 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and approaches to privacy preserving post-click conversion prediction
Jan 29, 2022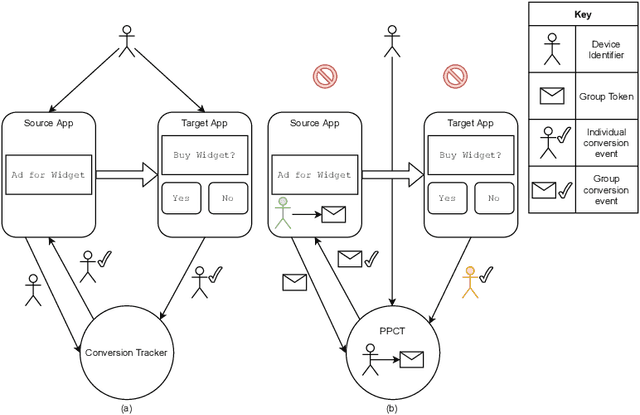
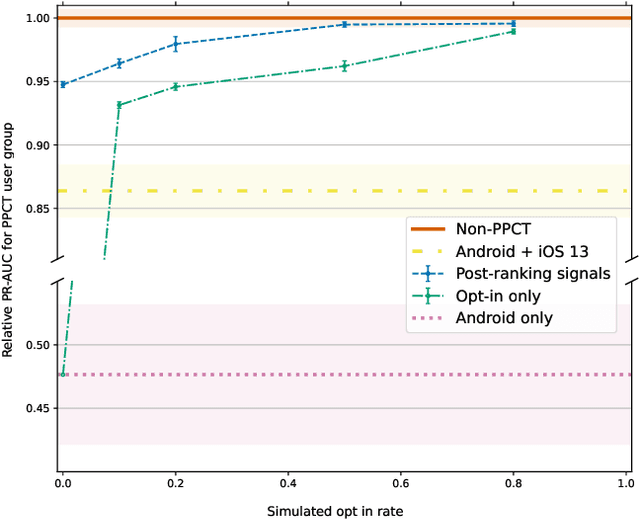
Online advertising has typically been more personalized than offline advertising, through the use of machine learning models and real-time auctions for ad targeting. One specific task, predicting the likelihood of conversion (i.e.\ the probability a user will purchase the advertised product), is crucial to the advertising ecosystem for both targeting and pricing ads. Currently, these models are often trained by observing individual user behavior, but, increasingly, regulatory and technical constraints are requiring privacy-preserving approaches. For example, major platforms are moving to restrict tracking individual user events across multiple applications, and governments around the world have shown steadily more interest in regulating the use of personal data. Instead of receiving data about individual user behavior, advertisers may receive privacy-preserving feedback, such as the number of installs of an advertised app that resulted from a group of users. In this paper we outline the recent privacy-related changes in the online advertising ecosystem from a machine learning perspective. We provide an overview of the challenges and constraints when learning conversion models in this setting. We introduce a novel approach for training these models that makes use of post-ranking signals. We show using offline experiments on real world data that it outperforms a model relying on opt-in data alone, and significantly reduces model degradation when no individual labels are available. Finally, we discuss future directions for research in this evolving area.
An Analysis Of Entire Space Multi-Task Models For Post-Click Conversion Prediction
Aug 18, 2021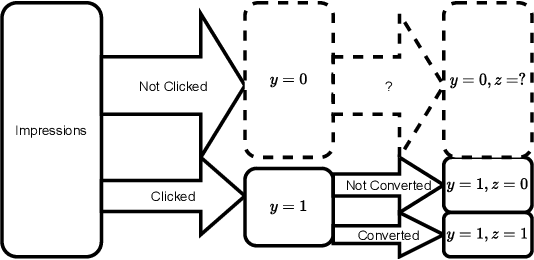
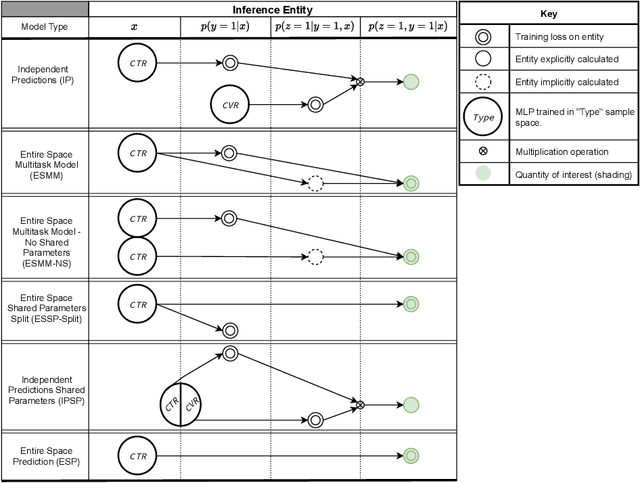
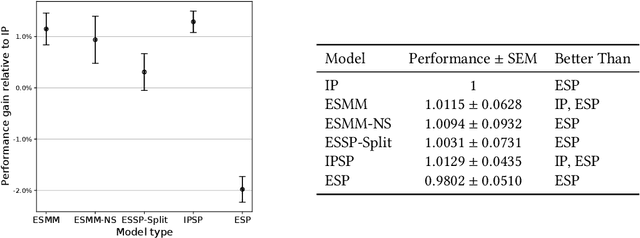
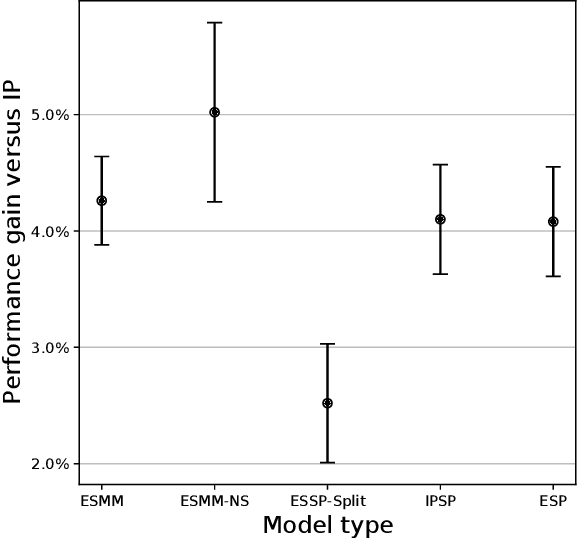
Industrial recommender systems are frequently tasked with approximating probabilities for multiple, often closely related, user actions. For example, predicting if a user will click on an advertisement and if they will then purchase the advertised product. The conceptual similarity between these tasks has promoted the use of multi-task learning: a class of algorithms that aim to bring positive inductive transfer from related tasks. Here, we empirically evaluate multi-task learning approaches with neural networks for an online advertising task. Specifically, we consider approximating the probability of post-click conversion events (installs) (CVR) for mobile app advertising on a large-scale advertising platform, using the related click events (CTR) as an auxiliary task. We use an ablation approach to systematically study recent approaches that incorporate both multitask learning and "entire space modeling" which train the CVR on all logged examples rather than learning a conditional likelihood of conversion given clicked. Based on these results we show that several different approaches result in similar levels of positive transfer from the data-abundant CTR task to the CVR task and offer some insight into how the multi-task design choices address the two primary problems affecting the CVR task: data sparsity and data bias. Our findings add to the growing body of evidence suggesting that standard multi-task learning is a sensible approach to modelling related events in real-world large-scale applications and suggest the specific multitask approach can be guided by ease of implementation in an existing system.