 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeploy: Enabling Energy-Efficient Deployment of Small Language Models On Heterogeneous Microcontrollers
Aug 08, 2024



With the rise of Embodied Foundation Models (EFMs), most notably Small Language Models (SLMs), adapting Transformers for edge applications has become a very active field of research. However, achieving end-to-end deployment of SLMs on microcontroller (MCU)-class chips without high-bandwidth off-chip main memory access is still an open challenge. In this paper, we demonstrate high-efficiency end-to-end SLM deployment on a multicore RISC-V (RV32) MCU augmented with ML instruction extensions and a hardware neural processing unit (NPU). To automate the exploration of the constrained, multi-dimensional memory vs. computation tradeoffs involved in aggressive SLM deployment on heterogeneous (multicore+NPU) resources, we introduce Deeploy, a novel Deep Neural Network (DNN) compiler, which generates highly-optimized C code requiring minimal runtime support. We demonstrate that Deeploy generates end-to-end code for executing SLMs, fully exploiting the RV32 cores' instruction extensions and the NPU: We achieve leading-edge energy and throughput of \SI{490}{\micro\joule \per Token}, at \SI{340}{Token \per \second} for an SLM trained on the TinyStories dataset, running for the first time on an MCU-class device without external memory.
Toward Attention-based TinyML: A Heterogeneous Accelerated Architecture and Automated Deployment Flow
Aug 05, 2024One of the challenges for Tiny Machine Learning (tinyML) is keeping up with the evolution of Machine Learning models from Convolutional Neural Networks to Transformers. We address this by leveraging a heterogeneous architectural template coupling RISC-V processors with hardwired accelerators supported by an automated deployment flow. We demonstrate an Attention-based model in a tinyML power envelope with an octa-core cluster coupled with an accelerator for quantized Attention. Our deployment flow enables an end-to-end 8-bit MobileBERT, achieving leading-edge energy efficiency and throughput of 2960 GOp/J and 154 GOp/s at 32.5 Inf/s consuming 52.0 mW (0.65 V, 22 nm FD-SOI technology).
xTern: Energy-Efficient Ternary Neural Network Inference on RISC-V-Based Edge Systems
May 29, 2024



Ternary neural networks (TNNs) offer a superior accuracy-energy trade-off compared to binary neural networks. However, until now, they have required specialized accelerators to realize their efficiency potential, which has hindered widespread adoption. To address this, we present xTern, a lightweight extension of the RISC-V instruction set architecture (ISA) targeted at accelerating TNN inference on general-purpose cores. To complement the ISA extension, we developed a set of optimized kernels leveraging xTern, achieving 67% higher throughput than their 2-bit equivalents. Power consumption is only marginally increased by 5.2%, resulting in an energy efficiency improvement by 57.1%. We demonstrate that the proposed xTern extension, integrated into an octa-core compute cluster, incurs a minimal silicon area overhead of 0.9% with no impact on timing. In end-to-end benchmarks, we demonstrate that xTern enables the deployment of TNNs achieving up to 1.6 percentage points higher CIFAR-10 classification accuracy than 2-bit networks at equal inference latency. Our results show that xTern enables RISC-V-based ultra-low-power edge AI platforms to benefit from the efficiency potential of TNNs.
