 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparser, Faster, Lighter Transformer Language Models
Mar 24, 2026Scaling autoregressive large language models (LLMs) has driven unprecedented progress but comes with vast computational costs. In this work, we tackle these costs by leveraging unstructured sparsity within an LLM's feedforward layers, the components accounting for most of the model parameters and execution FLOPs. To achieve this, we introduce a new sparse packing format and a set of CUDA kernels designed to seamlessly integrate with the optimized execution pipelines of modern GPUs, enabling efficient sparse computation during LLM inference and training. To substantiate our gains, we provide a quantitative study of LLM sparsity, demonstrating that simple L1 regularization can induce over 99% sparsity with negligible impact on downstream performance. When paired with our kernels, we show that these sparsity levels translate into substantial throughput, energy efficiency, and memory usage benefits that increase with model scale. We will release all code and kernels under an open-source license to promote adoption and accelerate research toward establishing sparsity as a practical axis for improving the efficiency and scalability of modern foundation models.
Doc-to-LoRA: Learning to Instantly Internalize Contexts
Feb 13, 2026Long input sequences are central to in-context learning, document understanding, and multi-step reasoning of Large Language Models (LLMs). However, the quadratic attention cost of Transformers makes inference memory-intensive and slow. While context distillation (CD) can transfer information into model parameters, per-prompt distillation is impractical due to training costs and latency. To address these limitations, we propose Doc-to-LoRA (D2L), a lightweight hypernetwork that meta-learns to perform approximate CD within a single forward pass. Given an unseen prompt, D2L generates a LoRA adapter for a target LLM, enabling subsequent queries to be answered without re-consuming the original context, reducing latency and KV-cache memory consumption during inference of the target LLM. On a long-context needle-in-a-haystack task, D2L successfully learns to map contexts into adapters that store the needle information, achieving near-perfect zero-shot accuracy at sequence lengths exceeding the target LLM's native context window by more than 4x. On real-world QA datasets with limited compute, D2L outperforms standard CD while significantly reducing peak memory consumption and update latency. We envision that D2L can facilitate rapid adaptation of LLMs, opening up the possibility of frequent knowledge updates and personalized chat behavior.
Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
Dec 13, 2025



So far, expensive finetuning beyond the pretraining sequence length has been a requirement for effectively extending the context of language models (LM). In this work, we break this key bottleneck by Dropping the Positional Embeddings of LMs after training (DroPE). Our simple method is motivated by three key theoretical and empirical observations. First, positional embeddings (PEs) serve a crucial role during pretraining, providing an important inductive bias that significantly facilitates convergence. Second, over-reliance on this explicit positional information is also precisely what prevents test-time generalization to sequences of unseen length, even when using popular PE-scaling methods. Third, positional embeddings are not an inherent requirement of effective language modeling and can be safely removed after pretraining, following a short recalibration phase. Empirically, DroPE yields seamless zero-shot context extension without any long-context finetuning, quickly adapting pretrained LMs without compromising their capabilities in the original training context. Our findings hold across different models and dataset sizes, far outperforming previous specialized architectures and established rotary positional embedding scaling methods.
Reinforcement Learning Teachers of Test Time Scaling
Jun 10, 2025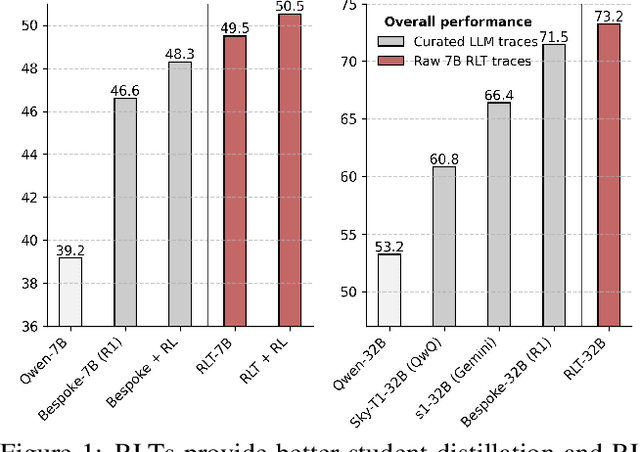
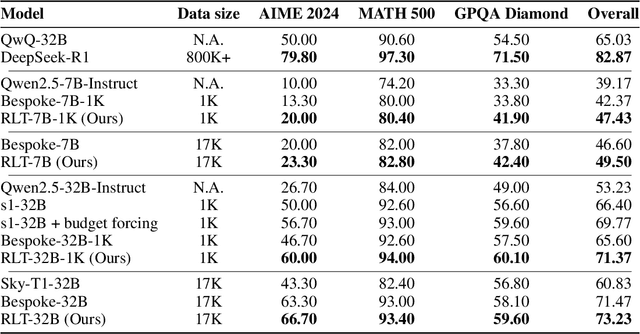

