 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing the Robot's Mind: Sonification for Explicit Feedback in Human-Robot Interaction
Nov 14, 2024Social robots are required not only to understand human intentions but also to effectively communicate their intentions or own internal states to users. This study explores the use of sonification to provide explicit auditory feedback, enhancing mutual understanding in HRI. We introduce a novel sonification approach that conveys the robot's internal state, linked to its perception of nearby individuals and their interaction intentions. The approach is evaluated through a two-fold user study: an online video-based survey with $26$ participants and live experiments with $10$ participants. Results indicate that while sonification improves the robot's expressivity and communication effectiveness, the design of the auditory feedback needs refinement to enhance user experience. Participants found the auditory cues useful but described the sounds as uninteresting and unpleasant. These findings underscore the importance of carefully designed auditory feedback in developing more effective and engaging HRI systems.
Learning Hand State Estimation for a Light Exoskeleton
Nov 14, 2024



We propose a machine learning-based estimator of the hand state for rehabilitation purposes, using light exoskeletons. These devices are easy to use and useful for delivering domestic and frequent therapies. We build a supervised approach using information from the muscular activity of the forearm and the motion of the exoskeleton to reconstruct the hand's opening degree and compliance level. Such information can be used to evaluate the therapy progress and develop adaptive control behaviors. Our approach is validated with a real light exoskeleton. The experiments demonstrate good predictive performance of our approach when trained on data coming from a single user and tested on the same user, even across different sessions. This generalization capability makes our system promising for practical use in real rehabilitation.
A Service Robot in the Wild: Analysis of Users Intentions, Robot Behaviors, and Their Impact on the Interaction
Oct 04, 2024



We consider a service robot that offers chocolate treats to people passing in its proximity: it has the capability of predicting in advance a person's intention to interact, and to actuate an "offering" gesture, subtly extending the tray of chocolates towards a given target. We run the system for more than 5 hours across 3 days and two different crowded public locations; the system implements three possible behaviors that are randomly toggled every few minutes: passive (e.g. never performing the offering gesture); or active, triggered by either a naive distance-based rule, or a smart approach that relies on various behavioral cues of the user. We collect a real-world dataset that includes information on 1777 users with several spontaneous human-robot interactions and study the influence of robot actions on people's behavior. Our comprehensive analysis suggests that users are more prone to engage with the robot when it proactively starts the interaction. We release the dataset and provide insights to make our work reproducible for the community. Also, we report qualitative observations collected during the acquisition campaign and identify future challenges and research directions in the domain of social human-robot interaction.
Predicting the Intention to Interact with a Service Robot:the Role of Gaze Cues
Apr 02, 2024For a service robot, it is crucial to perceive as early as possible that an approaching person intends to interact: in this case, it can proactively enact friendly behaviors that lead to an improved user experience. We solve this perception task with a sequence-to-sequence classifier of a potential user intention to interact, which can be trained in a self-supervised way. Our main contribution is a study of the benefit of features representing the person's gaze in this context. Extensive experiments on a novel dataset show that the inclusion of gaze cues significantly improves the classifier performance (AUROC increases from 84.5% to 91.2%); the distance at which an accurate classification can be achieved improves from 2.4 m to 3.2 m. We also quantify the system's ability to adapt to new environments without external supervision. Qualitative experiments show practical applications with a waiter robot.
A Sim-to-Real Deep Learning-based Framework for Autonomous Nano-drone Racing
Dec 14, 2023



