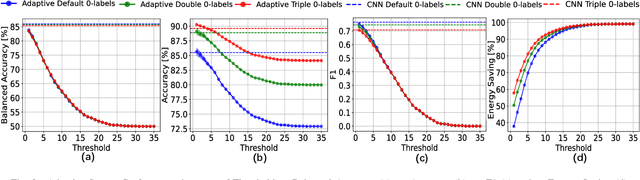

Low-resolution infrared (IR) Sensors combined with machine learning (ML) can be leveraged to implement privacy-preserving social distance monitoring solutions in indoor spaces. However, the need of executing these applications on Internet of Things (IoT) edge nodes makes energy consumption critical. In this work, we propose an energy-efficient adaptive inference solution consisting of the cascade of a simple wake-up trigger and a 8-bit quantized Convolutional Neural Network (CNN), which is only invoked for difficult-to-classify frames. Deploying such adaptive system on a IoT Microcontroller, we show that, when processing the output of a 8x8 low-resolution IR sensor, we are able to reduce the energy consumption by 37-57% with respect to a static CNN-based approach, with an accuracy drop of less than 2% (83% balanced accuracy).
Dynamic ConvNets on Tiny Devices via Nested Sparsity
Mar 07, 2022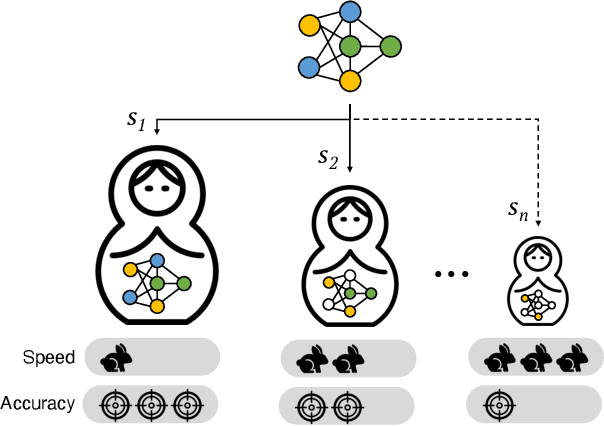
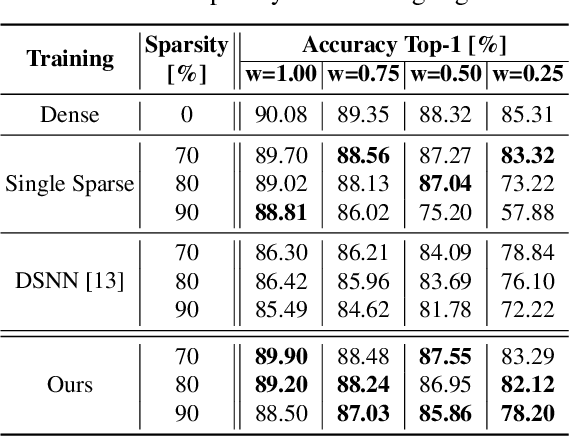
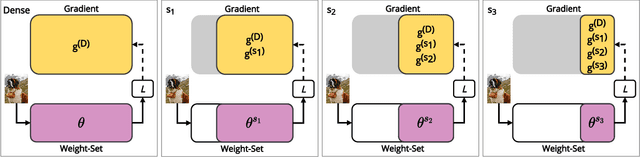

This work introduces a new training and compression pipeline to build Nested Sparse ConvNets, a class of dynamic Convolutional Neural Networks (ConvNets) suited for inference tasks deployed on resource-constrained devices at the edge of the Internet-of-Things. A Nested Sparse ConvNet consists of a single ConvNet architecture containing N sparse sub-networks with nested weights subsets, like a Matryoshka doll, and can trade accuracy for latency at run time, using the model sparsity as a dynamic knob. To attain high accuracy at training time, we propose a gradient masking technique that optimally routes the learning signals across the nested weights subsets. To minimize the storage footprint and efficiently process the obtained models at inference time, we introduce a new sparse matrix compression format with dedicated compute kernels that fruitfully exploit the characteristic of the nested weights subsets. Tested on image classification and object detection tasks on an off-the-shelf ARM-M7 Micro Controller Unit (MCU), Nested Sparse ConvNets outperform variable-latency solutions naively built assembling single sparse models trained as stand-alone instances, achieving (i) comparable accuracy, (ii) remarkable storage savings, and (iii) high performance. Moreover, when compared to state-of-the-art dynamic strategies, like dynamic pruning and layer width scaling, Nested Sparse ConvNets turn out to be Pareto optimal in the accuracy vs. latency space.
