 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarsellus: A Heterogeneous RISC-V AI-IoT End-Node SoC with 2-to-8b DNN Acceleration and 30%-Boost Adaptive Body Biasing
May 15, 2023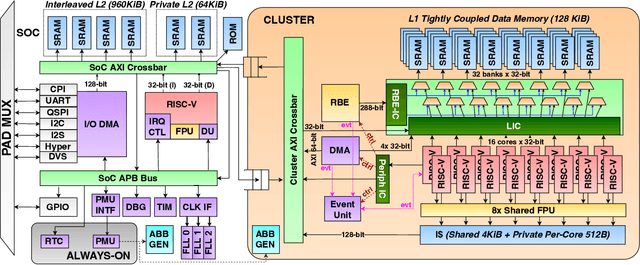
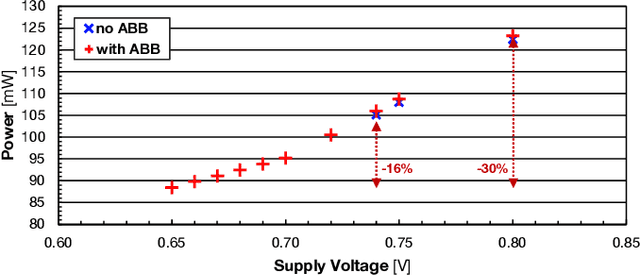
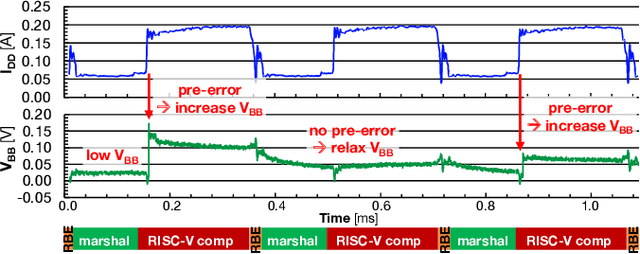
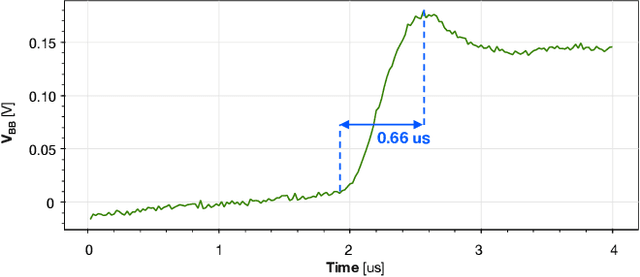
Emerging Artificial Intelligence-enabled Internet-of-Things (AI-IoT) System-on-a-Chip (SoC) for augmented reality, personalized healthcare, and nano-robotics need to run many diverse tasks within a power envelope of a few tens of mW over a wide range of operating conditions: compute-intensive but strongly quantized Deep Neural Network (DNN) inference, as well as signal processing and control requiring high-precision floating-point. We present Marsellus, an all-digital heterogeneous SoC for AI-IoT end-nodes fabricated in GlobalFoundries 22nm FDX that combines 1) a general-purpose cluster of 16 RISC-V Digital Signal Processing (DSP) cores attuned for the execution of a diverse range of workloads exploiting 4-bit and 2-bit arithmetic extensions (XpulpNN), combined with fused MAC&LOAD operations and floating-point support; 2) a 2-8bit Reconfigurable Binary Engine (RBE) to accelerate 3x3 and 1x1 (pointwise) convolutions in DNNs; 3) a set of On-Chip Monitoring (OCM) blocks connected to an Adaptive Body Biasing (ABB) generator and a hardware control loop, enabling on-the-fly adaptation of transistor threshold voltages. Marsellus achieves up to 180 Gop/s or 3.32 Top/s/W on 2-bit precision arithmetic in software, and up to 637 Gop/s or 12.4 Top/s/W on hardware-accelerated DNN layers.