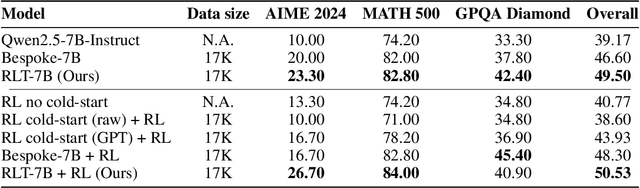
Training reasoning language models (LMs) with reinforcement learning (RL) for one-hot correctness inherently relies on the LM being able to explore and solve its task with some chance at initialization. Furthermore, a key use case of reasoning LMs is to act as teachers for distilling new students and cold-starting future RL iterations rather than being deployed themselves. From these considerations, we introduce a new framework that avoids RL's exploration challenge by training a new class of Reinforcement-Learned Teachers (RLTs) focused on yielding the most effective downstream distillation. RLTs are prompted with both the question and solution to each problem, and tasked to simply "connect-the-dots" with detailed explanations tailored for their students. We train RLTs with dense rewards obtained by feeding each explanation to the student and testing its understanding of the problem's solution. In practice, the raw outputs of a 7B RLT provide higher final performance on competition and graduate-level tasks than existing distillation and cold-starting pipelines that collect and postprocess the reasoning traces of orders of magnitude larger LMs. Furthermore, RLTs maintain their effectiveness when training larger students and when applied zero-shot to out-of-distribution tasks, unlocking new levels of efficiency and re-usability for the RL reasoning framework.
Text-to-LoRA: Instant Transformer Adaption
Jun 06, 2025While Foundation Models provide a general tool for rapid content creation, they regularly require task-specific adaptation. Traditionally, this exercise involves careful curation of datasets and repeated fine-tuning of the underlying model. Fine-tuning techniques enable practitioners to adapt foundation models for many new applications but require expensive and lengthy training while being notably sensitive to hyper-parameter choices. To overcome these limitations, we introduce Text-to-LoRA (T2L), a model capable of adapting Large Language Models on the fly solely based on a natural language description of the target task. T2L is a hypernetwork trained to construct LoRAs in a single inexpensive forward pass. After training T2L on a suite of 9 pre-trained LoRA adapters (GSM8K, Arc, etc.), we show that the ad-hoc reconstructed LoRA instances match the performance of task-specific adapters across the corresponding test sets. Furthermore, T2L can compress hundreds of LoRA instances and zero-shot generalize to entirely unseen tasks. This approach provides a significant step towards democratizing the specialization of foundation models and enables language-based adaptation with minimal compute requirements. Our code is available at https://github.com/SakanaAI/text-to-lora
Sudoku-Bench: Evaluating creative reasoning with Sudoku variants
May 22, 2025



Existing reasoning benchmarks for large language models (LLMs) frequently fail to capture authentic creativity, often rewarding memorization of previously observed patterns. We address this shortcoming with Sudoku-Bench, a curated benchmark of challenging and unconventional Sudoku variants specifically selected to evaluate creative, multi-step logical reasoning. Sudoku variants form an unusually effective domain for reasoning research: each puzzle introduces unique or subtly interacting constraints, making memorization infeasible and requiring solvers to identify novel logical breakthroughs (``break-ins''). Despite their diversity, Sudoku variants maintain a common and compact structure, enabling clear and consistent evaluation. Sudoku-Bench includes a carefully chosen puzzle set, a standardized text-based puzzle representation, and flexible tools compatible with thousands of publicly available puzzles -- making it easy to extend into a general research environment. Baseline experiments show that state-of-the-art LLMs solve fewer than 15\% of puzzles unaided, highlighting significant opportunities to advance long-horizon, strategic reasoning capabilities.
Large Language Models to Diffusion Finetuning
Jan 27, 2025



