 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't be so Stief! Learning KV Cache low-rank approximation over the Stiefel manifold
Jan 29, 2026Key--value (KV) caching enables fast autoregressive decoding but at long contexts becomes a dominant bottleneck in High Bandwidth Memory (HBM) capacity and bandwidth. A common mitigation is to compress cached keys and values by projecting per-head matrixes to a lower rank, storing only the projections in the HBM. However, existing post-training approaches typically fit these projections using SVD-style proxy objectives, which may poorly reflect end-to-end reconstruction after softmax, value mixing, and subsequent decoder-layer transformations. For these reasons, we introduce StiefAttention, a post-training KV-cache compression method that learns \emph{orthonormal} projection bases by directly minimizing \emph{decoder-layer output reconstruction error}. StiefAttention additionally precomputes, for each layer, an error-rank profile over candidate ranks, enabling flexible layer-wise rank allocation under a user-specified error budget. Noteworthy, on Llama3-8B under the same conditions, StiefAttention outperforms EigenAttention by $11.9$ points on C4 perplexity and $5.4\%$ on 0-shot MMLU accuracy at iso-compression, yielding lower relative error and higher cosine similarity with respect to the original decoder-layer outputs.
Lightweight Test-Time Adaptation for EMG-Based Gesture Recognition
Jan 07, 2026Reliable long-term decoding of surface electromyography (EMG) is hindered by signal drift caused by electrode shifts, muscle fatigue, and posture changes. While state-of-the-art models achieve high intra-session accuracy, their performance often degrades sharply. Existing solutions typically demand large datasets or high-compute pipelines that are impractical for energy-efficient wearables. We propose a lightweight framework for Test-Time Adaptation (TTA) using a Temporal Convolutional Network (TCN) backbone. We introduce three deployment-ready strategies: (i) causal adaptive batch normalization for real-time statistical alignment; (ii) a Gaussian Mixture Model (GMM) alignment with experience replay to prevent forgetting; and (iii) meta-learning for rapid, few-shot calibration. Evaluated on the NinaPro DB6 multi-session dataset, our framework significantly bridges the inter-session accuracy gap with minimal overhead. Our results show that experience-replay updates yield superior stability under limited data, while meta-learning achieves competitive performance in one- and two-shot regimes using only a fraction of the data required by current benchmarks. This work establishes a path toward robust, "plug-and-play" myoelectric control for long-term prosthetic use.
Automatic integration of SystemC in the FMI standard for Software-defined Vehicle design
Aug 27, 2025The recent advancements of the automotive sector demand robust co-simulation methodologies that enable early validation and seamless integration across hardware and software domains. However, the lack of standardized interfaces and the dominance of proprietary simulation platforms pose significant challenges to collaboration, scalability, and IP protection. To address these limitations, this paper presents an approach for automatically wrapping SystemC models by using the Functional Mock-up Interface (FMI) standard. This method combines the modeling accuracy and fast time-to-market of SystemC with the interoperability and encapsulation benefits of FMI, enabling secure and portable integration of embedded components into co-simulation workflows. We validate the proposed methodology on real-world case studies, demonstrating its effectiveness with complex designs.
MEbots: Integrating a RISC-V Virtual Platform with a Robotic Simulator for Energy-aware Design
May 22, 2025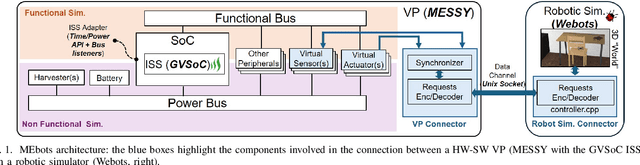
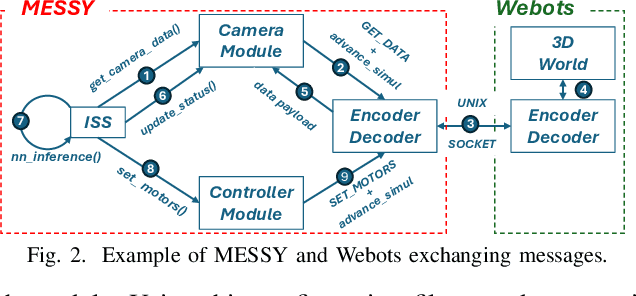
Virtual Platforms (VPs) enable early software validation of autonomous systems' electronics, reducing costs and time-to-market. While many VPs support both functional and non-functional simulation (e.g., timing, power), they lack the capability of simulating the environment in which the system operates. In contrast, robotics simulators lack accurate timing and power features. This twofold shortcoming limits the effectiveness of the design flow, as the designer can not fully evaluate the features of the solution under development. This paper presents a novel, fully open-source framework bridging this gap by integrating a robotics simulator (Webots) with a VP for RISC-V-based systems (MESSY). The framework enables a holistic, mission-level, energy-aware co-simulation of electronics in their surrounding environment, streamlining the exploration of design configurations and advanced power management policies.
