 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCISSR: Scribble-Conditioned Interactive Surgical Segmentation and Refinement
Mar 19, 2026Accurate segmentation of tissues and instruments in surgical scenes is annotation-intensive due to irregular shapes, thin structures, specularities, and frequent occlusions. While SAM models support point, box, and mask prompts, points are often too sparse and boxes too coarse to localize such challenging targets. We present SCISSR, a scribble-promptable framework for interactive surgical scene segmentation. It introduces a lightweight Scribble Encoder that converts freehand scribbles into dense prompt embeddings compatible with the mask decoder, enabling iterative refinement for a target object by drawing corrective strokes on error regions. Because all added modules (the Scribble Encoder, Spatial Gated Fusion, and LoRA adapters) interact with the backbone only through its standard embedding interfaces, the framework is not tied to a single model: we build on SAM 2 in this work, yet the same components transfer to other prompt-driven segmentation architectures such as SAM 3 without structural modification. To preserve pre-trained capabilities, we train only these lightweight additions while keeping the remaining backbone frozen. Experiments on EndoVis 2018 demonstrate strong in-domain performance, while evaluation on the out-of-distribution CholecSeg8k further confirms robustness across surgical domains. SCISSR achieves 95.41% Dice on EndoVis 2018 with five interaction rounds and 96.30% Dice on CholecSeg8k with three interaction rounds, outperforming iterative point prompting on both benchmarks.
Surg$Σ$: A Spectrum of Large-Scale Multimodal Data and Foundation Models for Surgical Intelligence
Mar 17, 2026Surgical intelligence has the potential to improve the safety and consistency of surgical care, yet most existing surgical AI frameworks remain task-specific and struggle to generalize across procedures and institutions. Although multimodal foundation models, particularly multimodal large language models, have demonstrated strong cross-task capabilities across various medical domains, their advancement in surgery remains constrained by the lack of large-scale, systematically curated multimodal data. To address this challenge, we introduce Surg$Σ$, a spectrum of large-scale multimodal data and foundation models for surgical intelligence. At the core of this framework lies Surg$Σ$-DB, a large-scale multimodal data foundation designed to support diverse surgical tasks. Surg$Σ$-DB consolidates heterogeneous surgical data sources (including open-source datasets, curated in-house clinical collections and web-source data) into a unified schema, aiming to improve label consistency and data standardization across heterogeneous datasets. Surg$Σ$-DB spans 6 clinical specialties and diverse surgical types, providing rich image- and video-level annotations across 18 practical surgical tasks covering understanding, reasoning, planning, and generation, at an unprecedented scale (over 5.98M conversations). Beyond conventional multimodal conversations, Surg$Σ$-DB incorporates hierarchical reasoning annotations, providing richer semantic cues to support deeper contextual understanding in complex surgical scenarios. We further provide empirical evidence through recently developed surgical foundation models built upon Surg$Σ$-DB, illustrating the practical benefits of large-scale multimodal annotations, unified semantic design, and structured reasoning annotations for improving cross-task generalization and interpretability.
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
Innovative Tooth Segmentation Using Hierarchical Features and Bidirectional Sequence Modeling
Feb 25, 2026Tooth image segmentation is a cornerstone of dental digitization. However, traditional image encoders relying on fixed-resolution feature maps often lead to discontinuous segmentation and poor discrimination between target regions and background, due to insufficient modeling of environmental and global context. Moreover, transformer-based self-attention introduces substantial computational overhead because of its quadratic complexity (O(n^2)), making it inefficient for high-resolution dental images. To address these challenges, we introduce a three-stage encoder with hierarchical feature representation to capture scale-adaptive information in dental images. By jointly leveraging low-level details and high-level semantics through cross-scale feature fusion, the model effectively preserves fine structural information while maintaining strong contextual awareness. Furthermore, a bidirectional sequence modeling strategy is incorporated to enhance global spatial context understanding without incurring high computational cost. We validate our method on two dental datasets, with experimental results demonstrating its superiority over existing approaches. On the OralVision dataset, our model achieves a 1.1% improvement in mean intersection over union (mIoU).