We propose a new finetuning method to provide pre-trained large language models (LMs) the ability to scale test-time compute through the diffusion framework. By increasing the number of diffusion steps, we show our finetuned models achieve monotonically increasing accuracy, directly translating to improved performance across downstream tasks. Furthermore, our finetuned models can expertly answer questions on specific topics by integrating powerful guidance techniques, and autonomously determine the compute required for a given problem by leveraging adaptive ODE solvers. Our method is universally applicable to any foundation model pre-trained with a cross-entropy loss and does not modify any of its original weights, fully preserving its strong single-step generation capabilities. We show our method is more effective and fully compatible with traditional finetuning approaches, introducing an orthogonal new direction to unify the strengths of the autoregressive and diffusion frameworks.
$\text{Transformer}^2$: Self-adaptive LLMs
Jan 14, 2025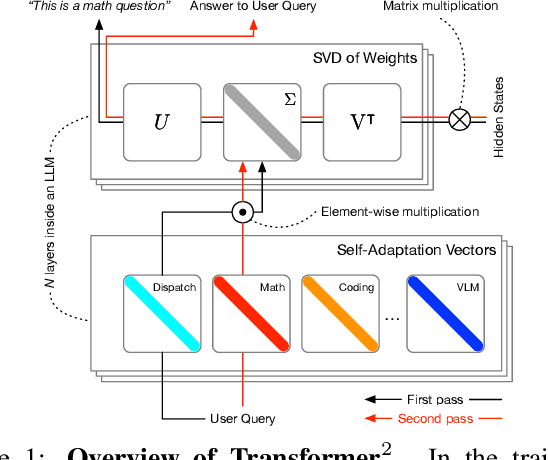
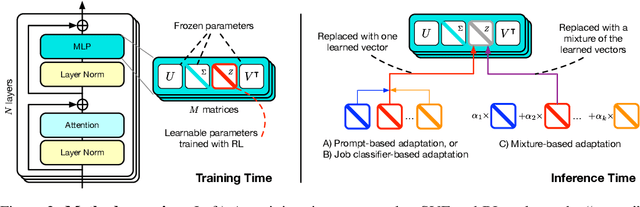
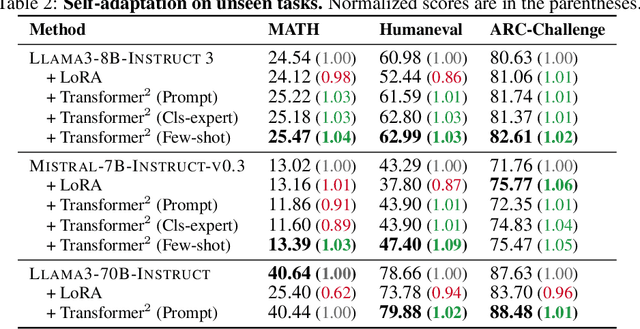

Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse tasks. We introduce $\text{Transformer}^2$, a novel self-adaptation framework that adapts LLMs for unseen tasks in real-time by selectively adjusting only the singular components of their weight matrices. During inference, $\text{Transformer}^2$ employs a two-pass mechanism: first, a dispatch system identifies the task properties, and then task-specific "expert" vectors, trained using reinforcement learning, are dynamically mixed to obtain targeted behavior for the incoming prompt. Our method outperforms ubiquitous approaches such as LoRA, with fewer parameters and greater efficiency. $\text{Transformer}^2$ demonstrates versatility across different LLM architectures and modalities, including vision-language tasks. $\text{Transformer}^2$ represents a significant leap forward, offering a scalable, efficient solution for enhancing the adaptability and task-specific performance of LLMs, paving the way for truly dynamic, self-organizing AI systems.
Finer Behavioral Foundation Models via Auto-Regressive Features and Advantage Weighting
Dec 05, 2024



The forward-backward representation (FB) is a recently proposed framework (Touati et al., 2023; Touati & Ollivier, 2021) to train behavior foundation models (BFMs) that aim at providing zero-shot efficient policies for any new task specified in a given reinforcement learning (RL) environment, without training for each new task. Here we address two core limitations of FB model training. First, FB, like all successor-feature-based methods, relies on a linear encoding of tasks: at test time, each new reward function is linearly projected onto a fixed set of pre-trained features. This limits expressivity as well as precision of the task representation. We break the linearity limitation by introducing auto-regressive features for FB, which let finegrained task features depend on coarser-grained task information. This can represent arbitrary nonlinear task encodings, thus significantly increasing expressivity of the FB framework. Second, it is well-known that training RL agents from offline datasets often requires specific techniques.We show that FB works well together with such offline RL techniques, by adapting techniques from (Nair et al.,2020b; Cetin et al., 2024) for FB. This is necessary to get non-flatlining performance in some datasets, such as DMC Humanoid. As a result, we produce efficient FB BFMs for a number of new environments. Notably, in the D4RL locomotion benchmark, the generic FB agent matches the performance of standard single-task offline agents (IQL, XQL). In many setups, the offline techniques are needed to get any decent performance at all. The auto-regressive features have a positive but moderate impact, concentrated on tasks requiring spatial precision and task generalization beyond the behaviors represented in the trainset.
An Evolved Universal Transformer Memory
Oct 17, 2024



Prior methods propose to offset the escalating costs of modern foundation models by dropping specific parts of their contexts with hand-designed rules, while attempting to preserve their original performance. We overcome this trade-off with Neural Attention Memory Models (NAMMs), introducing a learned network for memory management that improves both the performance and efficiency of transformers. We evolve NAMMs atop pre-trained transformers to provide different latent contexts focusing on the most relevant information for individual layers and attention heads.NAMMs are universally applicable to any model using self-attention as they condition exclusively on the values in the produced attention matrices. Learning NAMMs on a small set of problems, we achieve substantial performance improvements across multiple long-context benchmarks while cutting the model's input contexts up to a fraction of the original sizes. We show the generality of our conditioning enables zero-shot transfer of NAMMs trained only on language to entirely new transformer architectures even across input modalities, with their benefits carrying over to vision and reinforcement learning.