 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroad Critic Deep Actor Reinforcement Learning for Continuous Control
Nov 24, 2024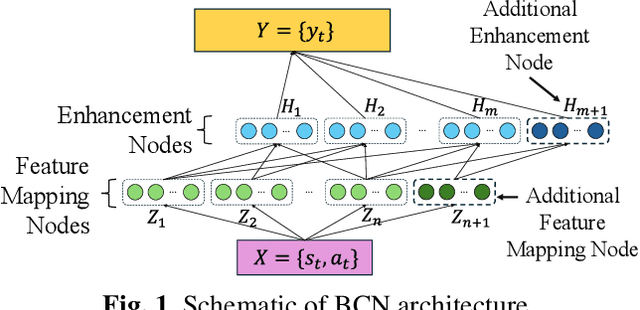
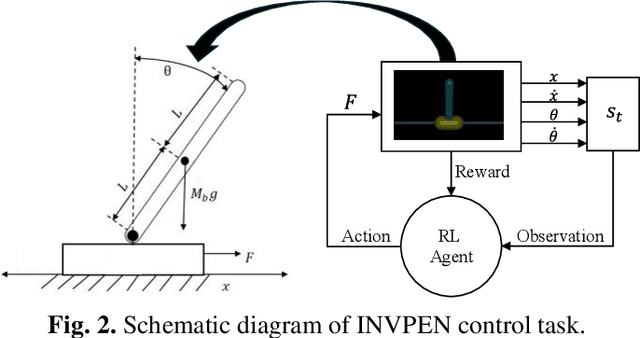
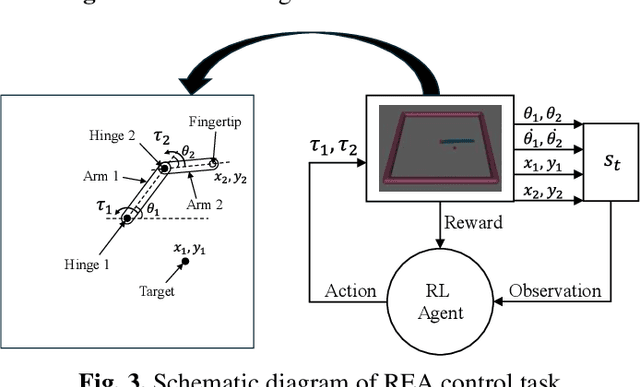
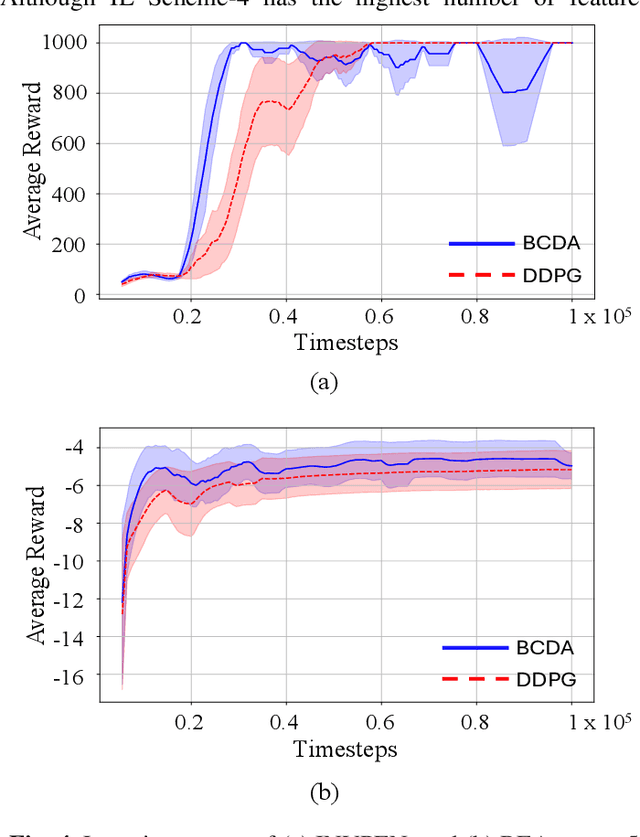
In the domain of continuous control, deep reinforcement learning (DRL) demonstrates promising results. However, the dependence of DRL on deep neural networks (DNNs) results in the demand for extensive data and increased computational complexity. To address this issue, a novel hybrid architecture for actor-critic reinforcement learning (RL) algorithms is introduced. The proposed architecture integrates the broad learning system (BLS) with DNN, aiming to merge the strengths of both distinct architectural paradigms. Specifically, the critic network is implemented using BLS, while the actor network is constructed with a DNN. For the estimations of the critic network parameters, ridge regression is employed, and the parameters of the actor network are optimized through gradient descent. The effectiveness of the proposed algorithm is evaluated by applying it to two classic continuous control tasks, and its performance is compared with the widely recognized deep deterministic policy gradient (DDPG) algorithm. Numerical results show that the proposed algorithm is superior to the DDPG algorithm in terms of computational efficiency, along with an accelerated learning trajectory. Application of the proposed algorithm in other actor-critic RL algorithms is suggested for investigation in future studies.