Lightweight Software Kernels and Hardware Extensions for Efficient Sparse Deep Neural Networks on Microcontrollers
Mar 08, 2025The acceleration of pruned Deep Neural Networks (DNNs) on edge devices such as Microcontrollers (MCUs) is a challenging task, given the tight area- and power-constraints of these devices. In this work, we propose a three-fold contribution to address this problem. First, we design a set of optimized software kernels for N:M pruned layers, targeting ultra-low-power, multicore RISC-V MCUs, which are up to 2.1x and 3.4x faster than their dense counterparts at 1:8 and 1:16 sparsity, respectively. Then, we implement a lightweight Instruction-Set Architecture (ISA) extension to accelerate the indirect load and non-zero indices decompression operations required by our kernels, obtaining up to 1.9x extra speedup, at the cost of a 5% area overhead. Lastly, we extend an open-source DNN compiler to utilize our sparse kernels for complete networks, showing speedups of 3.21x and 1.81x on a ResNet18 and a Vision Transformer (ViT), with less than 1.5% accuracy drop compared to a dense baseline.
Coupling Neural Networks and Physics Equations For Li-Ion Battery State-of-Charge Prediction
Dec 21, 2024



Estimating the evolution of the battery's State of Charge (SoC) in response to its usage is critical for implementing effective power management policies and for ultimately improving the system's lifetime. Most existing estimation methods are either physics-based digital twins of the battery or data-driven models such as Neural Networks (NNs). In this work, we propose two new contributions in this domain. First, we introduce a novel NN architecture formed by two cascaded branches: one to predict the current SoC based on sensor readings, and one to estimate the SoC at a future time as a function of the load behavior. Second, we integrate battery dynamics equations into the training of our NN, merging the physics-based and data-driven approaches, to improve the models' generalization over variable prediction horizons. We validate our approach on two publicly accessible datasets, showing that our Physics-Informed Neural Networks (PINNs) outperform purely data-driven ones while also obtaining superior prediction accuracy with a smaller architecture with respect to the state-of-the-art.
EnhancePPG: Improving PPG-based Heart Rate Estimation with Self-Supervision and Augmentation
Dec 20, 2024



Heart rate (HR) estimation from photoplethysmography (PPG) signals is a key feature of modern wearable devices for health and wellness monitoring. While deep learning models show promise, their performance relies on the availability of large datasets. We present EnhancePPG, a method that enhances state-of-the-art models by integrating self-supervised learning with data augmentation (DA). Our approach combines self-supervised pre-training with DA, allowing the model to learn more generalizable features, without needing more labelled data. Inspired by a U-Net-like autoencoder architecture, we utilize unsupervised PPG signal reconstruction, taking advantage of large amounts of unlabeled data during the pre-training phase combined with data augmentation, to improve state-of-the-art models' performance. Thanks to our approach and minimal modification to the state-of-the-art model, we improve the best HR estimation by 12.2%, lowering from 4.03 Beats-Per-Minute (BPM) to 3.54 BPM the error on PPG-DaLiA. Importantly, our EnhancePPG approach focuses exclusively on the training of the selected deep learning model, without significantly increasing its inference latency
MATCH: Model-Aware TVM-based Compilation for Heterogeneous Edge Devices
Oct 11, 2024



Streamlining the deployment of Deep Neural Networks (DNNs) on heterogeneous edge platforms, coupling within the same micro-controller unit (MCU) instruction processors and hardware accelerators for tensor computations, is becoming one of the crucial challenges of the TinyML field. The best-performing DNN compilation toolchains are usually deeply customized for a single MCU family, and porting to a different heterogeneous MCU family implies labor-intensive re-development of almost the entire compiler. On the opposite side, retargetable toolchains, such as TVM, fail to exploit the capabilities of custom accelerators, resulting in the generation of general but unoptimized code. To overcome this duality, we introduce MATCH, a novel TVM-based DNN deployment framework designed for easy agile retargeting across different MCU processors and accelerators, thanks to a customizable model-based hardware abstraction. We show that a general and retargetable mapping framework enhanced with hardware cost models can compete with and even outperform custom toolchains on diverse targets while only needing the definition of an abstract hardware model and a SoC-specific API. We tested MATCH on two state-of-the-art heterogeneous MCUs, GAP9 and DIANA. On the four DNN models of the MLPerf Tiny suite MATCH reduces inference latency by up to 60.88 times on DIANA, compared to using the plain TVM, thanks to the exploitation of the on-board HW accelerator. Compared to HTVM, a fully customized toolchain for DIANA, we still reduce the latency by 16.94%. On GAP9, using the same benchmarks, we improve the latency by 2.15 times compared to the dedicated DORY compiler, thanks to our heterogeneous DNN mapping approach that synergically exploits the DNN accelerator and the eight-cores cluster available on board.
