 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Image-based Pest Detection on a Heterogeneous Multi-core Microcontroller
Aug 29, 2024The codling moth pest poses a significant threat to global crop production, with potential losses of up to 80% in apple orchards. Special camera-based sensor nodes are deployed in the field to record and transmit images of trapped insects to monitor the presence of the pest. This paper investigates the embedding of computer vision algorithms in the sensor node using a novel State-of-the-Art Microcontroller Unit (MCU), the GreenWaves Technologies' GAP9 System-on-Chip, which combines 10 RISC-V general purposes cores with a convolution hardware accelerator. We compare the performance of a lightweight Viola-Jones detector algorithm with a Convolutional Neural Network (CNN), MobileNetV3-SSDLite, trained for the pest detection task. On two datasets that differentiate for the distance between the camera sensor and the pest targets, the CNN generalizes better than the other method and achieves a detection accuracy between 83% and 72%. Thanks to the GAP9's CNN accelerator, the CNN inference task takes only 147 ms to process a 320$\times$240 image. Compared to the GAP8 MCU, which only relies on general-purpose cores for processing, we achieved 9.5$\times$ faster inference speed. When running on a 1000 mAh battery at 3.7 V, the estimated lifetime is approximately 199 days, processing an image every 30 seconds. Our study demonstrates that the novel heterogeneous MCU can perform end-to-end CNN inference with an energy consumption of just 4.85 mJ, matching the efficiency of the simpler Viola-Jones algorithm and offering power consumption up to 15$\times$ lower than previous methods. Code at: https://github.com/Bomps4/TAFE_Pest_Detection
Self-Learning for Personalized Keyword Spotting on Ultra-Low-Power Audio Sensors
Aug 22, 2024This paper proposes a self-learning framework to incrementally train (fine-tune) a personalized Keyword Spotting (KWS) model after the deployment on ultra-low power smart audio sensors. We address the fundamental problem of the absence of labeled training data by assigning pseudo-labels to the new recorded audio frames based on a similarity score with respect to few user recordings. By experimenting with multiple KWS models with a number of parameters up to 0.5M on two public datasets, we show an accuracy improvement of up to +19.2% and +16.0% vs. the initial models pretrained on a large set of generic keywords. The labeling task is demonstrated on a sensor system composed of a low-power microphone and an energy-efficient Microcontroller (MCU). By efficiently exploiting the heterogeneous processing engines of the MCU, the always-on labeling task runs in real-time with an average power cost of up to 8.2 mW. On the same platform, we estimate an energy cost for on-device training 10x lower than the labeling energy if sampling a new utterance every 5 s or 16.4 s with a DS-CNN-S or a DS-CNN-M model. Our empirical result paves the way to self-adaptive personalized KWS sensors at the extreme edge.
Multi-resolution Rescored ByteTrack for Video Object Detection on Ultra-low-power Embedded Systems
Apr 17, 2024



This paper introduces Multi-Resolution Rescored Byte-Track (MR2-ByteTrack), a novel video object detection framework for ultra-low-power embedded processors. This method reduces the average compute load of an off-the-shelf Deep Neural Network (DNN) based object detector by up to 2.25$\times$ by alternating the processing of high-resolution images (320$\times$320 pixels) with multiple down-sized frames (192$\times$192 pixels). To tackle the accuracy degradation due to the reduced image input size, MR2-ByteTrack correlates the output detections over time using the ByteTrack tracker and corrects potential misclassification using a novel probabilistic Rescore algorithm. By interleaving two down-sized images for every high-resolution one as the input of different state-of-the-art DNN object detectors with our MR2-ByteTrack, we demonstrate an average accuracy increase of 2.16% and a latency reduction of 43% on the GAP9 microcontroller compared to a baseline frame-by-frame inference scheme using exclusively full-resolution images. Code available at: https://github.com/Bomps4/Multi_Resolution_Rescored_ByteTrack
On-Device Domain Learning for Keyword Spotting on Low-Power Extreme Edge Embedded Systems
Mar 12, 2024


Keyword spotting accuracy degrades when neural networks are exposed to noisy environments. On-site adaptation to previously unseen noise is crucial to recovering accuracy loss, and on-device learning is required to ensure that the adaptation process happens entirely on the edge device. In this work, we propose a fully on-device domain adaptation system achieving up to 14% accuracy gains over already-robust keyword spotting models. We enable on-device learning with less than 10 kB of memory, using only 100 labeled utterances to recover 5% accuracy after adapting to the complex speech noise. We demonstrate that domain adaptation can be achieved on ultra-low-power microcontrollers with as little as 806 mJ in only 14 s on always-on, battery-operated devices.
