 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Number-Free Text-to-Motion Generation Via Flow Matching
Mar 27, 2026Generative models excel at motion synthesis for a fixed number of agents but struggle to generalize with variable agents. Based on limited, domain-specific data, existing methods employ autoregressive models to generate motion recursively, which suffer from inefficiency and error accumulation. We propose Unified Motion Flow (UMF), which consists of Pyramid Motion Flow (P-Flow) and Semi-Noise Motion Flow (S-Flow). UMF decomposes the number-free motion generation into a single-pass motion prior generation stage and multi-pass reaction generation stages. Specifically, UMF utilizes a unified latent space to bridge the distribution gap between heterogeneous motion datasets, enabling effective unified training. For motion prior generation, P-Flow operates on hierarchical resolutions conditioned on different noise levels, thereby mitigating computational overheads. For reaction generation, S-Flow learns a joint probabilistic path that adaptively performs reaction transformation and context reconstruction, alleviating error accumulation. Extensive results and user studies demonstrate UMF' s effectiveness as a generalist model for multi-person motion generation from text. Project page: https://githubhgh.github.io/umf/.
A Closed-Form Solution for Debiasing Vision-Language Models with Utility Guarantees Across Modalities and Tasks
Mar 13, 2026While Vision-Language Models (VLMs) have achieved remarkable performance across diverse downstream tasks, recent studies have shown that they can inherit social biases from the training data and further propagate them into downstream applications. To address this issue, various debiasing approaches have been proposed, yet most of them aim to improve fairness without having a theoretical guarantee that the utility of the model is preserved. In this paper, we introduce a debiasing method that yields a \textbf{closed-form} solution in the cross-modal space, achieving Pareto-optimal fairness with \textbf{bounded utility losses}. Our method is \textbf{training-free}, requires \textbf{no annotated data}, and can jointly debias both visual and textual modalities across downstream tasks. Extensive experiments show that our method outperforms existing methods in debiasing VLMs across diverse fairness metrics and datasets for both group and \textbf{intersectional} fairness in downstream tasks such as zero-shot image classification, text-to-image retrieval, and text-to-image generation while preserving task performance.
A Feature-level Bias Evaluation Framework for Facial Expression Recognition Models
May 26, 2025Recent studies on fairness have shown that Facial Expression Recognition (FER) models exhibit biases toward certain visually perceived demographic groups. However, the limited availability of human-annotated demographic labels in public FER datasets has constrained the scope of such bias analysis. To overcome this limitation, some prior works have resorted to pseudo-demographic labels, which may distort bias evaluation results. Alternatively, in this paper, we propose a feature-level bias evaluation framework for evaluating demographic biases in FER models under the setting where demographic labels are unavailable in the test set. Extensive experiments demonstrate that our method more effectively evaluates demographic biases compared to existing approaches