Building Damage Assessment in Conflict Zones: A Deep Learning Approach Using Geospatial Sub-Meter Resolution Data
Oct 07, 2024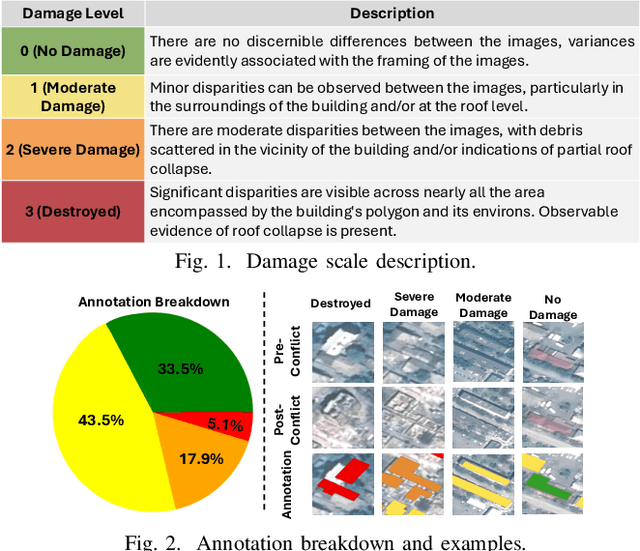
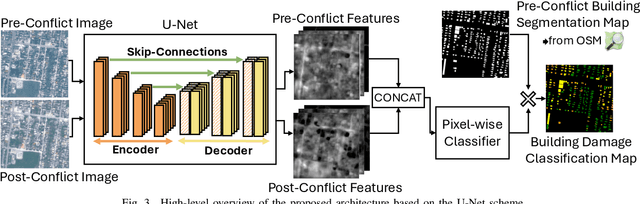
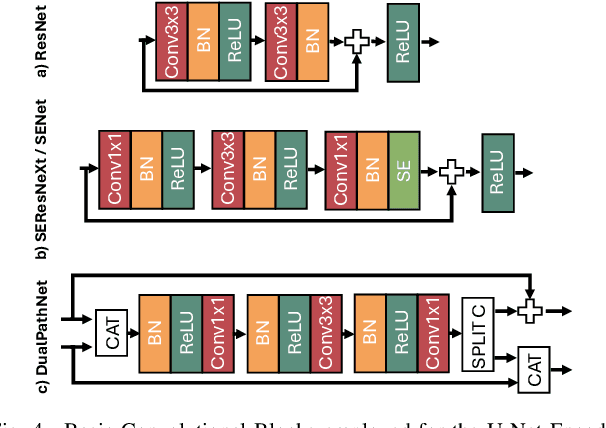
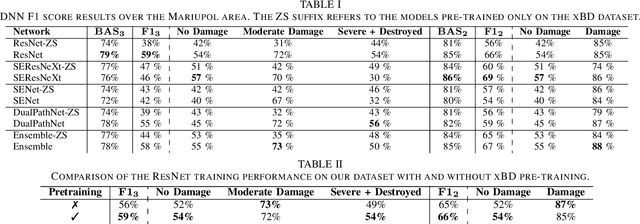
Very High Resolution (VHR) geospatial image analysis is crucial for humanitarian assistance in both natural and anthropogenic crises, as it allows to rapidly identify the most critical areas that need support. Nonetheless, manually inspecting large areas is time-consuming and requires domain expertise. Thanks to their accuracy, generalization capabilities, and highly parallelizable workload, Deep Neural Networks (DNNs) provide an excellent way to automate this task. Nevertheless, there is a scarcity of VHR data pertaining to conflict situations, and consequently, of studies on the effectiveness of DNNs in those scenarios. Motivated by this, our work extensively studies the applicability of a collection of state-of-the-art Convolutional Neural Networks (CNNs) originally developed for natural disasters damage assessment in a war scenario. To this end, we build an annotated dataset with pre- and post-conflict images of the Ukrainian city of Mariupol. We then explore the transferability of the CNN models in both zero-shot and learning scenarios, demonstrating their potential and limitations. To the best of our knowledge, this is the first study to use sub-meter resolution imagery to assess building damage in combat zones.