A Heterogeneous In-Memory Computing Cluster For Flexible End-to-End Inference of Real-World Deep Neural Networks
Jan 04, 2022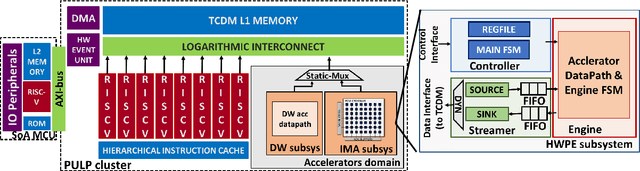
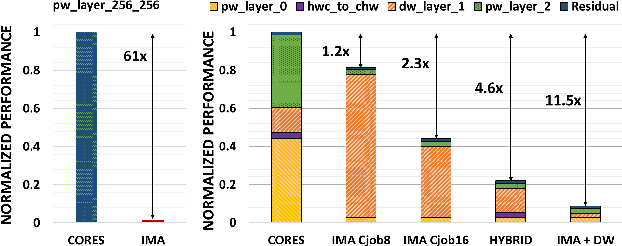
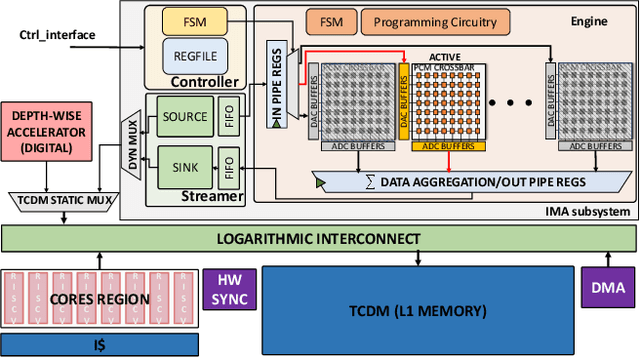
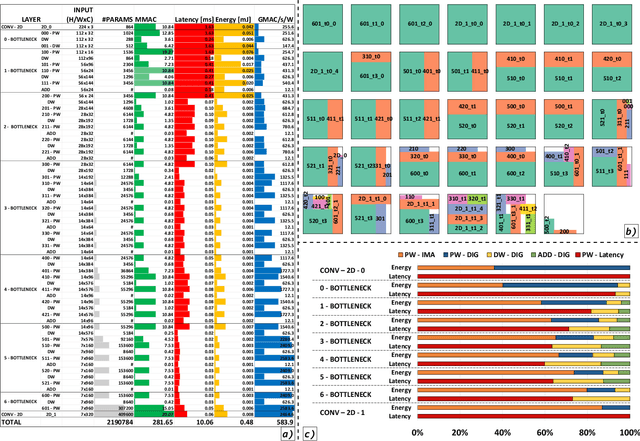
Deployment of modern TinyML tasks on small battery-constrained IoT devices requires high computational energy efficiency. Analog In-Memory Computing (IMC) using non-volatile memory (NVM) promises major efficiency improvements in deep neural network (DNN) inference and serves as on-chip memory storage for DNN weights. However, IMC's functional flexibility limitations and their impact on performance, energy, and area efficiency are not yet fully understood at the system level. To target practical end-to-end IoT applications, IMC arrays must be enclosed in heterogeneous programmable systems, introducing new system-level challenges which we aim at addressing in this work. We present a heterogeneous tightly-coupled clustered architecture integrating 8 RISC-V cores, an in-memory computing accelerator (IMA), and digital accelerators. We benchmark the system on a highly heterogeneous workload such as the Bottleneck layer from a MobileNetV2, showing 11.5x performance and 9.5x energy efficiency improvements, compared to highly optimized parallel execution on the cores. Furthermore, we explore the requirements for end-to-end inference of a full mobile-grade DNN (MobileNetV2) in terms of IMC array resources, by scaling up our heterogeneous architecture to a multi-array accelerator. Our results show that our solution, on the end-to-end inference of the MobileNetV2, is one order of magnitude better in terms of execution latency than existing programmable architectures and two orders of magnitude better than state-of-the-art heterogeneous solutions integrating in-memory computing analog cores.