that rely on pseudo-demographic labels. Furthermore, we observe that many existing studies do not include statistical testing in their bias evaluations, raising concerns that some reported biases may not be statistically significant but rather due to randomness. To address this issue, we introduce a plug-and-play statistical module to ensure the statistical significance of biased evaluation results. A comprehensive bias analysis based on the proposed module is then conducted across three sensitive attributes (age, gender, and race), seven facial expressions, and multiple network architectures on a large-scale dataset, revealing the prominent demographic biases in FER and providing insights on selecting a fairer network architecture.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Efficient Continual Adaptation of Pretrained Robotic Policy with Online Meta-Learned Adapters
Mar 27, 2025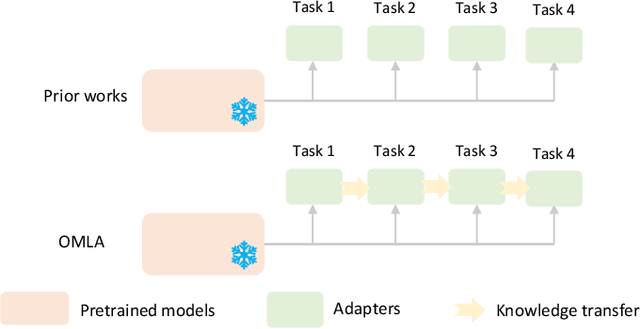
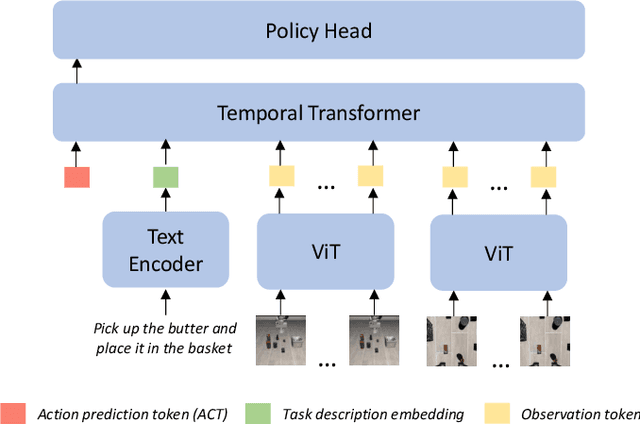
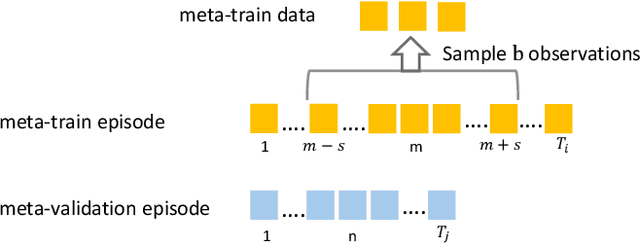

Continual adaptation is essential for general autonomous agents. For example, a household robot pretrained with a repertoire of skills must still adapt to unseen tasks specific to each household. Motivated by this, building upon parameter-efficient fine-tuning in language models, prior works have explored lightweight adapters to adapt pretrained policies, which can preserve learned features from the pretraining phase and demonstrate good adaptation performances. However, these approaches treat task learning separately, limiting knowledge transfer between tasks. In this paper, we propose Online Meta-Learned adapters (OMLA). Instead of applying adapters directly, OMLA can facilitate knowledge transfer from previously learned tasks to current learning tasks through a novel meta-learning objective. Extensive experiments in both simulated and real-world environments demonstrate that OMLA can lead to better adaptation performances compared to the baseline methods. The project link: https://ricky-zhu.github.io/OMLA/.
Are Large Language Models Aligned with People's Social Intuitions for Human-Robot Interactions?
Mar 08, 2024



Large language models (LLMs) are increasingly used in robotics, especially for high-level action planning. Meanwhile, many robotics applications involve human supervisors or collaborators. Hence, it is crucial for LLMs to generate socially acceptable actions that align with people's preferences and values. In this work, we test whether LLMs capture people's intuitions about behavior judgments and communication preferences in human-robot interaction (HRI) scenarios. For evaluation, we reproduce three HRI user studies, comparing the output of LLMs with that of real participants. We find that GPT-4 strongly outperforms other models, generating answers that correlate strongly with users' answers in two studies $\unicode{x2014}$ the first study dealing with selecting the most appropriate communicative act for a robot in various situations ($r_s$ = 0.82), and the second with judging the desirability, intentionality, and surprisingness of behavior ($r_s$ = 0.83). However, for the last study, testing whether people judge the behavior of robots and humans differently, no model achieves strong correlations. Moreover, we show that vision models fail to capture the essence of video stimuli and that LLMs tend to rate different communicative acts and behavior desirability higher than people.