On-device Self-supervised Learning of Visual Perception Tasks aboard Hardware-limited Nano-quadrotors
Mar 06, 2024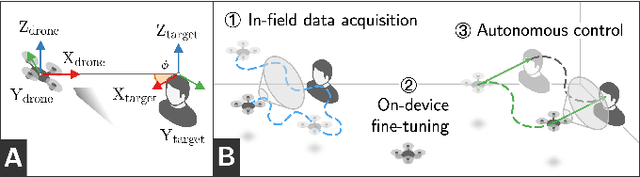
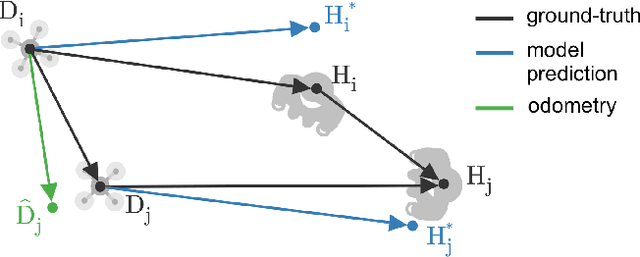
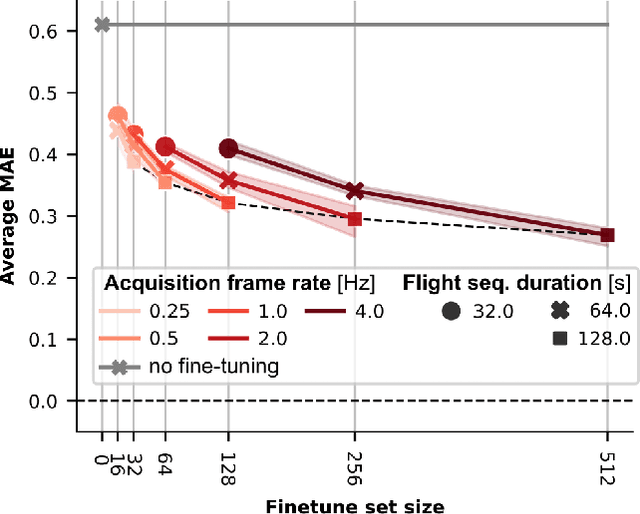
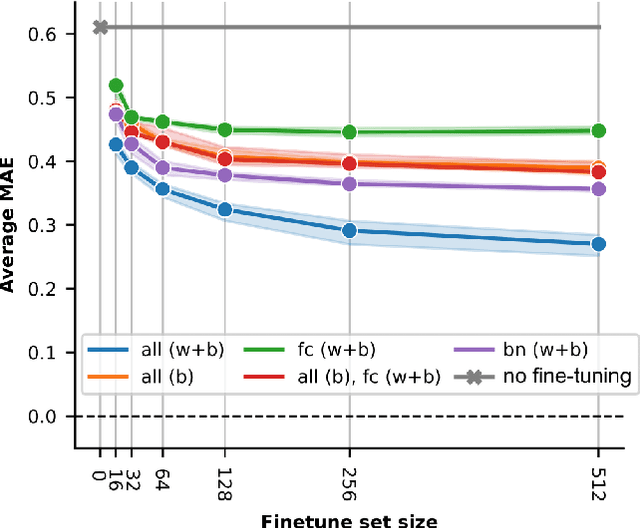
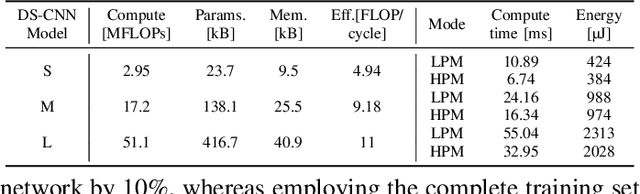
Sub-\SI{50}{\gram} nano-drones are gaining momentum in both academia and industry. Their most compelling applications rely on onboard deep learning models for perception despite severe hardware constraints (\ie sub-\SI{100}{\milli\watt} processor). When deployed in unknown environments not represented in the training data, these models often underperform due to domain shift. To cope with this fundamental problem, we propose, for the first time, on-device learning aboard nano-drones, where the first part of the in-field mission is dedicated to self-supervised fine-tuning of a pre-trained convolutional neural network (CNN). Leveraging a real-world vision-based regression task, we thoroughly explore performance-cost trade-offs of the fine-tuning phase along three axes: \textit{i}) dataset size (more data increases the regression performance but requires more memory and longer computation); \textit{ii}) methodologies (\eg fine-tuning all model parameters vs. only a subset); and \textit{iii}) self-supervision strategy. Our approach demonstrates an improvement in mean absolute error up to 30\% compared to the pre-trained baseline, requiring only \SI{22}{\second} fine-tuning on an ultra-low-power GWT GAP9 System-on-Chip. Addressing the domain shift problem via on-device learning aboard nano-drones not only marks a novel result for hardware-limited robots but lays the ground for more general advancements for the entire robotics community.
Multi-sensory Anti-collision Design for Autonomous Nano-swarm Exploration
Dec 20, 2023This work presents a multi-sensory anti-collision system design to achieve robust autonomous exploration capabilities for a swarm of 10 cm-side nano-drones operating on object detection missions. We combine lightweight single-beam laser ranging to avoid proximity collisions with a long-range vision-based obstacle avoidance deep learning model (i.e., PULP-Dronet) and an ultra-wide-band (UWB) based