 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny-DroNeRF: Tiny Neural Radiance Fields aboard Federated Learning-enabled Nano-drones
Mar 02, 2026Sub-30g nano-sized aerial robots can leverage their agility and form factor to autonomously explore cluttered and narrow environments, like in industrial inspection and search and rescue missions. However, the price for their tiny size is a strong limit in their resources, i.e., sub-100 mW microcontroller units (MCUs) delivering $\sim$100 GOps/s at best, and memory budgets well below 100 MB. Despite these strict constraints, we aim to enable complex vision-based tasks aboard nano-drones, such as dense 3D scene reconstruction: a key robotic task underlying fundamental capabilities like spatial awareness and motion planning. Top-performing 3D reconstruction methods leverage neural radiance fields (NeRF) models, which require GBs of memory and massive computation, usually delivered by high-end GPUs consuming 100s of Watts. Our work introduces Tiny-DroNeRF, a lightweight NeRF model, based on Instant-NGP, and optimized for running on a GAP9 ultra-low-power (ULP) MCU aboard our nano-drones. Then, we further empower our Tiny-DroNeRF by leveraging a collaborative federated learning scheme, which distributes the model training among multiple nano-drones. Our experimental results show a 96% reduction in Tiny-DroNeRF's memory footprint compared to Instant-NGP, with only a 5.7 dB drop in reconstruction accuracy. Finally, our federated learning scheme allows Tiny-DroNeRF to train with an amount of data otherwise impossible to keep in a single drone's memory, increasing the overall reconstruction accuracy. Ultimately, our work combines, for the first time, NeRF training on an ULP MCU with federated learning on nano-drones.
NanoCockpit: Performance-optimized Application Framework for AI-based Autonomous Nanorobotics
Jan 12, 2026Autonomous nano-drones, powered by vision-based tiny machine learning (TinyML) models, are a novel technology gaining momentum thanks to their broad applicability and pushing scientific advancement on resource-limited embedded systems. Their small form factor, i.e., a few 10s grams, severely limits their onboard computational resources to sub-\SI{100}{\milli\watt} microcontroller units (MCUs). The Bitcraze Crazyflie nano-drone is the \textit{de facto} standard, offering a rich set of programmable MCUs for low-level control, multi-core processing, and radio transmission. However, roboticists very often underutilize these onboard precious resources due to the absence of a simple yet efficient software layer capable of time-optimal pipelining of multi-buffer image acquisition, multi-core computation, intra-MCUs data exchange, and Wi-Fi streaming, leading to sub-optimal control performances. Our \textit{NanoCockpit} framework aims to fill this gap, increasing the throughput and minimizing the system's latency, while simplifying the developer experience through coroutine-based multi-tasking. In-field experiments on three real-world TinyML nanorobotics applications show our framework achieves ideal end-to-end latency, i.e. zero overhead due to serialized tasks, delivering quantifiable improvements in closed-loop control performance ($-$30\% mean position error, mission success rate increased from 40\% to 100\%).
Nonlinear System Identification Nano-drone Benchmark
Dec 16, 2025We introduce a benchmark for system identification based on 75k real-world samples from the Crazyflie 2.1 Brushless nano-quadrotor, a sub-50g aerial vehicle widely adopted in robotics research. The platform presents a challenging testbed due to its multi-input, multi-output nature, open-loop instability, and nonlinear dynamics under agile maneuvers. The dataset comprises four aggressive trajectories with synchronized 4-dimensional motor inputs and 13-dimensional output measurements. To enable fair comparison of identification methods, the benchmark includes a suite of multi-horizon prediction metrics for evaluating both one-step and multi-step error propagation. In addition to the data, we provide a detailed description of the platform and experimental setup, as well as baseline models highlighting the challenge of accurate prediction under real-world noise and actuation nonlinearities. All data, scripts, and reference implementations are released as open-source at https://github.com/idsia-robotics/nanodrone-sysid-benchmark to facilitate transparent comparison of algorithms and support research on agile, miniaturized aerial robotics.
