 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEXP: A Low-Cost RISC-V ISA Extension for Accelerated Softmax Computation in Transformers
Apr 15, 2025While Transformers are dominated by Floating-Point (FP) Matrix-Multiplications, their aggressive acceleration through dedicated hardware or many-core programmable systems has shifted the performance bottleneck to non-linear functions like Softmax. Accelerating Softmax is challenging due to its non-pointwise, non-linear nature, with exponentiation as the most demanding step. To address this, we design a custom arithmetic block for Bfloat16 exponentiation leveraging a novel approximation algorithm based on Schraudolph's method, and we integrate it into the Floating-Point Unit (FPU) of the RISC-V cores of a compute cluster, through custom Instruction Set Architecture (ISA) extensions, with a negligible area overhead of 1\%. By optimizing the software kernels to leverage the extension, we execute Softmax with 162.7$\times$ less latency and 74.3$\times$ less energy compared to the baseline cluster, achieving an 8.2$\times$ performance improvement and 4.1$\times$ higher energy efficiency for the FlashAttention-2 kernel in GPT-2 configuration. Moreover, the proposed approach enables a multi-cluster system to efficiently execute end-to-end inference of pre-trained Transformer models, such as GPT-2, GPT-3 and ViT, achieving up to 5.8$\times$ and 3.6$\times$ reduction in latency and energy consumption, respectively, without requiring re-training and with negligible accuracy loss.
Open-Source Heterogeneous SoCs for AI: The PULP Platform Experience
Dec 29, 2024



Since 2013, the PULP (Parallel Ultra-Low Power) Platform project has been one of the most active and successful initiatives in designing research IPs and releasing them as open-source. Its portfolio now ranges from processor cores to network-on-chips, peripherals, SoC templates, and full hardware accelerators. In this article, we focus on the PULP experience designing heterogeneous AI acceleration SoCs - an endeavour encompassing SoC architecture definition; development, verification, and integration of acceleration IPs; front- and back-end VLSI design; testing; development of AI deployment software.
Unleashing OpenTitan's Potential: a Silicon-Ready Embedded Secure Element for Root of Trust and Cryptographic Offloading
Jun 17, 2024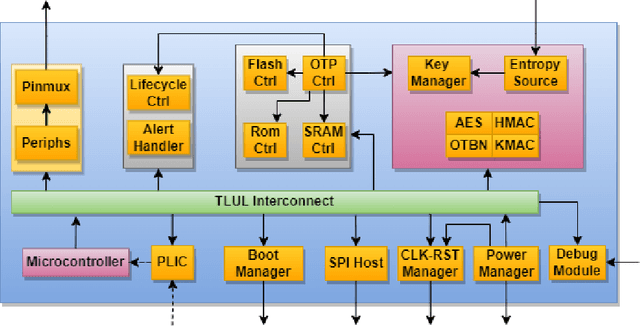

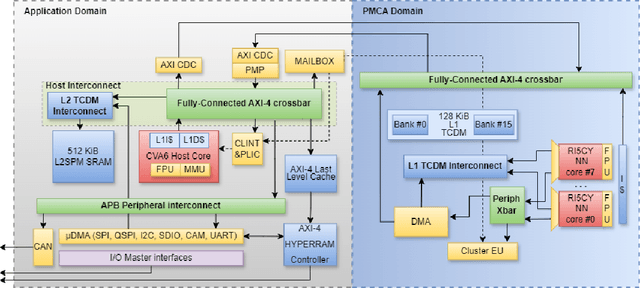
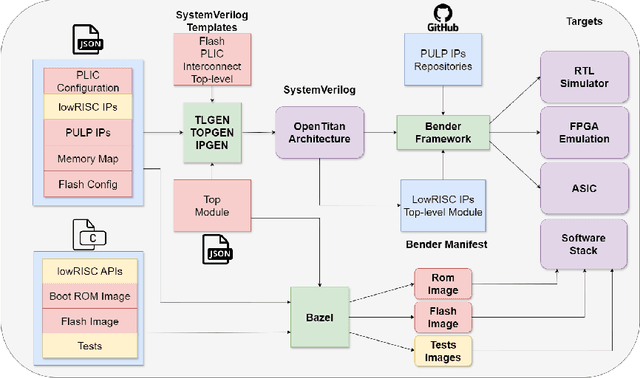
The rapid advancement and exploration of open-hardware RISC-V platforms are driving significant changes in sectors like autonomous vehicles, smart-city infrastructure, and medical devices. OpenTitan stands out as a groundbreaking open-source RISC-V design with a comprehensive security toolkit as a standalone system-on-chip (SoC). OpenTitan includes Earl Grey, a fully implemented and silicon-proven SoC, and Darjeeling, announced but not yet fully implemented. Earl Grey targets standalone SoC implementations, while Darjeeling is for integrable implementations. The literature lacks a silicon-ready embedded implementation of an open-source Root of Trust, despite lowRISC's efforts on Darjeeling. We address the limitations of existing implementations by optimizing data transfer latency between memory and cryptographic accelerators to prevent under-utilization and ensure efficient task acceleration. Our