 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Behavior Cloning Improves Causal Reasoning: An Open Model for Real-Time Video Game Playing
Jan 08, 2026Behavior cloning is enjoying a resurgence in popularity as scaling both model and data sizes proves to provide a strong starting point for many tasks of interest. In this work, we introduce an open recipe for training a video game playing foundation model designed for inference in realtime on a consumer GPU. We release all data (8300+ hours of high quality human gameplay), training and inference code, and pretrained checkpoints under an open license. We show that our best model is capable of playing a variety of 3D video games at a level competitive with human play. We use this recipe to systematically examine the scaling laws of behavior cloning to understand how the model's performance and causal reasoning varies with model and data scale. We first show in a simple toy problem that, for some types of causal reasoning, increasing both the amount of training data and the depth of the network results in the model learning a more causal policy. We then systematically study how causality varies with the number of parameters (and depth) and training steps in scaled models of up to 1.2 billion parameters, and we find similar scaling results to what we observe in the toy problem.
Pixels to Play: A Foundation Model for 3D Gameplay
Aug 19, 2025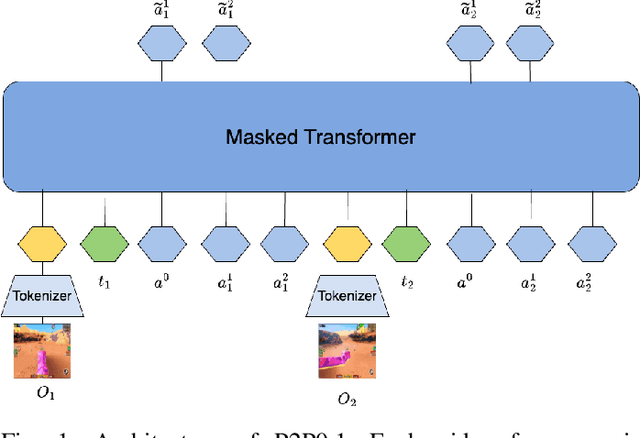
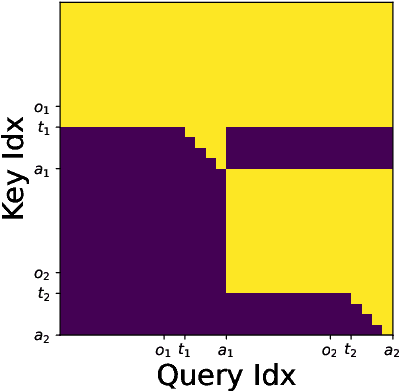

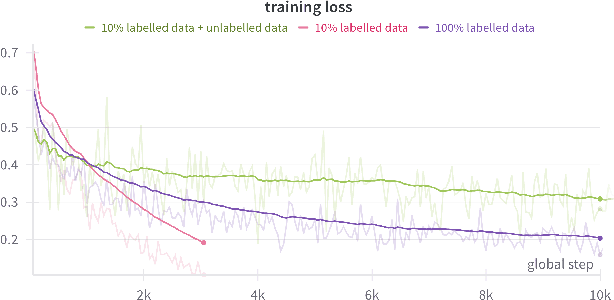
We introduce Pixels2Play-0.1 (P2P0.1), a foundation model that learns to play a wide range of 3D video games with recognizable human-like behavior. Motivated by emerging consumer and developer use cases - AI teammates, controllable NPCs, personalized live-streamers, assistive testers - we argue that an agent must rely on the same pixel stream available to players and generalize to new titles with minimal game-specific engineering. P2P0.1 is trained end-to-end with behavior cloning: labeled demonstrations collected from instrumented human game-play are complemented by unlabeled public videos, to which we impute actions via an inverse-dynamics model. A decoder-only transformer with auto-regressive action output handles the large action space while remaining latency-friendly on a single consumer GPU. We report qualitative results showing competent play across simple Roblox and classic MS-DOS titles, ablations on unlabeled data, and outline the scaling and evaluation steps required to reach expert-level, text-conditioned control.