Training on the Fly: On-device Self-supervised Learning aboard Nano-drones within 20 mW
Aug 06, 2024



Miniaturized cyber-physical systems (CPSes) powered by tiny machine learning (TinyML), such as nano-drones, are becoming an increasingly attractive technology. Their small form factor (i.e., ~10cm diameter) ensures vast applicability, ranging from the exploration of narrow disaster scenarios to safe human-robot interaction. Simple electronics make these CPSes inexpensive, but strongly limit the computational, memory, and sensing resources available on board. In real-world applications, these limitations are further exacerbated by domain shift. This fundamental machine learning problem implies that model perception performance drops when moving from the training domain to a different deployment one. To cope with and mitigate this general problem, we present a novel on-device fine-tuning approach that relies only on the limited ultra-low power resources available aboard nano-drones. Then, to overcome the lack of ground-truth training labels aboard our CPS, we also employ a self-supervised method based on ego-motion consistency. Albeit our work builds on top of a specific real-world vision-based human pose estimation task, it is widely applicable for many embedded TinyML use cases. Our 512-image on-device training procedure is fully deployed aboard an ultra-low power GWT GAP9 System-on-Chip and requires only 1MB of memory while consuming as low as 19mW or running in just 510ms (at 38mW). Finally, we demonstrate the benefits of our on-device learning approach by field-testing our closed-loop CPS, showing a reduction in horizontal position error of up to 26% vs. a non-fine-tuned state-of-the-art baseline. In the most challenging never-seen-before environment, our on-device learning procedure makes the difference between succeeding or failing the mission.
Fusing Multi-sensor Input with State Information on TinyML Brains for Autonomous Nano-drones
Apr 03, 2024


Autonomous nano-drones (~10 cm in diameter), thanks to their ultra-low power TinyML-based brains, are capable of coping with real-world environments. However, due to their simplified sensors and compute units, they are still far from the sense-and-act capabilities shown in their bigger counterparts. This system paper presents a novel deep learning-based pipeline that fuses multi-sensorial input (i.e., low-resolution images and 8x8 depth map) with the robot's state information to tackle a human pose estimation task. Thanks to our design, the proposed system -- trained in simulation and tested on a real-world dataset -- improves a state-unaware State-of-the-Art baseline by increasing the R^2 regression metric up to 0.10 on the distance's prediction.
On-device Self-supervised Learning of Visual Perception Tasks aboard Hardware-limited Nano-quadrotors
Mar 06, 2024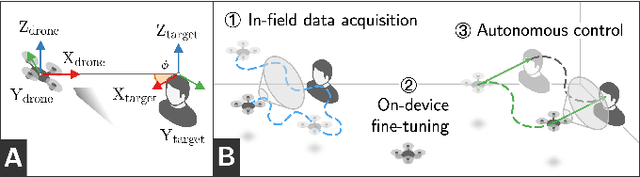
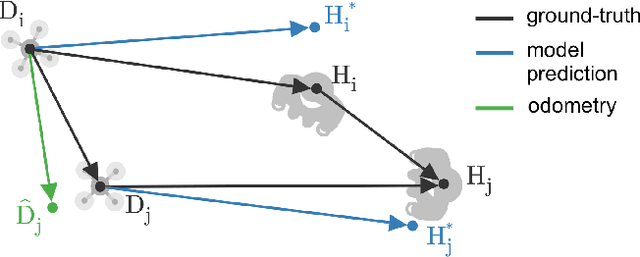
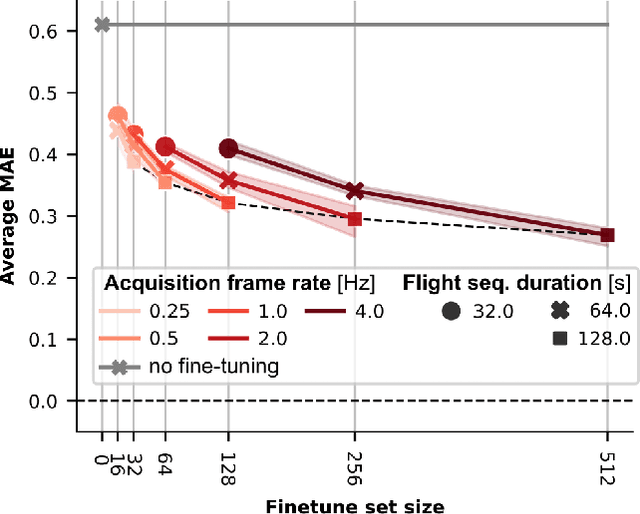
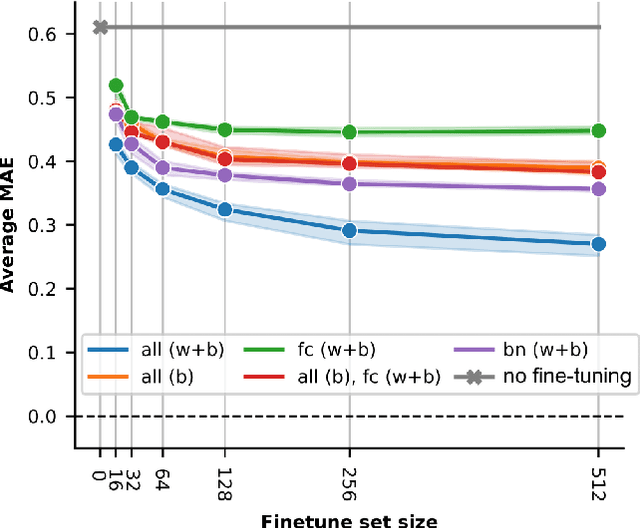
Sub-\SI{50}{\gram} nano-drones are gaining momentum in both academia and industry. Their most compelling applications rely on onboard deep learning models for perception despite severe hardware constraints (\ie sub-\SI{100}{\milli\watt} processor). When deployed in unknown environments not represented in the training data, these models often underperform due to domain shift. To cope with this fundamental problem, we propose, for the first time, on-device learning aboard nano-drones, where the first part of the in-field mission is dedicated to self-supervised fine-tuning