contributions include a comprehensive methodology for integrating custom extensions and IPs into the Earl Grey architecture, architectural enhancements for system-level integration, support for varied boot modes, and improved data movement across the platform. These advancements facilitate deploying OpenTitan in broader SoCs, even without specific technology-dependent IPs, providing a deployment-ready research vehicle for the community. We integrated the extended Earl Grey architecture into a reference architecture in a 22nm FDX technology node, benchmarking the enhanced architecture's performance. The results show significant improvements in cryptographic processing speed, achieving up to 2.7x speedup for SHA-256/HMAC and 1.6x for AES accelerators compared to the baseline Earl Grey architecture.
ITA: An Energy-Efficient Attention and Softmax Accelerator for Quantized Transformers
Jul 10, 2023



Transformer networks have emerged as the state-of-the-art approach for natural language processing tasks and are gaining popularity in other domains such as computer vision and audio processing. However, the efficient hardware acceleration of transformer models poses new challenges due to their high arithmetic intensities, large memory requirements, and complex dataflow dependencies. In this work, we propose ITA, a novel accelerator architecture for transformers and related models that targets efficient inference on embedded systems by exploiting 8-bit quantization and an innovative softmax implementation that operates exclusively on integer values. By computing on-the-fly in streaming mode, our softmax implementation minimizes data movement and energy consumption. ITA achieves competitive energy efficiency with respect to state-of-the-art transformer accelerators with 16.9 TOPS/W, while outperforming them in area efficiency with 5.93 TOPS/mm$^2$ in 22 nm fully-depleted silicon-on-insulator technology at 0.8 V.
A Survey on Deep Learning Hardware Accelerators for Heterogeneous HPC Platforms
Jun 27, 2023



Recent trends in deep learning (DL) imposed hardware accelerators as the most viable solution for several classes of high-performance computing (HPC) applications such as image classification, computer vision, and speech recognition. This survey summarizes and classifies the most recent advances in designing DL accelerators suitable to reach the performance requirements of HPC applications. In particular, it highlights the most advanced approaches to support deep learning accelerations including not only GPU and TPU-based accelerators but also design-specific hardware accelerators such as FPGA-based and ASIC-based accelerators, Neural Processing Units, open hardware RISC-V-based accelerators and co-processors. The survey also describes accelerators based on emerging memory technologies and computing paradigms, such as 3D-stacked Processor-In-Memory, non-volatile memories (mainly, Resistive RAM and Phase Change Memories) to implement in-memory computing, Neuromorphic Processing Units, and accelerators based on Multi-Chip Modules. The survey classifies the most influential architectures and technologies proposed in the last years, with the purpose of offering the reader a comprehensive perspective in the rapidly evolving field of deep learning. Finally, it provides some insights into future challenges in DL accelerators such as quantum accelerators and photonics.