Optimizing the Deployment of Tiny Transformers on Low-Power MCUs
Apr 03, 2024


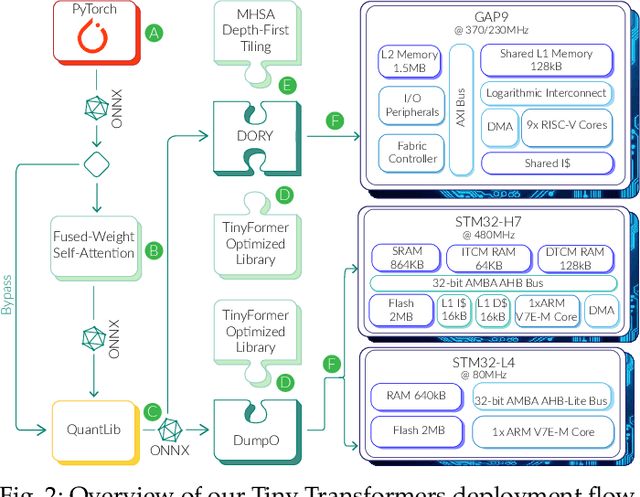
Transformer networks are rapidly becoming SotA in many fields, such as NLP and CV. Similarly to CNN, there is a strong push for deploying Transformer models at the extreme edge, ultimately fitting the tiny power budget and memory footprint of MCUs. However, the early approaches in this direction are mostly ad-hoc, platform, and model-specific. This work aims to enable and optimize the flexible, multi-platform deployment of encoder Tiny Transformers on commercial MCUs. We propose a complete framework to perform end-to-end deployment of Transformer models onto single and multi-core MCUs. Our framework provides an optimized library of kernels to maximize data reuse and avoid unnecessary data marshaling operations into the crucial attention block. A novel MHSA inference schedule, named Fused-Weight Self-Attention, is introduced, fusing the linear projection weights offline to further reduce the number of operations and parameters. Furthermore, to mitigate the memory peak reached by the computation of the attention map, we present a Depth-First Tiling scheme for MHSA. We evaluate our framework on three different MCU classes exploiting ARM and RISC-V ISA, namely the STM32H7, the STM32L4, and GAP9 (RV32IMC-XpulpV2). We reach an average of 4.79x and 2.0x lower latency compared to SotA libraries CMSIS-NN (ARM) and PULP-NN (RISC-V), respectively. Moreover, we show that our MHSA depth-first tiling scheme reduces the memory peak by up to 6.19x, while the fused-weight attention can reduce the runtime by 1.53x, and number of parameters by 25%. We report significant improvements across several Tiny Transformers: for instance, when executing a transformer block for the task of radar-based hand-gesture recognition on GAP9, we achieve a latency of 0.14ms and energy consumption of 4.92 micro-joules, 2.32x lower than the SotA PULP-NN library on the same platform.
ITA: An Energy-Efficient Attention and Softmax Accelerator for Quantized Transformers
Jul 10, 2023



Transformer networks have emerged as the state-of-the-art approach for natural language processing tasks and are gaining popularity in other domains such as computer vision and audio processing. However, the efficient hardware acceleration of transformer models poses new challenges due to their high arithmetic intensities, large memory requirements, and complex dataflow dependencies. In this work, we propose ITA, a novel accelerator architecture for transformers and related models that targets efficient inference on embedded systems by exploiting 8-bit quantization and an innovative softmax implementation that operates exclusively on integer values. By computing on-the-fly in streaming mode, our softmax implementation minimizes data movement and energy consumption. ITA achieves competitive energy efficiency with respect to state-of-the-art transformer accelerators with 16.9 TOPS/W, while outperforming them in area efficiency with 5.93 TOPS/mm$^2$ in 22 nm fully-depleted silicon-on-insulator technology at 0.8 V.