of a pre-trained convolutional neural network (CNN). Leveraging a real-world vision-based regression task, we thoroughly explore performance-cost trade-offs of the fine-tuning phase along three axes: \textit{i}) dataset size (more data increases the regression performance but requires more memory and longer computation); \textit{ii}) methodologies (\eg fine-tuning all model parameters vs. only a subset); and \textit{iii}) self-supervision strategy. Our approach demonstrates an improvement in mean absolute error up to 30\% compared to the pre-trained baseline, requiring only \SI{22}{\second} fine-tuning on an ultra-low-power GWT GAP9 System-on-Chip. Addressing the domain shift problem via on-device learning aboard nano-drones not only marks a novel result for hardware-limited robots but lays the ground for more general advancements for the entire robotics community.
A Sim-to-Real Deep Learning-based Framework for Autonomous Nano-drone Racing
Dec 14, 2023



Autonomous drone racing competitions are a proxy to improve unmanned aerial vehicles' perception, planning, and control skills. The recent emergence of autonomous nano-sized drone racing imposes new challenges, as their ~10cm form factor heavily restricts the resources available onboard, including memory, computation, and sensors. This paper describes the methodology and technical implementation of the system winning the first autonomous nano-drone racing international competition: the IMAV 2022 Nanocopter AI Challenge. We developed a fully onboard deep learning approach for visual navigation trained only on simulation images to achieve this goal. Our approach includes a convolutional neural network for obstacle avoidance, a sim-to-real dataset collection procedure, and a navigation policy that we selected, characterized, and adapted through simulation and actual in-field experiments. Our system ranked 1st among seven competing teams at the competition. In our best attempt, we scored 115m of traveled distance in the allotted 5-minute flight, never crashing while dodging static and dynamic obstacles. Sharing our knowledge with the research community, we aim to provide a solid groundwork to foster future development in this field.
Sim-to-Real Vision-depth Fusion CNNs for Robust Pose Estimation Aboard Autonomous Nano-quadcopter
Aug 03, 2023



Nano-quadcopters are versatile platforms attracting the interest of both academia and industry. Their tiny form factor, i.e., $\,$10 cm diameter, makes them particularly useful in narrow scenarios and harmless in human proximity. However, these advantages come at the price of ultra-constrained onboard computational and sensorial resources for autonomous operations. This work addresses the task of estimating human pose aboard nano-drones by fusing depth and images in a novel CNN exclusively trained in simulation yet capable of robust predictions in the real world. We extend a commercial off-the-shelf (COTS) Crazyflie nano-drone -- equipped with a 320$\times$240 px camera and an ultra-low-power System-on-Chip -- with a novel multi-zone (8$\times$8) depth sensor. We design and compare different deep-learning models that fuse depth and image inputs. Our models are trained exclusively on simulated data for both inputs, and transfer well to the real world: field testing shows an improvement of 58% and 51% of our depth+camera system w.r.t. a camera-only State-of-the-Art baseline on the horizontal and angular mean pose errors, respectively. Our prototype is based on COTS components, which facilitates reproducibility and adoption of this novel class of systems.