A Heterogeneous In-Memory Computing Cluster For Flexible End-to-End Inference of Real-World Deep Neural Networks
Jan 04, 2022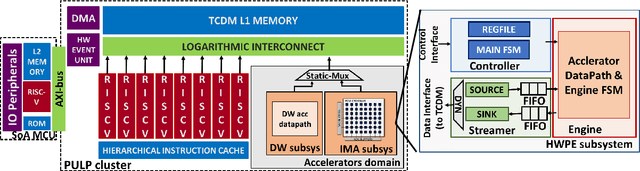
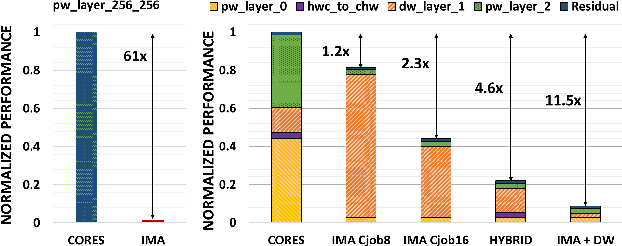
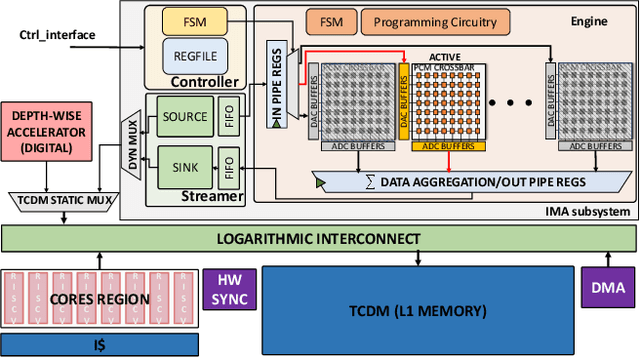
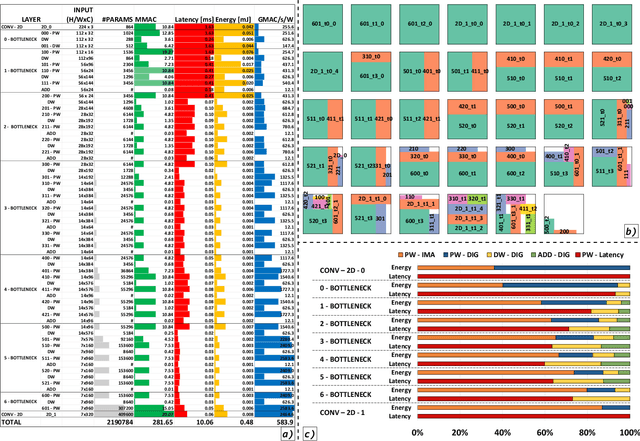
Deployment of modern TinyML tasks on small battery-constrained IoT devices requires high computational energy efficiency. Analog In-Memory Computing (IMC) using non-volatile memory (NVM) promises major efficiency improvements in deep neural network (DNN) inference and serves as on-chip memory storage for DNN weights. However, IMC's functional flexibility limitations and their impact on performance, energy, and area efficiency are not yet fully understood at the system level. To target practical end-to-end IoT applications, IMC arrays must be enclosed in heterogeneous programmable systems, introducing new system-level challenges which we aim at addressing in this work. We present a heterogeneous tightly-coupled clustered architecture integrating 8 RISC-V cores, an in-memory computing accelerator (IMA), and digital accelerators. We benchmark the system on a highly heterogeneous workload such as the Bottleneck layer from a MobileNetV2, showing 11.5x performance and 9.5x energy efficiency improvements, compared to highly optimized parallel execution on the cores. Furthermore, we explore the requirements for end-to-end inference of a full mobile-grade DNN (MobileNetV2) in terms of IMC array resources, by scaling up our heterogeneous architecture to a multi-array accelerator. Our results show that our solution, on the end-to-end inference of the MobileNetV2, is one order of magnitude better in terms of execution latency than existing programmable architectures and two orders of magnitude better than state-of-the-art heterogeneous solutions integrating in-memory computing analog cores.