ranging module to prevent intra-swarm collisions. An in-field study shows that our multisensory approach can prevent collisions with static obstacles, improving the mission success rate from 20% to 80% in cluttered environments w.r.t. a State-of-the-Art (SoA) baseline. At the same time, the UWB-based sub-system shows a 92.8% success rate in preventing collisions between drones of a four-agent fleet within a safety distance of 65 cm. On a SoA robotic platform extended by a GAP8 multi-core processor, the PULP-Dronet runs interleaved with an objected detection task, which constraints its execution at 1.6 frame/s. This throughput is sufficient for avoiding obstacles with a probability of about 40% but shows a need for more capable processors for the next-generation nano-drone swarms.
Land & Localize: An Infrastructure-free and Scalable Nano-Drones Swarm with UWB-based Localization
Jul 17, 2023



Relative localization is a crucial functional block of any robotic swarm. We address it in a fleet of nano-drones characterized by a 10 cm-scale form factor, which makes them highly versatile but also strictly limited in their onboard power envelope. State-of-the-Art solutions leverage Ultra-WideBand (UWB) technology, allowing distance range measurements between peer nano-drones and a stationary infrastructure of multiple UWB anchors. Therefore, we propose an UWB-based infrastructure-free nano-drones swarm, where part of the fleet acts as dynamic anchors, i.e., anchor-drones (ADs), capable of automatic deployment and landing. By varying the Ads' position constraint, we develop three alternative solutions with different trade-offs between flexibility and localization accuracy. In-field results, with four flying mission-drones (MDs), show a localization root mean square error (RMSE) spanning from 15.3 cm to 27.8 cm, at most. Scaling the number of MDs from 4 to 8, the RMSE marginally increases, i.e., less than 10 cm at most. The power consumption of the MDs' UWB module amounts to 342 mW. Ultimately, compared to a fixed-infrastructure commercial solution, our infrastructure-free system can be deployed anywhere and rapidly by taking 5.7 s to self-localize 4 ADs with a localization RMSE of up to 12.3% in the most challenging case with 8 MDs.