Hyperbolic Deep Reinforcement Learning
Oct 04, 2022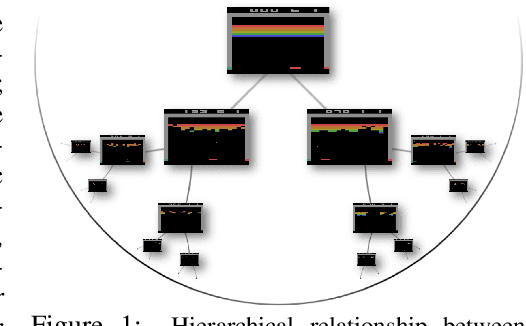
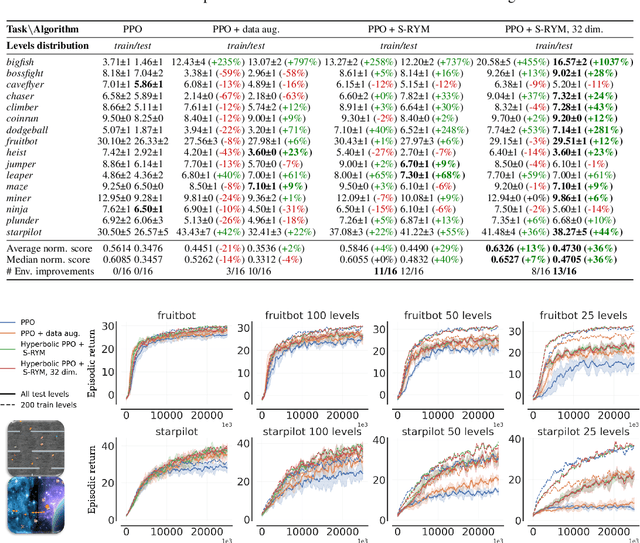
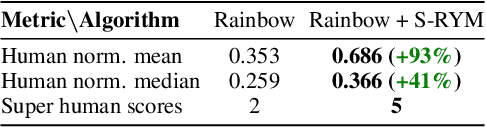
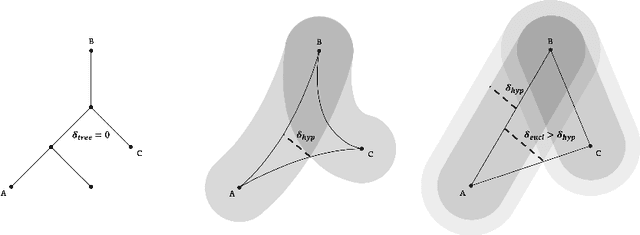
We propose a new class of deep reinforcement learning (RL) algorithms that model latent representations in hyperbolic space. Sequential decision-making requires reasoning about the possible future consequences of current behavior. Consequently, capturing the relationship between key evolving features for a given task is conducive to recovering effective policies. To this end, hyperbolic geometry provides deep RL models with a natural basis to precisely encode this inherently hierarchical information. However, applying existing methodologies from the hyperbolic deep learning literature leads to fatal optimization instabilities due to the non-stationarity and variance characterizing RL gradient estimators. Hence, we design a new general method that counteracts such optimization challenges and enables stable end-to-end learning with deep hyperbolic representations. We empirically validate our framework by applying it to popular on-policy and off-policy RL algorithms on the Procgen and Atari 100K benchmarks, attaining near universal performance and generalization benefits. Given its natural fit, we hope future RL research will consider hyperbolic representations as a standard tool.