Adaptive Test-Time Augmentation for Low-Power CPU
May 13, 2021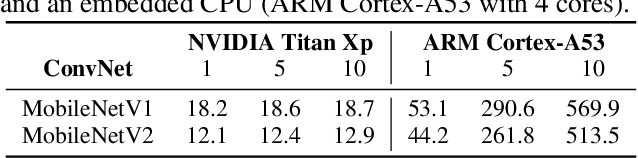
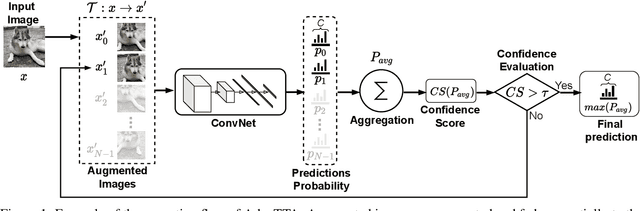

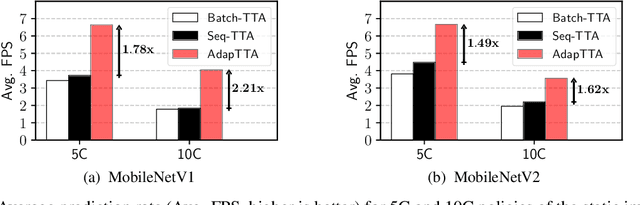
Convolutional Neural Networks (ConvNets) are trained offline using the few available data and may therefore suffer from substantial accuracy loss when ported on the field, where unseen input patterns received under unpredictable external conditions can mislead the model. Test-Time Augmentation (TTA) techniques aim to alleviate such common side effect at inference-time, first running multiple feed-forward passes on a set of altered versions of the same input sample, and then computing the main outcome through a consensus of the aggregated predictions. Unfortunately, the implementation of TTA on embedded CPUs introduces latency penalties that limit its adoption on edge applications. To tackle this issue, we propose AdapTTA, an adaptive implementation of TTA that controls the number of feed-forward passes dynamically, depending on the complexity of the input. Experimental results on state-of-the-art ConvNets for image classification deployed on a commercial ARM Cortex-A CPU demonstrate AdapTTA reaches remarkable latency savings, from 1.49X to 2.21X, and hence a higher frame rate compared to static TTA, still preserving the same accuracy gain.
TentacleNet: A Pseudo-Ensemble Template for Accurate Binary Convolutional Neural Networks
Dec 26, 2019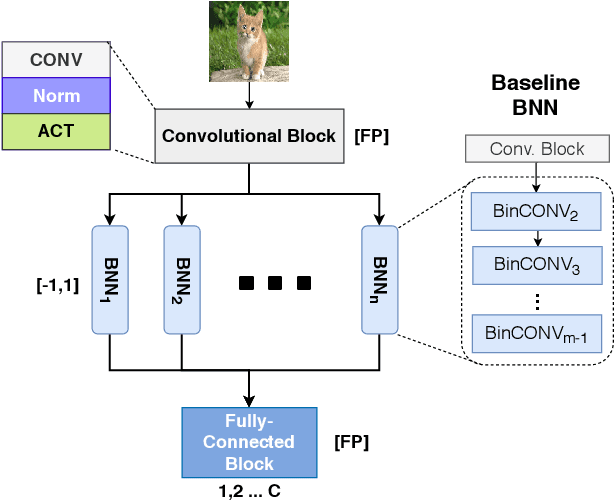
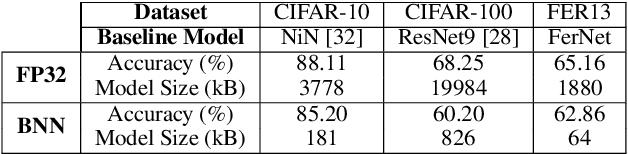
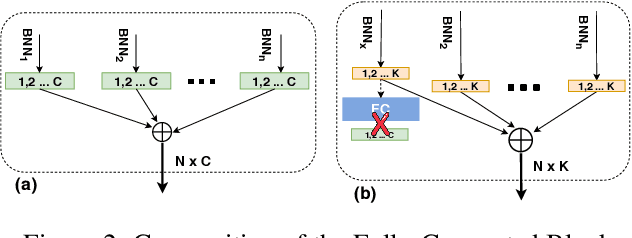
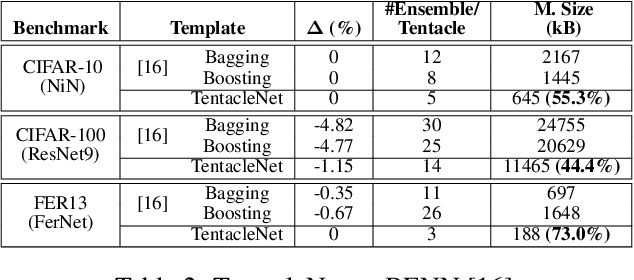
Binarization is an attractive strategy for implementing lightweight Deep Convolutional Neural Networks (CNNs). Despite the unquestionable savings offered, memory footprint above all, it may induce an excessive accuracy loss that prevents a widespread use. This work elaborates on this aspect introducing