Optimizing DNN Inference on Multi-Accelerator SoCs at Training-time
Sep 27, 2024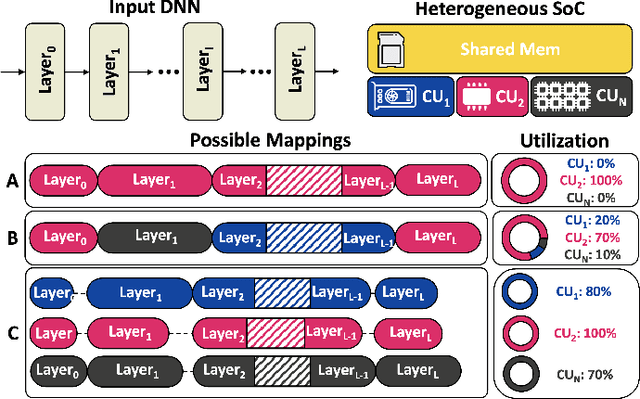
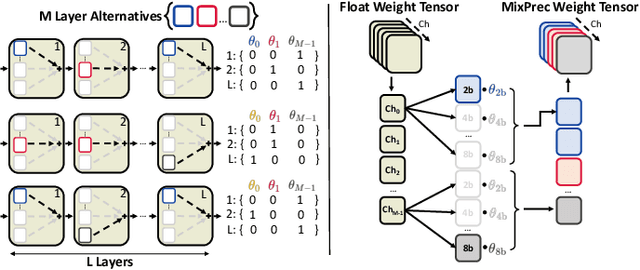
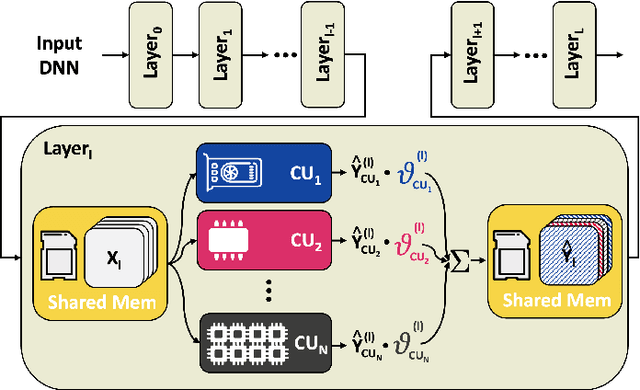
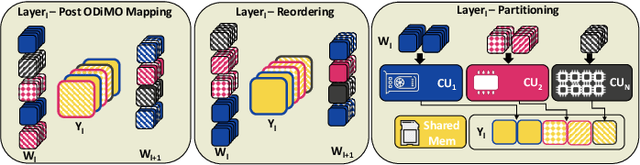
The demand for executing Deep Neural Networks (DNNs) with low latency and minimal power consumption at the edge has led to the development of advanced heterogeneous Systems-on-Chips (SoCs) that incorporate multiple specialized computing units (CUs), such as accelerators. Offloading DNN computations to a specific CU from the available set often exposes accuracy vs efficiency trade-offs, due to differences in their supported operations (e.g., standard vs. depthwise convolution) or data representations (e.g., more/less aggressively quantized). A challenging yet unresolved issue is how to map a DNN onto these multi-CU systems to maximally exploit the parallelization possibilities while taking accuracy into account. To address this problem, we present ODiMO, a hardware-aware tool that efficiently explores fine-grain mapping of DNNs among various on-chip CUs, during the training phase. ODiMO strategically splits individual layers of the neural network and executes them in parallel on the multiple available CUs, aiming to balance the total inference energy consumption or latency with the resulting accuracy, impacted by the unique features of the different hardware units. We test our approach on CIFAR-10, CIFAR-100, and ImageNet, targeting two open-source heterogeneous SoCs, i.e., DIANA and Darkside. We obtain a rich collection of Pareto-optimal networks in the accuracy vs. energy or latency space. We show that ODiMO reduces the latency of a DNN executed on the Darkside SoC by up to 8x at iso-accuracy, compared to manual heuristic mappings. When targeting energy, on the same SoC, ODiMO produced up to 50.8x more efficient mappings, with minimal accuracy drop (< 0.3%).