Cross Domain Policy Transfer with Effect Cycle-Consistency
Mar 04, 2024
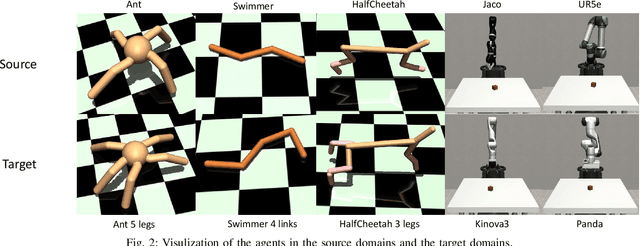
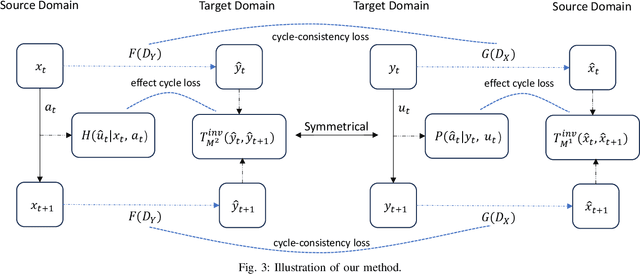
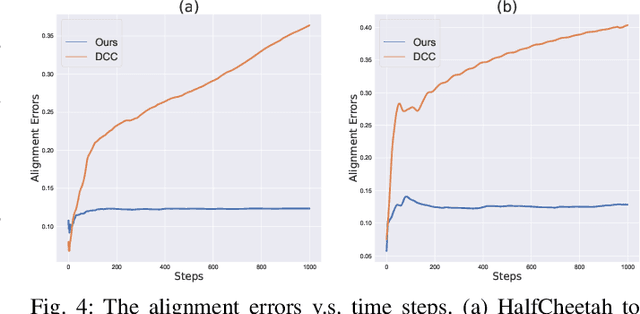
Training a robotic policy from scratch using deep reinforcement learning methods can be prohibitively expensive due to sample inefficiency. To address this challenge, transferring policies trained in the source domain to the target domain becomes an attractive paradigm. Previous research has typically focused on domains with similar state and action spaces but differing in other aspects. In this paper, our primary focus lies in domains with different state and action spaces, which has broader practical implications, i.e. transfer the policy from robot A to robot B. Unlike prior methods that rely on paired data, we propose a novel approach for learning the mapping functions between state and action spaces across domains using unpaired data. We propose effect cycle consistency, which aligns the effects of transitions across two domains through a symmetrical optimization structure for learning these mapping functions. Once the mapping functions are learned, we can seamlessly transfer the policy from the source domain to the target domain. Our approach has been tested on three locomotion tasks and two robotic manipulation tasks. The empirical results demonstrate that our method can reduce alignment errors significantly and achieve better performance compared to the state-of-the-art method.
Self-Supervised Prediction of the Intention to Interact with a Service Robot
Sep 14, 2023
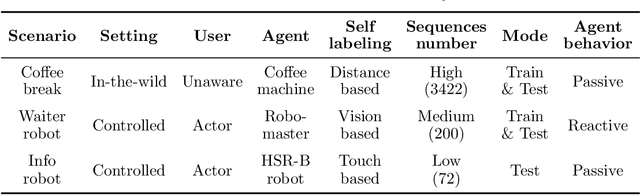

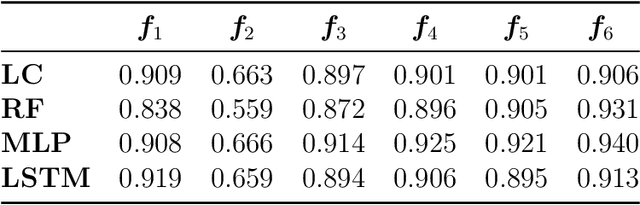
A service robot can provide a smoother interaction experience if it has the ability to proactively detect whether a nearby user intends to interact, in order to adapt its behavior e.g. by explicitly showing that it is available to provide a service. In this work, we propose a learning-based approach to predict the probability that a human user will interact with a robot before the interaction actually begins; the approach is self-supervised because after each encounter with a human, the robot can automatically label it depending on whether it resulted in an interaction or not. We explore different classification approaches, using different sets of features considering the pose and the motion of the user. We validate and deploy the approach in three scenarios. The first collects $3442$ natural sequences (both interacting and non-interacting) representing employees in an office break area: a real-world, challenging setting, where we consider a coffee machine in place of a service robot. The other two scenarios represent researchers interacting with service robots ($200$ and $72$ sequences, respectively). Results show that, even in challenging real-world settings, our approach can learn without external supervision, and can achieve accurate classification (i.e. AUROC greater than $0.9$) of the user's intention to interact with an advance of more than $3$s before the interaction actually occurs.
