 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioTrain: Sub-MB, Sub-50mW On-Device Fine-Tuning for Edge-AI on Biosignals
Apr 14, 2026Biosignals exhibit substantial cross-subject and cross-session variability, inducing severe domain shifts that degrade post-deployment performance for small, edge-oriented AI models. On-device adaptation is therefore essential to both preserve user privacy and ensure system reliability. However, existing sub-100 mW MCU-based wearable platforms can only support shallow or sparse adaptation schemes due to the prohibitive memory footprint and computational cost of full backpropagation (BP). In this paper, we propose BioTrain, a framework enabling full-network fine-tuning of state-of-the-art biosignal models under milliwatt-scale power and sub-megabyte memory constraints. We validate BioTrain using both offline and on-device benchmarks on EEG and EOG datasets, covering Day-1 new-subject calibration and longitudinal adaptation to signal drift. Experimental results show that full-network fine-tuning achieves accuracy improvements of up to 35% over non-adapted baselines and outperforms last-layer updates by approximately 7% during new-subject calibration. On the GAP9 MCU platform, BioTrain enables efficient on-device training throughput of 17 samples/s for EEG and 85 samples/s for EOG models within a power envelope below 50 mW. In addition, BioTrain's efficient memory allocator and network topology optimization enable the use of a large batch size, reducing peak memory usage. For fully on-chip BP on GAP9, BioTrain reduces the memory footprint by 8.1x, from 5.4 MB to 0.67 MB, compared to conventional full-network fine-tuning using batch normalization with batch size 8.
MATCHA: Efficient Deployment of Deep Neural Networks on Multi-Accelerator Heterogeneous Edge SoCs
Apr 10, 2026Deploying DNNs on System-on-Chips (SoC) with multiple heterogeneous acceleration engines is challenging, and the majority of deployment frameworks cannot fully exploit heterogeneity. We present MATCHA, a unified DNN deployment framework that generates highly concurrent schedules for parallel, heterogeneous accelerators and uses constraint programming to optimize L3/L2 memory allocation and scheduling. Using pattern matching, tiling, and mapping across individual HW units enables parallel execution and high accelerator utilization. On the MLPerf Tiny benchmark, using a SoC with two heterogeneous accelerators, MATCHA improves accelerator utilization and reduces inference latency by up to 35% with respect to the the state-of-the-art MATCH compiler.
TrainDeeploy: Hardware-Accelerated Parameter-Efficient Fine-Tuning of Small Transformer Models at the Extreme Edge
Mar 10, 2026On-device tuning of deep neural networks enables long-term adaptation at the edge while preserving data privacy. However, the high computational and memory demands of backpropagation pose significant challenges for ultra-low-power, memory-constrained extreme-edge devices. These challenges are further amplified for attention-based models due to their architectural complexity and computational scale. We present TrainDeeploy, a framework that unifies efficient inference and on-device training on heterogeneous ultra-low-power System-on-Chips (SoCs). TrainDeeploy provides the first complete on-device training pipeline for extreme-edge SoCs supporting both Convolutional Neural Networks (CNNs) and Transformer models, together with multiple training strategies such as selective layer-wise fine-tuning and Low-Rank Adaptation (LoRA). On a RISC-V-based heterogeneous SoC, we demonstrate the first end-to-end on-device fine-tuning of a Compact Convolutional Transformer (CCT), achieving up to 11 trained images per second. We show that LoRA reduces dynamic memory usage by 23%, decreases the number of trainable parameters and gradients by 15x, and reduces memory transfer volume by 1.6x compared to full backpropagation. TrainDeeploy achieves up to 4.6 FLOP/cycle on CCT (0.28M parameters, 71-126M FLOPs) and up to 13.4 FLOP/cycle on Deep-AE (0.27M parameters, 0.8M FLOPs), while expanding the scope of prior frameworks to support both CNN and Transformer models with parameter-efficient tuning on extreme-edge platforms.