DORY: Automatic End-to-End Deployment of Real-World DNNs on Low-Cost IoT MCUs
Aug 17, 2020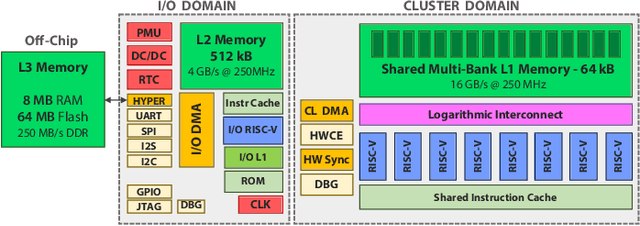


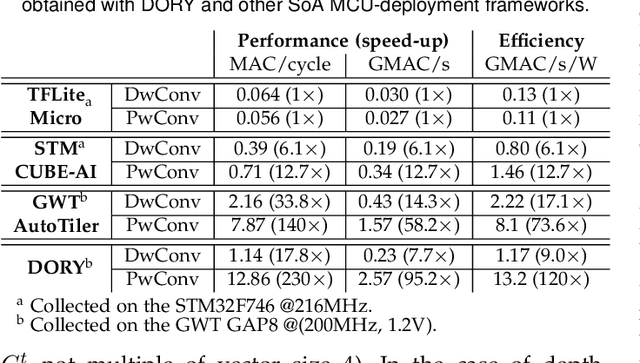
The deployment of Deep Neural Networks (DNNs) on end-nodes at the extreme edge of the Internet-of-Things is a critical enabler to support pervasive Deep Learning-enhanced applications. Low-Cost MCU-based end-nodes have limited on-chip memory and often replace caches with scratchpads, to reduce area overheads and increase energy efficiency -- requiring explicit DMA-based memory transfers between different levels of the memory hierarchy. Mapping modern DNNs on these systems requires aggressive topology-dependent tiling and double-buffering. In this work, we propose DORY (Deployment Oriented to memoRY) - an automatic tool to deploy DNNs on low cost MCUs with typically less than 1MB of on-chip SRAM memory. DORY abstracts tiling as a Constraint Programming (CP) problem: it maximizes L1 memory utilization under the topological constraints imposed by each DNN layer. Then, it generates ANSI C code to orchestrate off- and on-chip transfers and computation phases. Furthermore, to maximize speed, DORY augments the CP formulation with heuristics promoting performance-effective tile sizes. As a case study for DORY, we target GreenWaves Technologies GAP8, one of the most advanced parallel ultra-low power MCU-class devices on the market. On this device, DORY achieves up to 2.5x better MAC/cycle than the GreenWaves proprietary software solution and 18.1x better than the state-of-the-art result on an STM32-F746 MCU on single layers. Using our tool, GAP-8 can perform end-to-end inference of a 1.0-MobileNet-128 network consuming just 63 pJ/MAC on average @ 4.3 fps - 15.4x better than an STM32-F746. We release all our developments - the DORY framework, the optimized backend kernels, and the related heuristics - as open-source software.