Learning to Solve Tasks with Exploring Prior Behaviours
Jul 06, 2023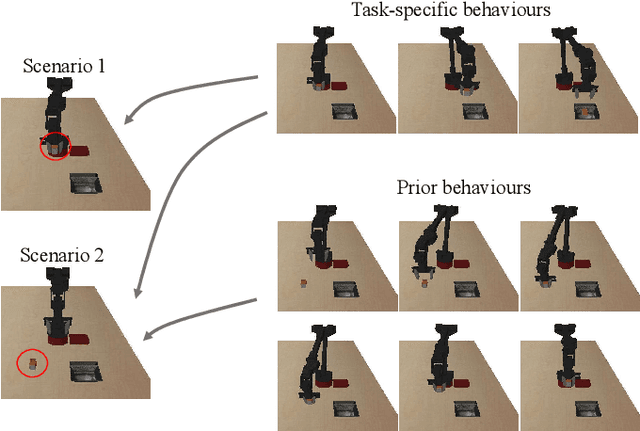
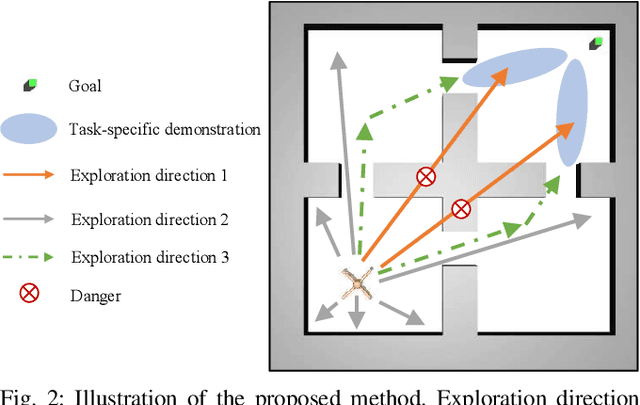
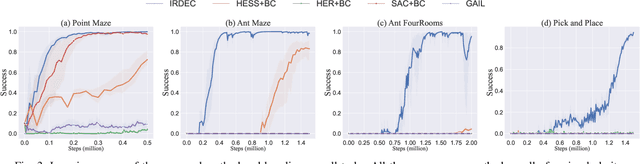
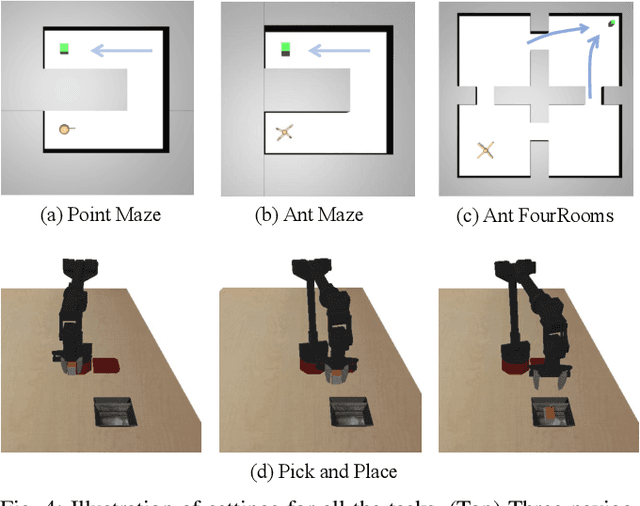
Demonstrations are widely used in Deep Reinforcement Learning (DRL) for facilitating solving tasks with sparse rewards. However, the tasks in real-world scenarios can often have varied initial conditions from the demonstration, which would require additional prior behaviours. For example, consider we are given the demonstration for the task of \emph{picking up an object from an open drawer}, but the drawer is closed in the training. Without acquiring the prior behaviours of opening the drawer, the robot is unlikely to solve the task. To address this, in this paper we propose an Intrinsic Rewards Driven Example-based Control \textbf{(IRDEC)}. Our method can endow agents with the ability to explore and acquire the required prior behaviours and then connect to the task-specific behaviours in the demonstration to solve sparse-reward tasks without requiring additional demonstration of the prior behaviours. The performance of our method outperforms other baselines on three navigation tasks and one robotic manipulation task with sparse rewards. Codes are available at https://github.com/Ricky-Zhu/IRDEC.