Tiny-DroNeRF: Tiny Neural Radiance Fields aboard Federated Learning-enabled Nano-drones
Mar 02, 2026Sub-30g nano-sized aerial robots can leverage their agility and form factor to autonomously explore cluttered and narrow environments, like in industrial inspection and search and rescue missions. However, the price for their tiny size is a strong limit in their resources, i.e., sub-100 mW microcontroller units (MCUs) delivering $\sim$100 GOps/s at best, and memory budgets well below 100 MB. Despite these strict constraints, we aim to enable complex vision-based tasks aboard nano-drones, such as dense 3D scene reconstruction: a key robotic task underlying fundamental capabilities like spatial awareness and motion planning. Top-performing 3D reconstruction methods leverage neural radiance fields (NeRF) models, which require GBs of memory and massive computation, usually delivered by high-end GPUs consuming 100s of Watts. Our work introduces Tiny-DroNeRF, a lightweight NeRF model, based on Instant-NGP, and optimized for running on a GAP9 ultra-low-power (ULP) MCU aboard our nano-drones. Then, we further empower our Tiny-DroNeRF by leveraging a collaborative federated learning scheme, which distributes the model training among multiple nano-drones. Our experimental results show a 96% reduction in Tiny-DroNeRF's memory footprint compared to Instant-NGP, with only a 5.7 dB drop in reconstruction accuracy. Finally, our federated learning scheme allows Tiny-DroNeRF to train with an amount of data otherwise impossible to keep in a single drone's memory, increasing the overall reconstruction accuracy. Ultimately, our work combines, for the first time, NeRF training on an ULP MCU with federated learning on nano-drones.
Safe-NEureka: a Hybrid Modular Redundant DNN Accelerator for On-board Satellite AI Processing
Feb 04, 2026Low Earth Orbit (LEO) constellations are revolutionizing the space sector, with on-board Artificial Intelligence (AI) becoming pivotal for next-generation satellites. AI acceleration is essential for safety-critical functions such as autonomous Guidance, Navigation, and Control (GNC), where errors cannot be tolerated, and performance-critical processing of high-bandwidth sensor data, where occasional errors are tolerable. Consequently, AI accelerators for satellites must combine robust protection against radiation-induced faults with high throughput. This paper presents Safe-NEureka, a Hybrid Modular Redundant Deep Neural Network (DNN) accelerator for heterogeneous RISC-V systems. It operates in two modes: a redundancy mode utilizing Dual Modular Redundancy (DMR) with hardware-based recovery, and a performance mode repurposing redundant datapaths to maximize parallel throughput. Furthermore, its memory interface is protected by Error Correction Codes (ECCs), and the controller by Triple Modular Redundancy (TMR). Implementation in GlobalFoundries 12nm technology shows a 96 reduction in faulty executions in redundancy mode, with a manageable 15 area overhead. In performance mode, the architecture achieves near-baseline speeds on 3x3 dense convolutions with a 5 throughput and 11 efficiency reduction, compared to 48 and 53 in redundancy mode. This flexibility ensures high overheads are limited to critical tasks, establishing Safe-NEureka as a versatile solution for space applications.
An Algebraic Representation Theorem for Linear GENEOs in Geometric Machine Learning
Jan 07, 2026Geometric and Topological Deep Learning are rapidly growing research areas that enhance machine learning through the use of geometric and topological structures. Within this framework, Group Equivariant Non-Expansive Operators (GENEOs) have emerged as a powerful class of operators for encoding symmetries and designing efficient, interpretable neural architectures. Originally introduced in Topological Data Analysis, GENEOs have since found applications in Deep Learning as tools for constructing equivariant models with reduced parameter complexity. GENEOs provide a unifying framework bridging Geometric and Topological Deep Learning and include the operator computing persistence diagrams as a special case. Their theoretical foundations rely on group actions, equivariance, and compactness properties of operator spaces, grounding them in algebra and geometry while enabling both mathematical rigor and practical relevance. While a previous representation theorem characterized linear GENEOs acting on data of the same type, many real-world applications require operators between heterogeneous data spaces. In this work, we address this limitation by introducing a new representation theorem for linear GENEOs acting between different perception pairs, based on generalized T-permutant measures. Under mild assumptions on the data domains and group actions, our result provides a complete characterization of such operators. We also prove the compactness and convexity of the space of linear GENEOs. We further demonstrate the practical impact of this theory by applying the proposed framework to improve the performance of autoencoders, highlighting the relevance of GENEOs in modern machine learning applications.