Secure Deep Learning-based Distributed Intelligence on Pocket-sized Drones
Jul 04, 2023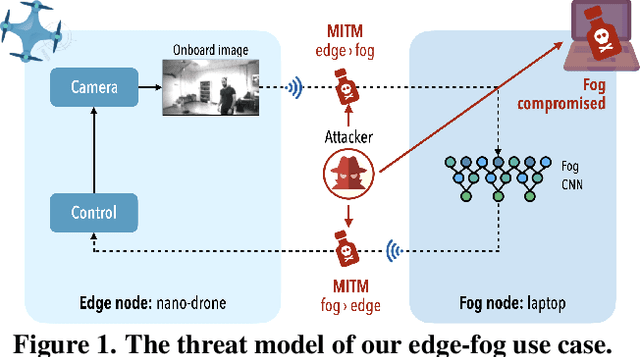

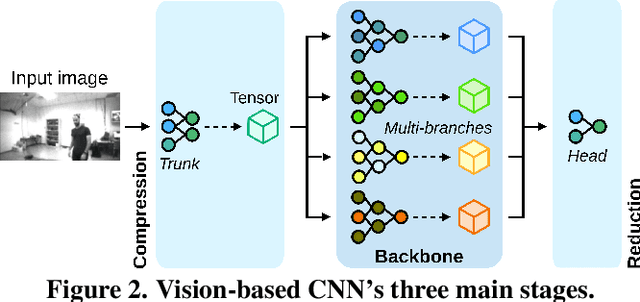
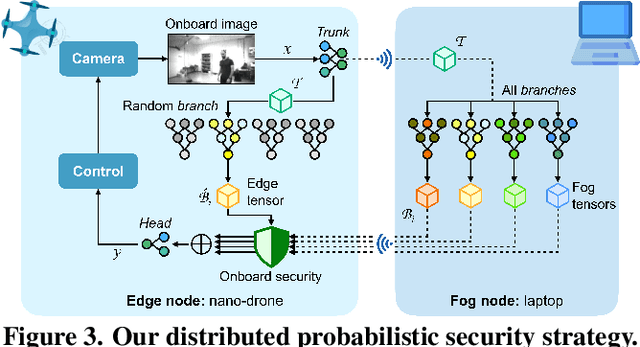
Palm-sized nano-drones are an appealing class of edge nodes, but their limited computational resources prevent running large deep-learning models onboard. Adopting an edge-fog computational paradigm, we can offload part of the computation to the fog; however, this poses security concerns if the fog node, or the communication link, can not be trusted. To tackle this concern, we propose a novel distributed edge-fog execution scheme that validates fog computation by redundantly executing a random subnetwork aboard our nano-drone. Compared to a State-of-the-Art visual pose estimation network that entirely runs onboard, a larger network executed in a distributed way improves the $R^2$ score by +0.19; in case of attack, our approach detects it within 2s with 95% probability.
Deep Neural Network Architecture Search for Accurate Visual Pose Estimation aboard Nano-UAVs
Mar 03, 2023



Miniaturized autonomous unmanned aerial vehicles (UAVs) are an emerging and trending topic. With their form factor as big as the palm of one hand, they can reach spots otherwise inaccessible to bigger robots and safely operate in human surroundings. The simple electronics aboard such robots (sub-100mW) make them particularly cheap and attractive but pose significant challenges in enabling onboard sophisticated intelligence. In this work, we leverage a novel neural architecture search (NAS) technique to automatically identify several Pareto-optimal convolutional neural networks (CNNs) for a visual pose estimation task. Our work demonstrates how real-life and field-tested robotics applications can concretely leverage NAS technologies to automatically and efficiently optimize CNNs for the specific hardware constraints of small UAVs. We deploy several NAS-optimized CNNs and run them in closed-loop aboard a 27-g Crazyflie nano-UAV equipped with a parallel ultra-low power System-on-Chip. Our results improve the State-of-the-Art by reducing the in-field control error of 32% while achieving a real-time onboard inference-rate of ~10Hz@10mW and ~50Hz@90mW.