Few-Shot Open-Set Learning for On-Device Customization of KeyWord Spotting Systems
Jun 03, 2023A personalized KeyWord Spotting (KWS) pipeline typically requires the training of a Deep Learning model on a large set of user-defined speech utterances, preventing fast customization directly applied on-device. To fill this gap, this paper investigates few-shot learning methods for open-set KWS classification by combining a deep feature encoder with a prototype-based classifier. With user-defined keywords from 10 classes of the Google Speech Command dataset, our study reports an accuracy of up to 76% in a 10-shot scenario while the false acceptance rate of unknown data is kept to 5%. In the analyzed settings, the usage of the triplet loss to train an encoder with normalized output features performs better than the prototypical networks jointly trained with a generator of dummy unknown-class prototypes. This design is also more effective than encoders trained on a classification problem and features fewer parameters than other iso-accuracy approaches.
Reduced Precision Floating-Point Optimization for Deep Neural Network On-Device Learning on MicroControllers
May 30, 2023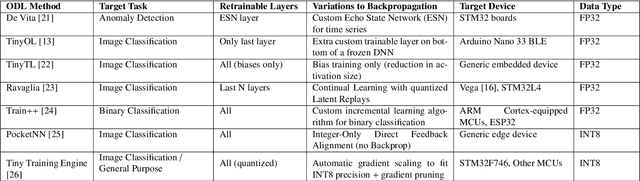

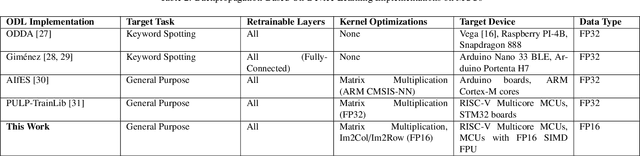

Enabling On-Device Learning (ODL) for Ultra-Low-Power Micro-Controller Units (MCUs) is a key step for post-deployment adaptation and fine-tuning of Deep Neural Network (DNN) models in future TinyML applications. This paper tackles this challenge by introducing a novel reduced precision optimization technique for ODL primitives on MCU-class devices, leveraging the State-of-Art advancements in RISC-V RV32 architectures with support for vectorized 16-bit floating-point (FP16) Single-Instruction Multiple-Data (SIMD) operations. Our approach for the Forward and Backward steps of the Back-Propagation training algorithm is composed of specialized shape transform operators and Matrix Multiplication (MM) kernels, accelerated with parallelization and loop unrolling. When evaluated on a single training step of a 2D Convolution layer, the SIMD-optimized FP16 primitives result up to 1.72$\times$ faster than the FP32 baseline on a RISC-V-based 8+1-core MCU. An average computing efficiency of 3.11 Multiply and Accumulate operations per clock cycle (MAC/clk) and 0.81 MAC/clk is measured for the end-to-end training tasks of a ResNet8 and a DS-CNN for Image Classification and Keyword Spotting, respectively -- requiring 17.1 ms and 6.4 ms on the target platform to compute a training step on a single sample. Overall, our approach results more than two orders of magnitude faster than existing ODL software frameworks for single-core MCUs and outperforms by 1.6 $\times$ previous FP32 parallel implementations on a Continual Learning setup.
Bio-inspired Autonomous Exploration Policies with CNN-based Object Detection on Nano-drones
Feb 01, 2023Nano-sized drones, with palm-sized form factor, are gaining relevance in the Internet-of-Things ecosystem. Achieving a high degree of autonomy for complex multi-objective missions (e.g., safe flight, exploration, object detection) is extremely challenging for the onboard chip-set due to tight size, payload (<10g), and power envelope constraints, which strictly limit both memory and computation. Our work addresses this complex problem by combining bio-inspired navigation policies, which rely on time-of-flight distance sensor data, with a vision-based convolutional neural network (CNN) for object detection. Our field-proven nano-drone is equipped with two microcontroller units (MCUs), a single-core ARM Cortex-M4 (STM32) for safe navigation and exploration policies, and a parallel ultra-low power octa-core RISC-V (GAP8) for onboard CNN inference, with a power envelope of just 134mW, including image sensors and external memories. The object detection task achieves a mean average precision of 50% (at 1.6 frame/s) on an in-field collected dataset. We compare four bio-inspired exploration policies and identify a pseudo-random policy to achieve the highest coverage area of 83% in a ~36m^2 unknown room in a 3 minutes flight. By combining the detection CNN and the exploration policy, we show an average detection rate of 90% on six target objects in a never-seen-before environment.