* Accepted by Pattern Recognition
HeteroCache: A Dynamic Retrieval Approach to Heterogeneous KV Cache Compression for Long-Context LLM Inference
Jan 20, 2026The linear memory growth of the KV cache poses a significant bottleneck for LLM inference in long-context tasks. Existing static compression methods often fail to preserve globally important information, principally because they overlook the attention drift phenomenon where token significance evolves dynamically. Although recent dynamic retrieval approaches attempt to address this issue, they typically suffer from coarse-grained caching strategies and incur high I/O overhead due to frequent data transfers. To overcome these limitations, we propose HeteroCache, a training-free dynamic compression framework. Our method is built on two key insights: attention heads exhibit diverse temporal heterogeneity, and there is significant spatial redundancy among heads within the same layer. Guided by these insights, HeteroCache categorizes heads based on stability and redundancy. Consequently, we apply a fine-grained weighting strategy that allocates larger cache budgets to heads with rapidly shifting attention to capture context changes, thereby addressing the inefficiency of coarse-grained strategies. Furthermore, we employ a hierarchical storage mechanism in which a subset of representative heads monitors attention shift, and trigger an asynchronous, on-demand retrieval of contexts from the CPU, effectively hiding I/O latency. Finally, experiments demonstrate that HeteroCache achieves state-of-the-art performance on multiple long-context benchmarks and accelerates decoding by up to $3\times$ compared to the original model in the 224K context. Our code will be open-source.
Proteomic Learning of Gamma-Aminobutyric Acid (GABA) Receptor-Mediated Anesthesia
Jan 06, 2025



Anesthetics are crucial in surgical procedures and therapeutic interventions, but they come with side effects and varying levels of effectiveness, calling for novel anesthetic agents that offer more precise and controllable effects. Targeting Gamma-aminobutyric acid (GABA) receptors, the primary inhibitory receptors in the central nervous system, could enhance their inhibitory action, potentially reducing side effects while improving the potency of anesthetics. In this study, we introduce a proteomic learning of GABA receptor-mediated anesthesia based on 24 GABA receptor subtypes by considering over 4000 proteins in protein-protein interaction (PPI) networks and over 1.5 millions known binding compounds. We develop a corresponding drug-target interaction network to identify potential lead compounds for novel anesthetic design. To ensure robust proteomic learning predictions, we curated a dataset comprising 136 targets from a pool of 980 targets within the PPI networks. We employed three machine learning algorithms, integrating advanced natural language processing (NLP) models such as pretrained transformer and autoencoder embeddings. Through a comprehensive screening process, we evaluated the side effects and repurposing potential of over 180,000 drug candidates targeting the GABRA5 receptor. Additionally, we assessed the ADMET (absorption, distribution, metabolism, excretion, and toxicity) properties of these candidates to identify those with near-optimal characteristics. This approach also involved optimizing the structures of existing anesthetics. Our work presents an innovative strategy for the development of new anesthetic drugs, optimization of anesthetic use, and deeper understanding of potential anesthesia-related side effects.
Is Segment Anything Model 2 All You Need for Surgery Video Segmentation? A Systematic Evaluation
Dec 31, 2024



Surgery video segmentation is an important topic in the surgical AI field. It allows the AI model to understand the spatial information of a surgical scene. Meanwhile, due to the lack of annotated surgical data, surgery segmentation models suffer from limited performance. With the emergence of SAM2 model, a large foundation model for video segmentation trained on natural videos, zero-shot surgical video segmentation became more realistic but meanwhile remains to be explored. In this paper, we systematically evaluate the performance of SAM2 model in zero-shot surgery video segmentation task. We conducted experiments under different configurations, including different prompting strategies, robustness, etc. Moreover, we conducted an empirical evaluation over the performance, including 9 datasets with 17 different types of surgeries.