Neural Weight Search for Scalable Task Incremental Learning
Nov 24, 2022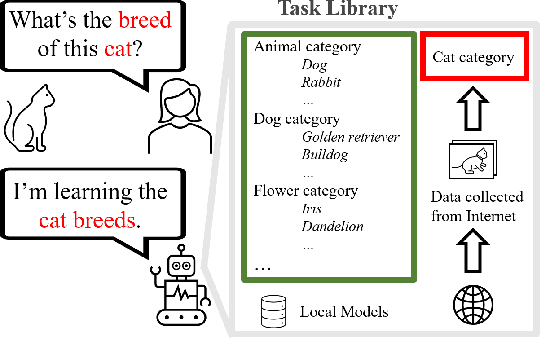
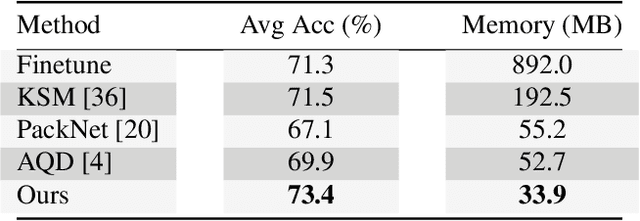
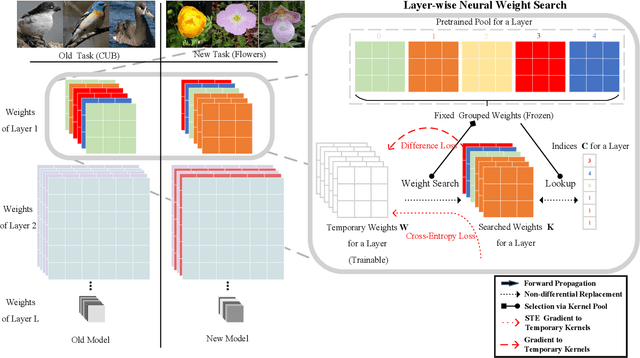
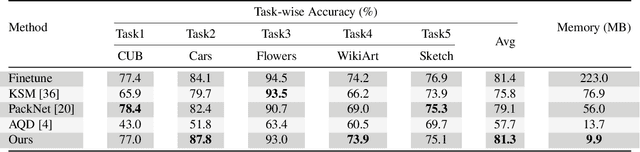
Task incremental learning aims to enable a system to maintain its performance on previously learned tasks while learning new tasks, solving the problem of catastrophic forgetting. One promising approach is to build an individual network or sub-network for future tasks. However, this leads to an ever-growing memory due to saving extra weights for new tasks and how to address this issue has remained an open problem in task incremental learning. In this paper, we introduce a novel Neural Weight Search technique that designs a fixed search space where the optimal combinations of frozen weights can be searched to build new models for novel tasks in an end-to-end manner, resulting in scalable and controllable memory growth. Extensive experiments on two benchmarks, i.e., Split-CIFAR-100 and CUB-to-Sketches, show our method achieves state-of-the-art performance with respect to both average inference accuracy and total memory cost.