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Aug 12, 2022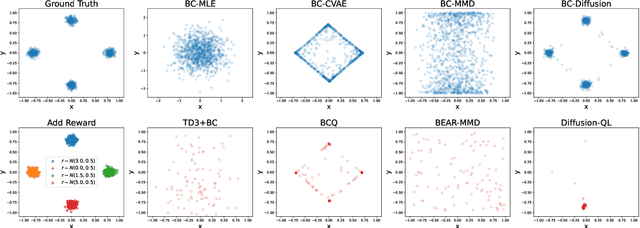
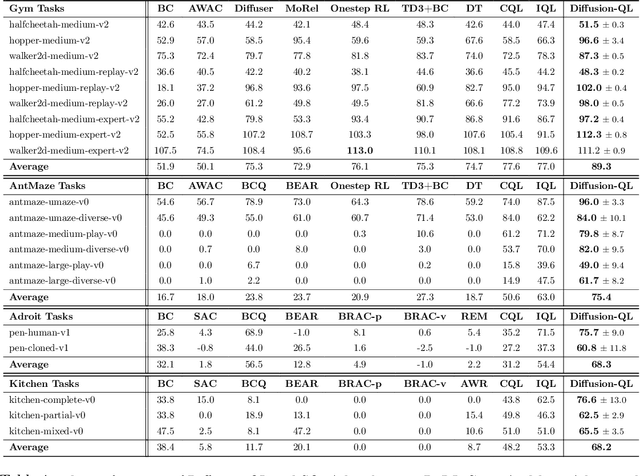
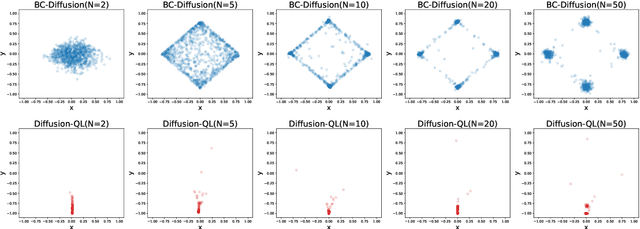
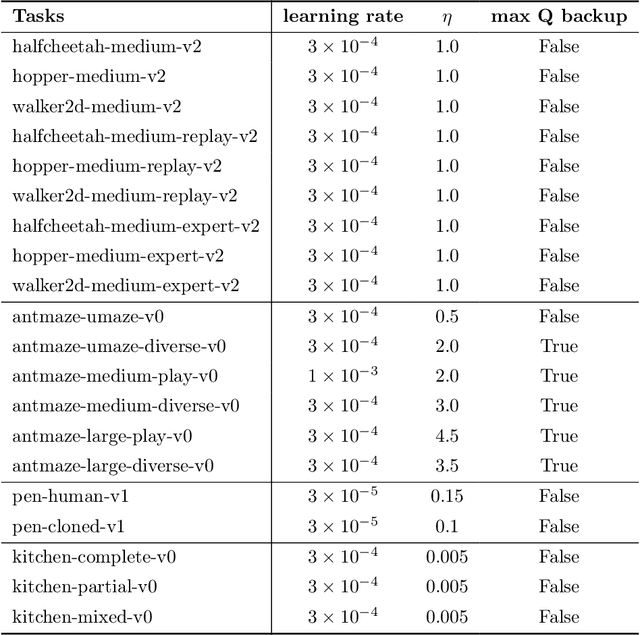
Offline reinforcement learning (RL), which aims to learn an optimal policy using a previously collected static dataset, is an important paradigm of RL. Standard RL methods often perform poorly at this task due to the function approximation errors on out-of-distribution actions. While a variety of regularization methods have been proposed to mitigate this issue, they are often constrained by policy classes with limited expressiveness and sometimes result in substantially suboptimal solutions. In this paper, we propose Diffusion-QL that utilizes a conditional diffusion model as a highly expressive policy class for behavior cloning and policy regularization. In our approach, we learn an action-value function and we add a term maximizing action-values into the training loss of a conditional diffusion model, which results in a loss that seeks optimal actions that are near the behavior policy. We show the expressiveness of the diffusion model-based policy and the coupling of the behavior cloning and policy improvement under the diffusion model both contribute to the outstanding performance of Diffusion-QL. We illustrate our method and prior work in a simple 2D bandit example with a multimodal behavior policy. We then show that our method can achieve state-of-the-art performance on the majority of the D4RL benchmark tasks for offline RL.
Should I send this notification? Optimizing push notifications decision making by modeling the future
Feb 17, 2022Most recommender systems are myopic, that is they optimize based on the immediate response of the user. This may be misaligned with the true objective, such as creating long term user satisfaction. In this work we focus on mobile push notifications, where the long term effects of recommender system decisions can be particularly strong. For example, sending too many or irrelevant notifications may annoy a user and cause them to disable notifications. However, a myopic system will always choose to send a notification since negative effects occur in the future. This is typically mitigated using heuristics. However, heuristics can be hard to reason about or improve, require retuning each time the system is changed, and may be suboptimal. To counter these drawbacks, there is significant interest in recommender systems that optimize directly for long-term value (LTV). Here, we describe a method for maximising LTV by using model-based reinforcement learning (RL) to make decisions about whether to send push notifications. We model the effects of sending a notification on the user's future behavior. Much of the prior work applying RL to maximise LTV in recommender systems has focused on session-based optimization, while the time horizon for notification decision making in this work extends over several days. We test this approach in an A/B test on a major social network. We show that by optimizing decisions about push notifications we are able to send less notifications and obtain a higher open rate than the baseline system, while generating the same level of user engagement on the platform as the existing, heuristic-based, system.