TentacleNet, a new template designed to improve the predictive performance of binarized CNNs via parallelization. Inspired by the ensemble learning theory, it consists of a compact topology that is end-to-end trainable and organized to minimize memory utilization. Experimental results collected over three realistic benchmarks show TentacleNet fills the gap left by classical binary models, ensuring substantial memory savings w.r.t. state-of-the-art binary ensemble methods.
EAST: Encoding-Aware Sparse Training for Deep Memory Compression of ConvNets
Dec 20, 2019

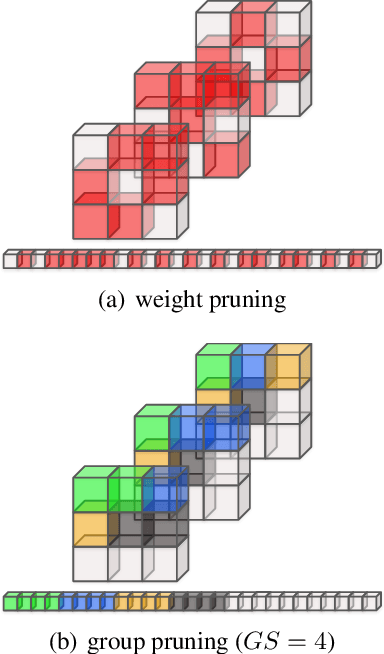
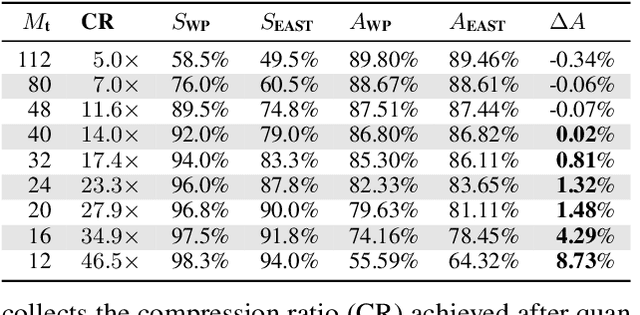
The implementation of Deep Convolutional Neural Networks (ConvNets) on tiny end-nodes with limited non-volatile memory space calls for smart compression strategies capable of shrinking the footprint yet preserving predictive accuracy. There exist a number of strategies for this purpose, from those that play with the topology of the model or the arithmetic precision, e.g. pruning and quantization, to those that operate a model agnostic compression, e.g. weight encoding. The tighter the memory constraint, the higher the probability that these techniques alone cannot meet the requirement, hence more awareness and cooperation across different optimizations become mandatory. This work addresses the issue by introducing EAST, Encoding-Aware Sparse Training, a novel memory-constrained training procedure that leads quantized ConvNets towards deep memory compression. EAST implements an adaptive group pruning designed to maximize the compression rate of the weight encoding scheme (the LZ4 algorithm in this work). If compared to existing methods, EAST meets the memory constraint with lower sparsity, hence ensuring higher accuracy. Results conducted on a state-of-the-art ConvNet (ResNet-9) deployed on a low-power microcontroller (ARM Cortex-M4) validate the proposal.