Bioformers: Embedding Transformers for Ultra-Low Power sEMG-based Gesture Recognition
Mar 25, 2022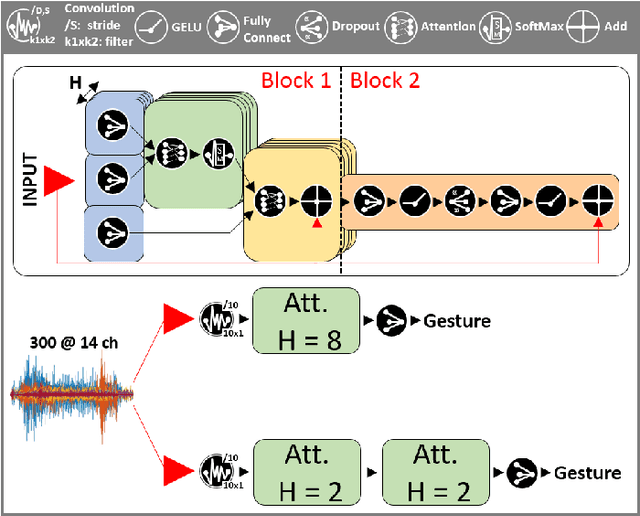
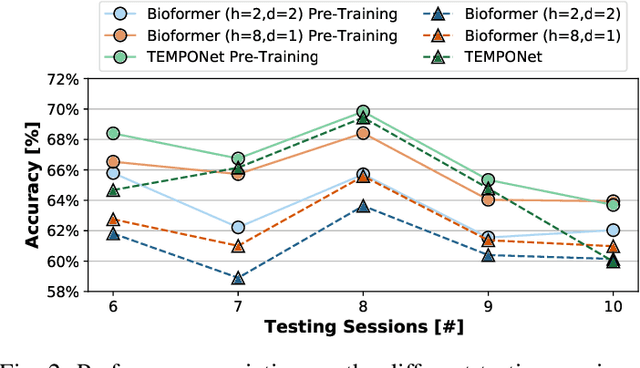
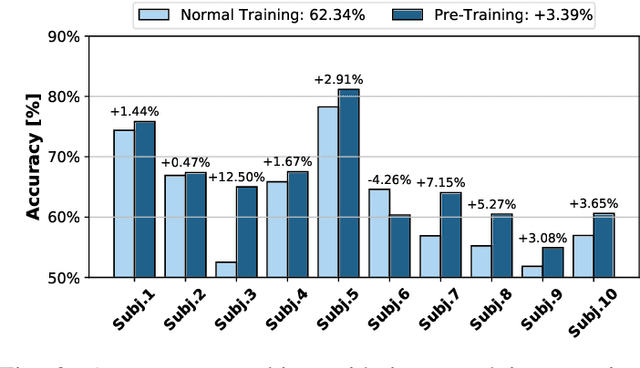
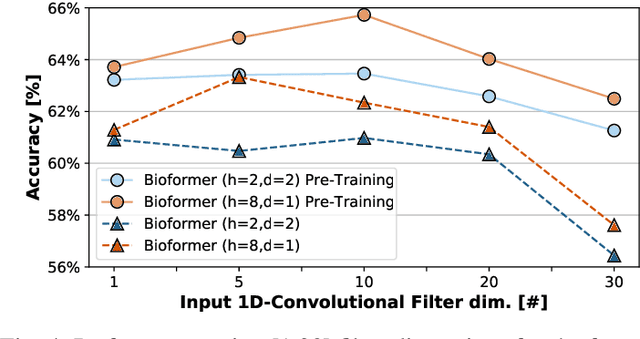
Human-machine interaction is gaining traction in rehabilitation tasks, such as controlling prosthetic hands or robotic arms. Gesture recognition exploiting surface electromyographic (sEMG) signals is one of the most promising approaches, given that sEMG signal acquisition is non-invasive and is directly related to muscle contraction. However, the analysis of these signals still presents many challenges since similar gestures result in similar muscle contractions. Thus the resulting signal shapes are almost identical, leading to low classification accuracy. To tackle this challenge, complex neural networks are employed, which require large memory footprints, consume relatively high energy and limit the maximum battery life of devices used for classification. This work addresses this problem with the introduction of the Bioformers. This new family of ultra-small attention-based architectures approaches state-of-the-art performance while reducing the number of parameters and operations of 4.9X. Additionally, by introducing a new inter-subjects pre-training, we improve the accuracy of our best Bioformer by 3.39%, matching state-of-the-art accuracy without any additional inference cost. Deploying our best performing Bioformer on a Parallel, Ultra-Low Power (PULP) microcontroller unit (MCU), the GreenWaves GAP8, we achieve an inference latency and energy of 2.72 ms and 0.14 mJ, respectively, 8.0X lower than the previous state-of-the-art neural network, while occupying just 94.2 kB of memory.