VEXP: A Low-Cost RISC-V ISA Extension for Accelerated Softmax Computation in Transformers
Apr 15, 2025While Transformers are dominated by Floating-Point (FP) Matrix-Multiplications, their aggressive acceleration through dedicated hardware or many-core programmable systems has shifted the performance bottleneck to non-linear functions like Softmax. Accelerating Softmax is challenging due to its non-pointwise, non-linear nature, with exponentiation as the most demanding step. To address this, we design a custom arithmetic block for Bfloat16 exponentiation leveraging a novel approximation algorithm based on Schraudolph's method, and we integrate it into the Floating-Point Unit (FPU) of the RISC-V cores of a compute cluster, through custom Instruction Set Architecture (ISA) extensions, with a negligible area overhead of 1\%. By optimizing the software kernels to leverage the extension, we execute Softmax with 162.7$\times$ less latency and 74.3$\times$ less energy compared to the baseline cluster, achieving an 8.2$\times$ performance improvement and 4.1$\times$ higher energy efficiency for the FlashAttention-2 kernel in GPT-2 configuration. Moreover, the proposed approach enables a multi-cluster system to efficiently execute end-to-end inference of pre-trained Transformer models, such as GPT-2, GPT-3 and ViT, achieving up to 5.8$\times$ and 3.6$\times$ reduction in latency and energy consumption, respectively, without requiring re-training and with negligible accuracy loss.
Lightweight Software Kernels and Hardware Extensions for Efficient Sparse Deep Neural Networks on Microcontrollers
Mar 08, 2025The acceleration of pruned Deep Neural Networks (DNNs) on edge devices such as Microcontrollers (MCUs) is a challenging task, given the tight area- and power-constraints of these devices. In this work, we propose a three-fold contribution to address this problem. First, we design a set of optimized software kernels for N:M pruned layers, targeting ultra-low-power, multicore RISC-V MCUs, which are up to 2.1x and 3.4x faster than their dense counterparts at 1:8 and 1:16 sparsity, respectively. Then, we implement a lightweight Instruction-Set Architecture (ISA) extension to accelerate the indirect load and non-zero indices decompression operations required by our kernels, obtaining up to 1.9x extra speedup, at the cost of a 5% area overhead. Lastly, we extend an open-source DNN compiler to utilize our sparse kernels for complete networks, showing speedups of 3.21x and 1.81x on a ResNet18 and a Vision Transformer (ViT), with less than 1.5% accuracy drop compared to a dense baseline.
Open-Source Heterogeneous SoCs for AI: The PULP Platform Experience
Dec 29, 2024



Since 2013, the PULP (Parallel Ultra-Low Power) Platform project has been one of the most active and successful initiatives in designing research IPs and releasing them as open-source. Its portfolio now ranges from processor cores to network-on-chips, peripherals, SoC templates, and full hardware accelerators. In this article, we focus on the PULP experience designing heterogeneous AI acceleration SoCs - an endeavour encompassing SoC architecture definition; development, verification, and integration of acceleration IPs; front- and back-end VLSI design; testing; development of AI deployment software.
Accelerating Image-based Pest Detection on a Heterogeneous Multi-core Microcontroller
Aug 29, 2024

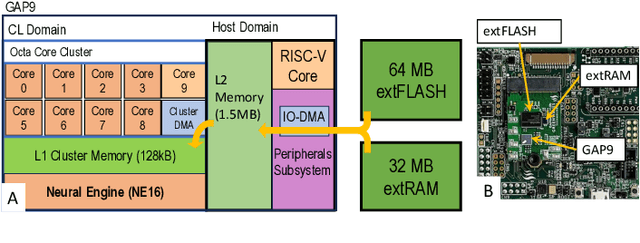

The codling moth pest poses a significant threat to global crop production, with potential losses of up to 80% in apple orchards. Special camera-based sensor nodes are deployed in the field to record and transmit images of trapped insects to monitor the presence of the pest. This paper investigates the embedding of computer vision algorithms in the sensor node using a novel State-of-the-Art Microcontroller Unit (MCU), the GreenWaves Technologies' GAP9 System-on-Chip, which combines 10 RISC-V general purposes cores with a convolution hardware accelerator. We compare the performance of a lightweight Viola-Jones detector algorithm with a Convolutional Neural Network (CNN), MobileNetV3-SSDLite, trained for the pest detection task. On two datasets that differentiate for the distance between the camera sensor and the pest targets, the CNN generalizes better than the other method and achieves a detection accuracy between 83% and 72%. Thanks to the GAP9's CNN accelerator, the CNN inference task takes only 147 ms to process a 320$\times$240 image. Compared to the GAP8 MCU, which only relies on general-purpose cores for processing, we achieved 9.5$\times$ faster inference speed. When running on a 1000 mAh battery at 3.7 V, the estimated lifetime is approximately 199 days, processing an image every 30 seconds. Our study demonstrates that the novel heterogeneous MCU can perform end-to-end CNN inference with an energy consumption of just 4.85 mJ, matching the efficiency of the simpler Viola-Jones algorithm and offering power consumption up to 15$\times$ lower than previous methods. Code at: https://github.com/Bomps4/TAFE_Pest_Detection