Challenges and approaches to privacy preserving post-click conversion prediction
Jan 29, 2022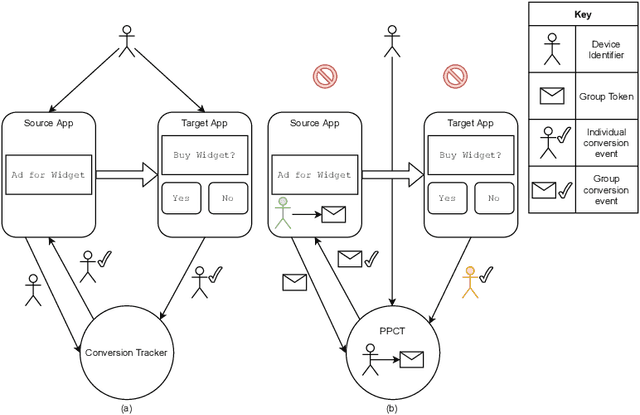
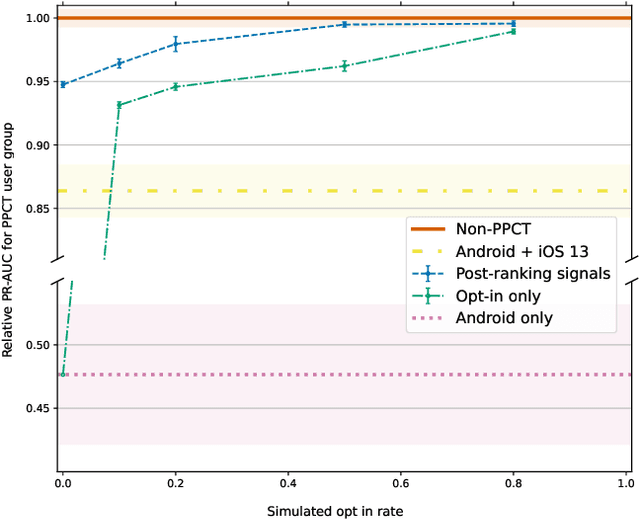
Online advertising has typically been more personalized than offline advertising, through the use of machine learning models and real-time auctions for ad targeting. One specific task, predicting the likelihood of conversion (i.e.\ the probability a user will purchase the advertised product), is crucial to the advertising ecosystem for both targeting and pricing ads. Currently, these models are often trained by observing individual user behavior, but, increasingly, regulatory and technical constraints are requiring privacy-preserving approaches. For example, major platforms are moving to restrict tracking individual user events across multiple applications, and governments around the world have shown steadily more interest in regulating the use of personal data. Instead of receiving data about individual user behavior, advertisers may receive privacy-preserving feedback, such as the number of installs of an advertised app that resulted from a group of users. In this paper we outline the recent privacy-related changes in the online advertising ecosystem from a machine learning perspective. We provide an overview of the challenges and constraints when learning conversion models in this setting. We introduce a novel approach for training these models that makes use of post-ranking signals. We show using offline experiments on real world data that it outperforms a model relying on opt-in data alone, and significantly reduces model degradation when no individual labels are available. Finally, we discuss future directions for research in this evolving area.
Learning to Rank For Push Notifications Using Pairwise Expected Regret
Jan 19, 2022

Listwise ranking losses have been widely studied in recommender systems. However, new paradigms of content consumption present new challenges for ranking methods. In this work we contribute an analysis of learning to rank for personalized mobile push notifications and discuss the unique challenges this presents compared to traditional ranking problems. To address these challenges, we introduce a novel ranking loss based on weighting the pairwise loss between candidates by the expected regret incurred for misordering the pair. We demonstrate that the proposed method can outperform prior methods both in a simulated environment and in a production experiment on a major social network.