CP-DETR: Concept Prompt Guide DETR Toward Stronger Universal Object Detection
Dec 13, 2024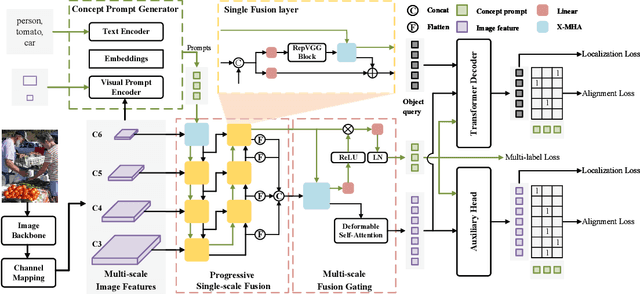
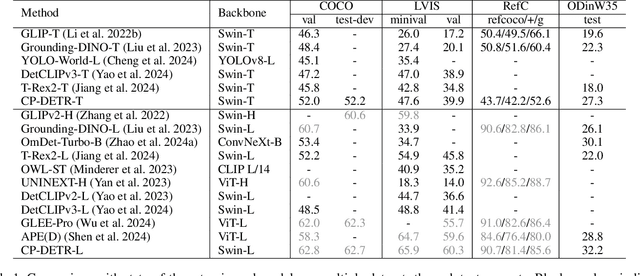
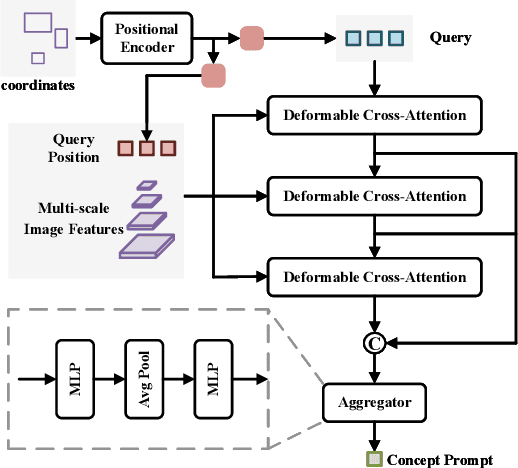
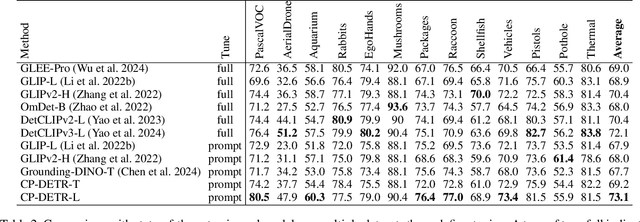
Recent research on universal object detection aims to introduce language in a SoTA closed-set detector and then generalize the open-set concepts by constructing large-scale (text-region) datasets for training. However, these methods face two main challenges: (i) how to efficiently use the prior information in the prompts to genericise objects and (ii) how to reduce alignment bias in the downstream tasks, both leading to sub-optimal performance in some scenarios beyond pre-training. To address these challenges, we propose a strong universal detection foundation model called CP-DETR, which is competitive in almost all scenarios, with only one pre-training weight. Specifically, we design an efficient prompt visual hybrid encoder that enhances the information interaction between prompt and visual through scale-by-scale and multi-scale fusion modules. Then, the hybrid encoder is facilitated to fully utilize the prompted information by prompt multi-label loss and auxiliary detection head. In addition to text prompts, we have designed two practical concept prompt generation methods, visual prompt and optimized prompt, to extract abstract concepts through concrete visual examples and stably reduce alignment bias in downstream tasks. With these effective designs, CP-DETR demonstrates superior universal detection performance in a broad spectrum of scenarios. For example, our Swin-T backbone model achieves 47.6 zero-shot AP on LVIS, and the Swin-L backbone model achieves 32.2 zero-shot AP on ODinW35. Furthermore, our visual prompt generation method achieves 68.4 AP on COCO val by interactive detection, and the optimized prompt achieves 73.1 fully-shot AP on ODinW13.