TinyRadarNN: Combining Spatial and Temporal Convolutional Neural Networks for Embedded Gesture Recognition with Short Range Radars
Jun 25, 2020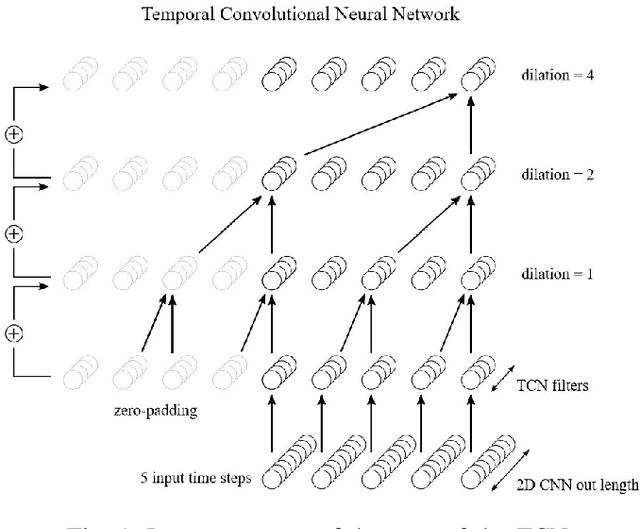
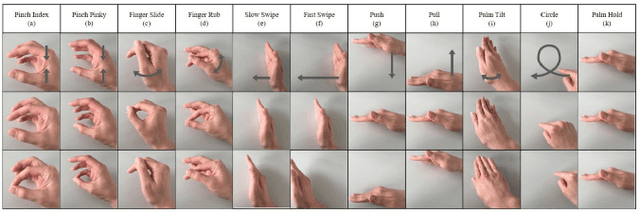
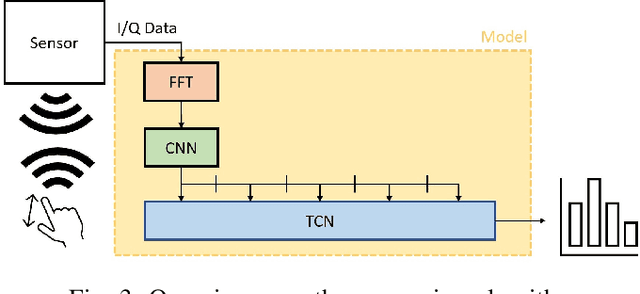
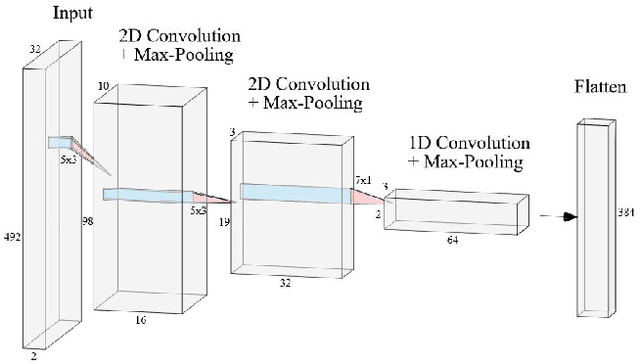
This work proposes a low-power high-accuracy embedded hand-gesture recognition algorithm targeting battery-operated wearable devices using low power short-range RADAR sensors. A 2D Convolutional Neural Network (CNN) using range frequency Doppler features is combined with a Temporal Convolutional Neural Network (TCN) for time sequence prediction. The final algorithm has a model size of only 46 thousand parameters, yielding a memory footprint of only 92 KB. Two datasets containing 11 challenging hand gestures performed by 26 different people have been recorded containing a total of 20,210 gesture instances. On the 11 hand gesture dataset, accuracies of 86.6% (26 users) and 92.4% (single user) have been achieved, which are comparable to the state-of-the-art, which achieves 87% (10 users) and 94% (single user), while using a TCN-based network that is 7500x smaller than the state-of-the-art. Furthermore, the gesture recognition classifier has been implemented on Parallel Ultra-Low Power Processor, demonstrating that real-time prediction is feasible with only 21 mW of power consumption for the full TCN sequence prediction network.