PULP-NN: Accelerating Quantized Neural Networks on Parallel Ultra-Low-Power RISC-V Processors
Aug 29, 2019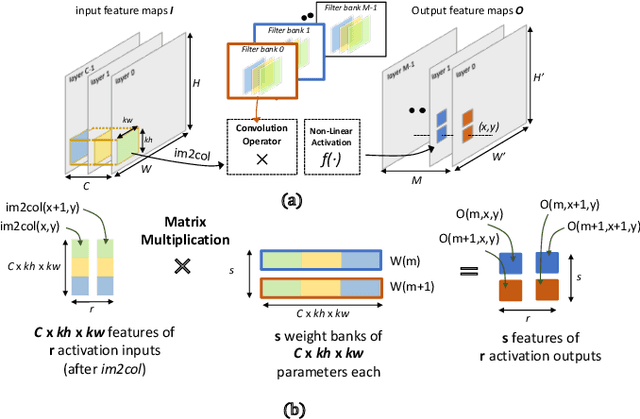
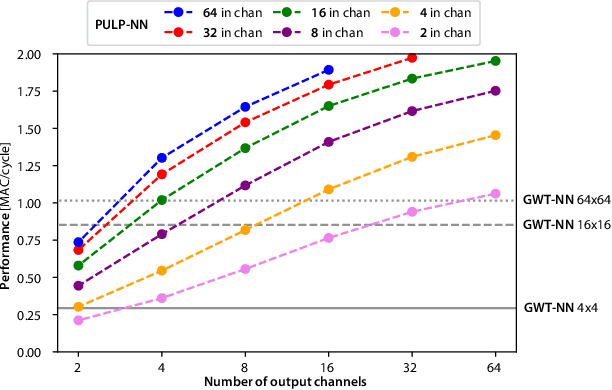
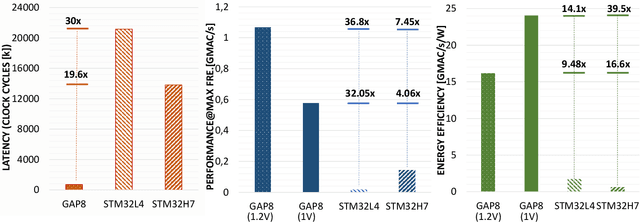
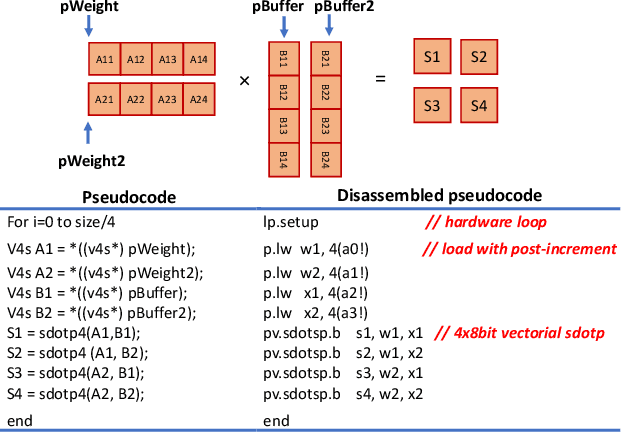
We present PULP-NN, an optimized computing library for a parallel ultra-low-power tightly coupled cluster of RISC-V processors. The key innovation in PULP-NN is a set of kernels for Quantized Neural Network (QNN) inference, targeting byte and sub-byte data types, down to INT-1, tuned for the recent trend toward aggressive quantization in deep neural network inference. The proposed library exploits both the digital signal processing (DSP) extensions available in the PULP RISC-V processors and the cluster's parallelism, achieving up to 15.5 MACs/cycle on INT-8 and improving performance by up to 63x with respect to a sequential implementation on a single RISC-V core implementing the baseline RV32IMC ISA. Using PULP-NN, a CIFAR-10 network on an octa-core cluster runs in 30x and 19.6x less clock cycles than the current state-of-the-art ARM CMSIS-NN library, running on STM32L4 and STM32H7 MCUs, respectively. The proposed library, when running on GAP-8 processor, outperforms by 36.8x and by 7.45x the execution on energy efficient MCUs such as STM32L4 and high-end MCUs such as STM32H7 respectively, when operating at the maximum frequency. The energy efficiency on GAP-8 is 14.1x higher than STM32L4 and 39.5x higher than STM32H7, at the maximum efficiency operating point.