 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Knowledge for Short-to-Long Term Trajectory Prediction
May 15, 2023



Long-term trajectory forecasting is a challenging problem in the field of computer vision and machine learning. In this paper, we propose a new method dubbed Di-Long ("Distillation for Long-Term trajectory") for long-term trajectory forecasting, which is based on knowledge distillation. Our approach involves training a student network to solve the long-term trajectory forecasting problem, whereas the teacher network from which the knowledge is distilled has a longer observation, and solves a short-term trajectory prediction problem by regularizing the student's predictions. Specifically, we use a teacher model to generate plausible trajectories for a shorter time horizon, and then distill the knowledge from the teacher model to a student model that solves the problem for a much higher time horizon. Our experiments show that the proposed Di-Long approach is beneficial for long-term forecasting, and our model achieves state-of-the-art performance on the Intersection Drone Dataset (inD) and the Stanford Drone Dataset (SDD).
Monitoring the risk of a tailings dam collapse through spectral analysis of satellite InSAR time-series data
Feb 03, 2023Slope failures possess destructive power that can cause significant damage to both life and infrastructure. Monitoring slopes prone to instabilities is therefore critical in mitigating the risk posed by their failure. The purpose of slope monitoring is to detect precursory signs of stability issues, such as changes in the rate of displacement with which a slope is deforming. This information can then be used to predict the timing or probability of an imminent failure in order to provide an early warning. In this study, a more objective, statistical-learning algorithm is proposed to detect and characterise the risk of a slope failure, based on spectral analysis of serially correlated displacement time series data. The algorithm is applied to satellite-based interferometric synthetic radar (InSAR) displacement time series data to retrospectively analyse the risk of the 2019 Brumadinho tailings dam collapse in Brazil. Two potential risk milestones are identified and signs of a definitive but emergent risk (27 February 2018 to 26 August 2018) and imminent risk of collapse of the tailings dam (27 June 2018 to 24 December 2018) are detected by the algorithm. Importantly, this precursory indication of risk of failure is detected as early as at least five months prior to the dam collapse on 25 January 2019. The results of this study demonstrate that the combination of spectral methods and second order statistical properties of InSAR displacement time series data can reveal signs of a transition into an unstable deformation regime, and that this algorithm can provide sufficient early warning that could help mitigate catastrophic slope failures.
Goal-driven Self-Attentive Recurrent Networks for Trajectory Prediction
Apr 25, 2022



Human trajectory forecasting is a key component of autonomous vehicles, social-aware robots and advanced video-surveillance applications. This challenging task typically requires knowledge about past motion, the environment and likely destination areas. In this context, multi-modality is a fundamental aspect and its effective modeling can be beneficial to any architecture. Inferring accurate trajectories is nevertheless challenging, due to the inherently uncertain nature of the future. To overcome these difficulties, recent models use different inputs and propose to model human intentions using complex fusion mechanisms. In this respect, we propose a lightweight attention-based recurrent backbone that acts solely on past observed positions. Although this backbone already provides promising results, we demonstrate that its prediction accuracy can be improved considerably when combined with a scene-aware goal-estimation module. To this end, we employ a common goal module, based on a U-Net architecture, which additionally extracts semantic information to predict scene-compliant destinations. We conduct extensive experiments on publicly-available datasets (i.e. SDD, inD, ETH/UCY) and show that our approach performs on par with state-of-the-art techniques while reducing model complexity.
State-of-the-Art Review of Design of Experiments for Physics-Informed Deep Learning
Feb 13, 2022