An Analysis Of Entire Space Multi-Task Models For Post-Click Conversion Prediction
Aug 18, 2021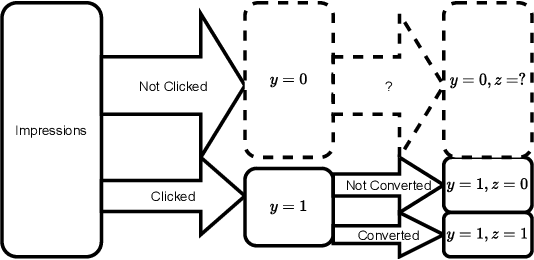
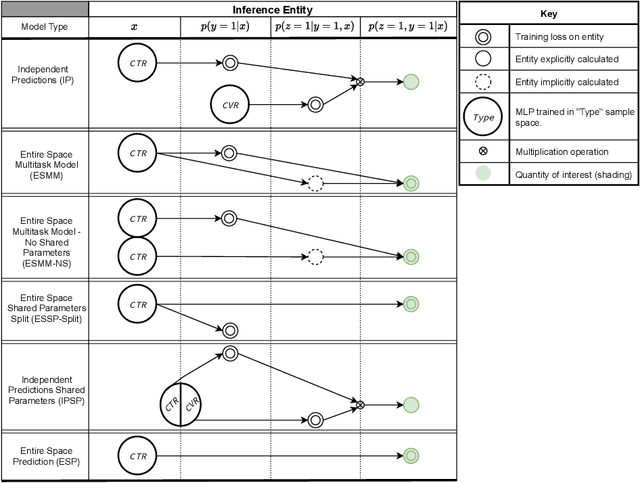
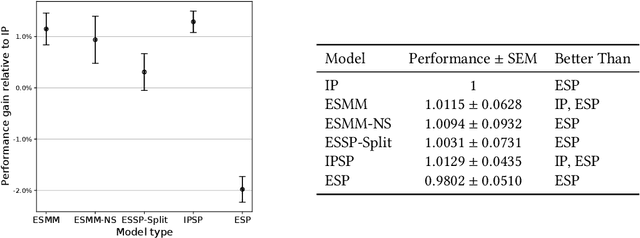
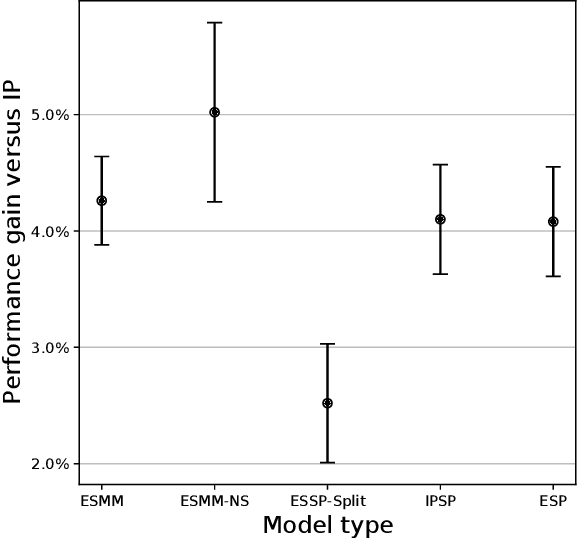
Industrial recommender systems are frequently tasked with approximating probabilities for multiple, often closely related, user actions. For example, predicting if a user will click on an advertisement and if they will then purchase the advertised product. The conceptual similarity between these tasks has promoted the use of multi-task learning: a class of algorithms that aim to bring positive inductive transfer from related tasks. Here, we empirically evaluate multi-task learning approaches with neural networks for an online advertising task. Specifically, we consider approximating the probability of post-click conversion events (installs) (CVR) for mobile app advertising on a large-scale advertising platform, using the related click events (CTR) as an auxiliary task. We use an ablation approach to systematically study recent approaches that incorporate both multitask learning and "entire space modeling" which train the CVR on all logged examples rather than learning a conditional likelihood of conversion given clicked. Based on these results we show that several different approaches result in similar levels of positive transfer from the data-abundant CTR task to the CVR task and offer some insight into how the multi-task design choices address the two primary problems affecting the CVR task: data sparsity and data bias. Our findings add to the growing body of evidence suggesting that standard multi-task learning is a sensible approach to modelling related events in real-world large-scale applications and suggest the specific multitask approach can be guided by ease of implementation in an existing system.