Exploration of visual prompt in Grounded pre-trained open-set detection
Dec 14, 2023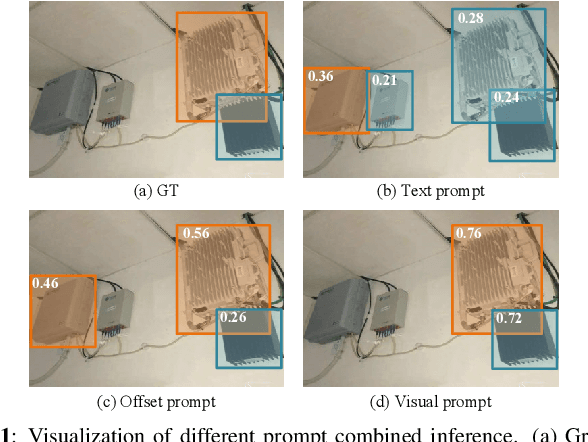
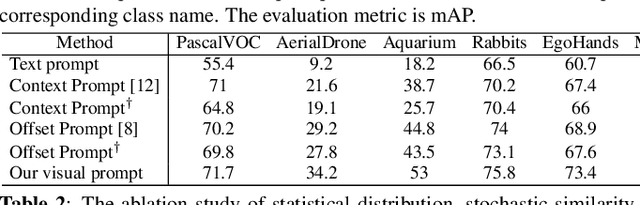
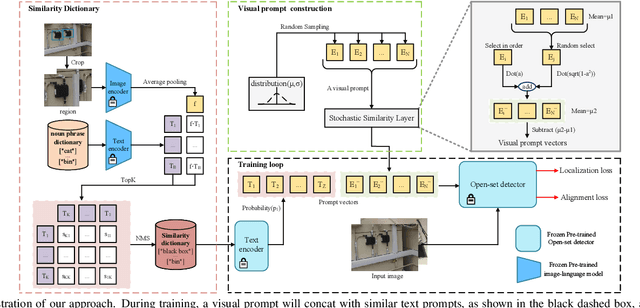
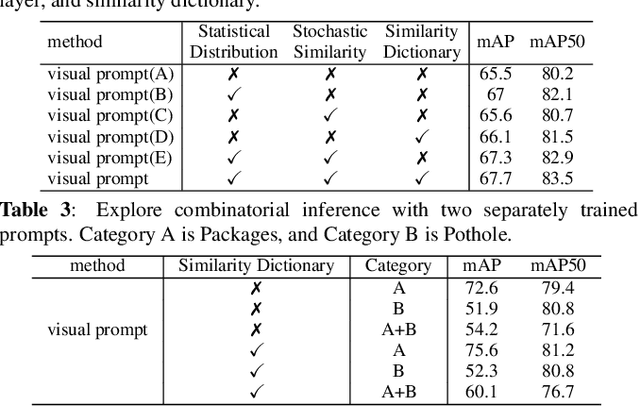
Text prompts are crucial for generalizing pre-trained open-set object detection models to new categories. However, current methods for text prompts are limited as they require manual feedback when generalizing to new categories, which restricts their ability to model complex scenes, often leading to incorrect detection results. To address this limitation, we propose a novel visual prompt method that learns new category knowledge from a few labeled images, which generalizes the pre-trained detection model to the new category. To allow visual prompts to represent new categories adequately, we propose a statistical-based prompt construction module that is not limited by predefined vocabulary lengths, thus allowing more vectors to be used when representing categories. We further utilize the category dictionaries in the pre-training dataset to design task-specific similarity dictionaries, which make visual prompts more discriminative. We evaluate the method on the ODinW dataset and show that it outperforms existing prompt learning methods and performs more consistently in combinatorial inference.