Autonomous drone racing competitions are a proxy to improve unmanned aerial vehicles' perception, planning, and control skills. The recent emergence of autonomous nano-sized drone racing imposes new challenges, as their ~10cm form factor heavily restricts the resources available onboard, including memory, computation, and sensors. This paper describes the methodology and technical implementation of the system winning the first autonomous nano-drone racing international competition: the IMAV 2022 Nanocopter AI Challenge. We developed a fully onboard deep learning approach for visual navigation trained only on simulation images to achieve this goal. Our approach includes a convolutional neural network for obstacle avoidance, a sim-to-real dataset collection procedure, and a navigation policy that we selected, characterized, and adapted through simulation and actual in-field experiments. Our system ranked 1st among seven competing teams at the competition. In our best attempt, we scored 115m of traveled distance in the allotted 5-minute flight, never crashing while dodging static and dynamic obstacles. Sharing our knowledge with the research community, we aim to provide a solid groundwork to foster future development in this field.
Self-Supervised Prediction of the Intention to Interact with a Service Robot
Sep 14, 2023
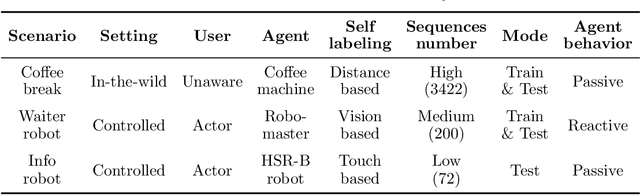

A service robot can provide a smoother interaction experience if it has the ability to proactively detect whether a nearby user intends to interact, in order to adapt its behavior e.g. by explicitly showing that it is available to provide a service. In this work, we propose a learning-based approach to predict the probability that a human user will interact with a robot before the interaction actually begins; the approach is self-supervised because after each encounter with a human, the robot can automatically label it depending on whether it resulted in an interaction or not. We explore different classification approaches, using different sets of features considering the pose and the motion of the user. We validate and deploy the approach in three scenarios. The first collects $3442$ natural sequences (both interacting and non-interacting) representing employees in an office break area: a real-world, challenging setting, where we consider a coffee machine in place of a service robot. The other two scenarios represent researchers interacting with service robots ($200$ and $72$ sequences, respectively). Results show that, even in challenging real-world settings, our approach can learn without external supervision, and can achieve accurate classification (i.e. AUROC greater than $0.9$) of the user's intention to interact with an advance of more than $3$s before the interaction actually occurs.
Semantic Segmentation on Swiss3DCities: A Benchmark Study on Aerial Photogrammetric 3D Pointcloud Dataset
Dec 23, 2020
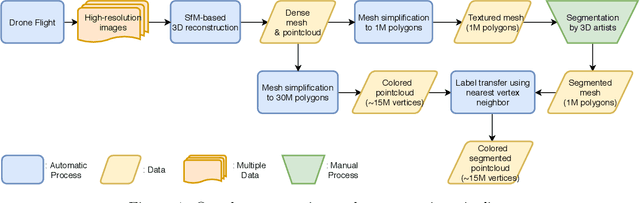
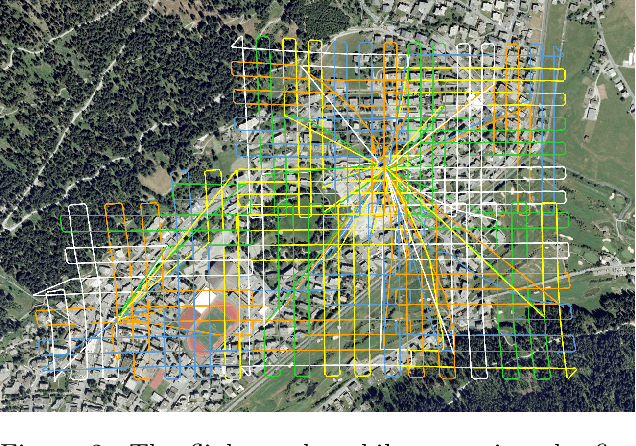

We introduce a new outdoor urban 3D pointcloud dataset, covering a total area of 2.7 $km^2$, sampled from three Swiss cities with different characteristics. The dataset is manually annotated for semantic segmentation with per-point labels, and is built using photogrammetry from images acquired by multirotors equipped with high-resolution cameras. In contrast to datasets acquired with ground LiDAR sensors, the resulting point clouds are uniformly dense and complete, and are useful to disparate applications, including autonomous driving, gaming and smart city planning. As a benchmark, we report quantitative results of PointNet++, an established point-based deep 3D semantic segmentation model; on this model, we additionally study the impact of using different cities for model generalization.