Exploration of visual prompt in Grounded pre-trained open-set detection
Dec 14, 2023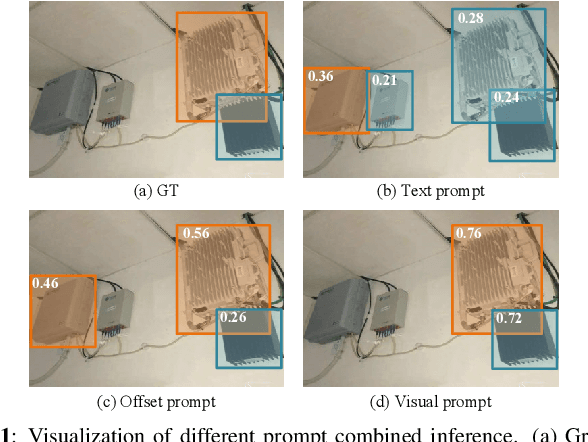
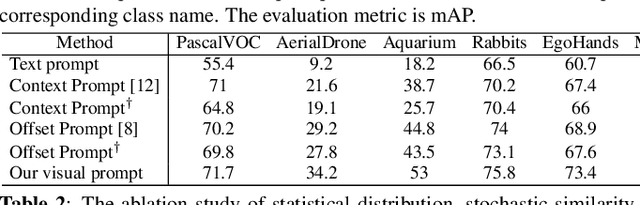
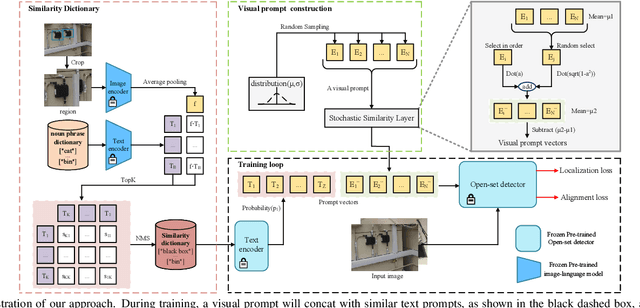
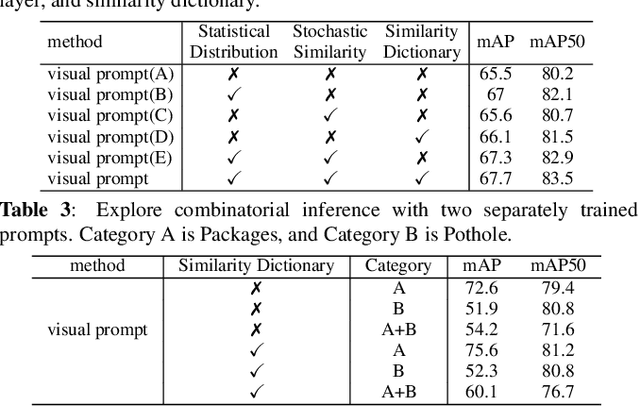
Text prompts are crucial for generalizing pre-trained open-set object detection models to new categories. However, current methods for text prompts are limited as they require manual feedback when generalizing to new categories, which restricts their ability to model complex scenes, often leading to incorrect detection results. To address this limitation, we propose a novel visual prompt method that learns new category knowledge from a few labeled images, which generalizes the pre-trained detection model to the new category. To allow visual prompts to represent new categories adequately, we propose a statistical-based prompt construction module that is not limited by predefined vocabulary lengths, thus allowing more vectors to be used when representing categories. We further utilize the category dictionaries in the pre-training dataset to design task-specific similarity dictionaries, which make visual prompts more discriminative. We evaluate the method on the ODinW dataset and show that it outperforms existing prompt learning methods and performs more consistently in combinatorial inference.
Machine Learning Study of the Extended Drug-target Interaction Network informed by Pain Related Voltage-Gated Sodium Channels
Jul 11, 2023



Pain is a significant global health issue, and the current treatment options for pain management have limitations in terms of effectiveness, side effects, and potential for addiction. There is a pressing need for improved pain treatments and the development of new drugs. Voltage-gated sodium channels, particularly Nav1.3, Nav1.7, Nav1.8, and Nav1.9, play a crucial role in neuronal excitability and are predominantly expressed in the peripheral nervous system. Targeting these channels may provide a means to treat pain while minimizing central and cardiac adverse effects. In this study, we construct protein-protein interaction (PPI) networks based on pain-related sodium channels and develop a corresponding drug-target interaction (DTI) network to identify potential lead compounds for pain management. To ensure reliable machine learning predictions, we carefully select 111 inhibitor datasets from a pool of over 1,000 targets in the PPI network. We employ three distinct machine learning algorithms combined with advanced natural language processing (NLP)-based embeddings, specifically pre-trained transformer and autoencoder representations. Through a systematic screening process, we evaluate the side effects and repurposing potential of over 150,000 drug candidates targeting Nav1.7 and Nav1.8 sodium channels. Additionally, we assess the ADMET (absorption, distribution, metabolism, excretion, and toxicity) properties of these candidates to identify leads with near-optimal characteristics. Our strategy provides an innovative platform for the pharmacological development of pain treatments, offering the potential for improved efficacy and reduced side effects.