Entropic Policy Composition with Generalized Policy Improvement and Divergence Correction
Dec 05, 2018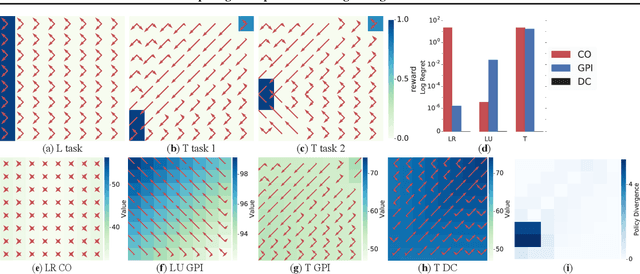



Deep reinforcement learning (RL) algorithms have made great strides in recent years. An important remaining challenge is the ability to quickly transfer existing skills to novel tasks, and to combine existing skills with newly acquired ones. In domains where tasks are solved by composing skills this capacity holds the promise of dramatically reducing the data requirements of deep RL algorithms, and hence increasing their applicability. Recent work has studied ways of composing behaviors represented in the form of action-value functions. We analyze these methods to highlight their strengths and weaknesses, and point out situations where each of them is susceptible to poor performance. To perform this analysis we extend generalized policy improvement to the max-entropy framework and introduce a method for the practical implementation of successor features in continuous action spaces. Then we propose a novel approach which, in principle, recovers the optimal policy during transfer. This method works by explicitly learning the (discounted, future) divergence between policies. We study this approach in the tabular case and propose a scalable variant that is applicable in multi-dimensional continuous action spaces. We compare our approach with existing ones on a range of non-trivial continuous control problems with compositional structure, and demonstrate qualitatively better performance despite not requiring simultaneous observation of all task rewards.
Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes
Oct 27, 2016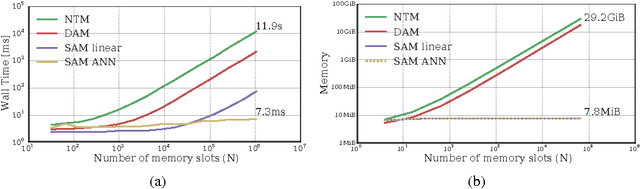
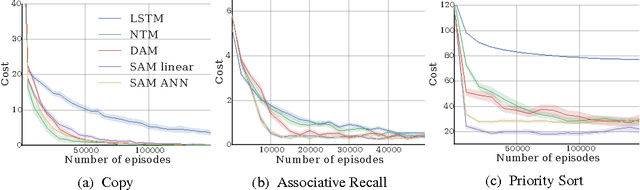
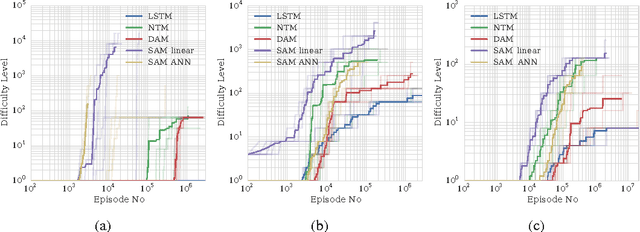
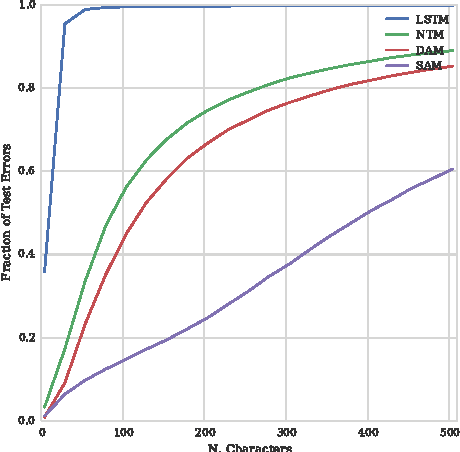
Neural networks augmented with external memory have the ability to learn algorithmic solutions to complex tasks. These models appear promising for applications such as language modeling and machine translation. However, they scale poorly in both space and time as the amount of memory grows --- limiting their applicability to real-world domains. Here, we present an end-to-end differentiable memory access scheme, which we call Sparse Access Memory (SAM), that retains the representational power of the original approaches whilst training efficiently with very large memories. We show that SAM achieves asymptotic lower bounds in space and time complexity, and find that an implementation runs $1,\!000\times$ faster and with $3,\!000\times$ less physical memory than non-sparse models. SAM learns with comparable data efficiency to existing models on a range of synthetic tasks and one-shot Omniglot character recognition, and can scale to tasks requiring $100,\!000$s of time steps and memories. As well, we show how our approach can be adapted for models that maintain temporal associations between memories, as with the recently introduced Differentiable Neural Computer.