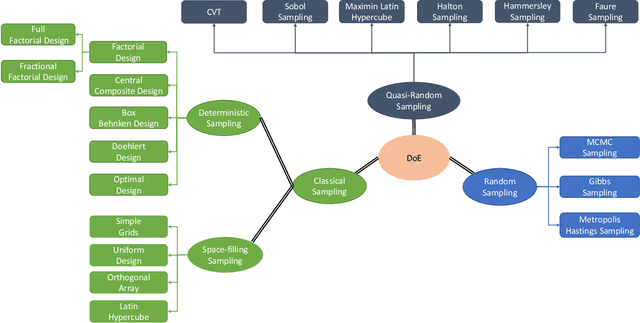
This paper presents a comprehensive review of the design of experiments used in the surrogate models. In particular, this study demonstrates the necessity of the design of experiment schemes for the Physics-Informed Neural Network (PINN), which belongs to the supervised learning class. Many complex partial differential equations (PDEs) do not have any analytical solution; only numerical methods are used to solve the equations, which is computationally expensive. In recent decades, PINN has gained popularity as a replacement for numerical methods to reduce the computational budget. PINN uses physical information in the form of differential equations to enhance the performance of the neural networks. Though it works efficiently, the choice of the design of experiment scheme is important as the accuracy of the predicted responses using PINN depends on the training data. In this study, five different PDEs are used for numerical purposes, i.e., viscous Burger's equation, Shr\"{o}dinger equation, heat equation, Allen-Cahn equation, and Korteweg-de Vries equation. A comparative study is performed to establish the necessity of the selection of a DoE scheme. It is seen that the Hammersley sampling-based PINN performs better than other DoE sample strategies.
Challenges and approaches to privacy preserving post-click conversion prediction
Jan 29, 2022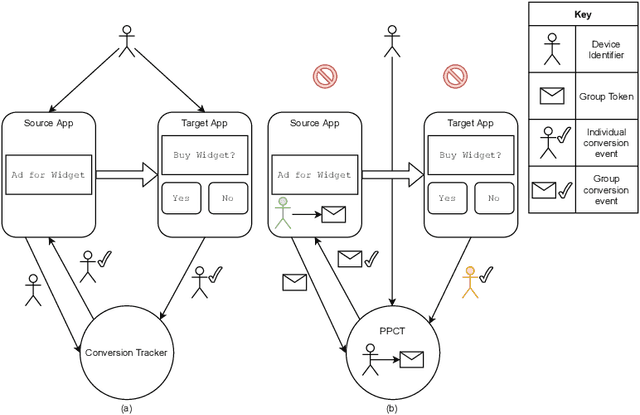
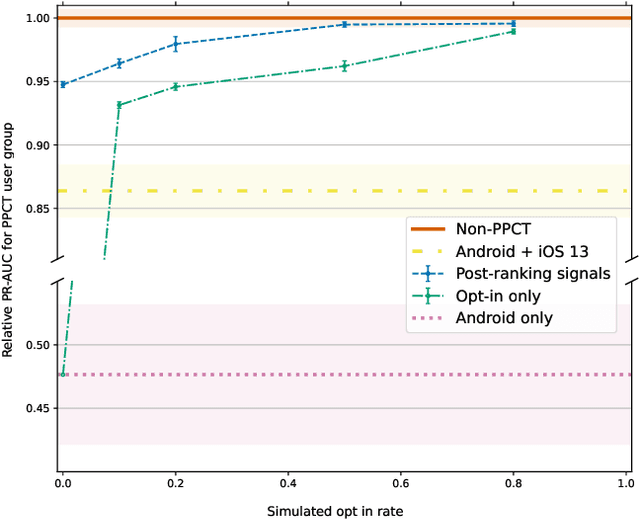
Online advertising has typically been more personalized than offline advertising, through the use of machine learning models and real-time auctions for ad targeting. One specific task, predicting the likelihood of conversion (i.e.\ the probability a user will purchase the advertised product), is crucial to the advertising ecosystem for both targeting and pricing ads. Currently, these models are often trained by observing individual user behavior, but, increasingly, regulatory and technical constraints are requiring privacy-preserving approaches. For example, major platforms are moving to restrict tracking individual user events across multiple applications, and governments around the world have shown steadily more interest in regulating the use of personal data. Instead of receiving data about individual user behavior, advertisers may receive privacy-preserving feedback, such as the number of installs of an advertised app that resulted from a group of users. In this paper we outline the recent privacy-related changes in the online advertising ecosystem from a machine learning perspective. We provide an overview of the challenges and constraints when learning conversion models in this setting. We introduce a novel approach for training these models that makes use of post-ranking signals. We show using offline experiments on real world data that it outperforms a model relying on opt-in data alone, and significantly reduces model degradation when no individual labels are available. Finally, we discuss future directions for research in this evolving area.
Probabilistic Impact Score Generation using Ktrain-BERT to Identify Hate Words from Twitter Discussions
Nov 25, 2021



Social media has seen a worrying rise in hate speech in recent times. Branching to several distinct categories of cyberbullying, gender discrimination, or racism, the combined label for such derogatory content can be classified as toxic content in general. This paper presents experimentation with a Keras wrapped lightweight BERT model to successfully identify hate speech and predict probabilistic impact score for the same to extract the hateful words within sentences. The dataset used for this task is the Hate Speech and Offensive Content Detection (HASOC 2021) data from FIRE 2021 in English. Our system obtained a validation accuracy of 82.60%, with a maximum F1-Score of 82.68%. Subsequently, our predictive cases performed significantly well in generating impact scores for successful identification of the hate tweets as well as the hateful words from tweet pools.
PAC Mode Estimation using PPR Martingale Confidence Sequences
Sep 10, 2021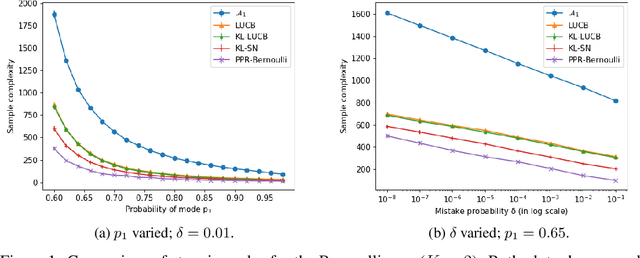
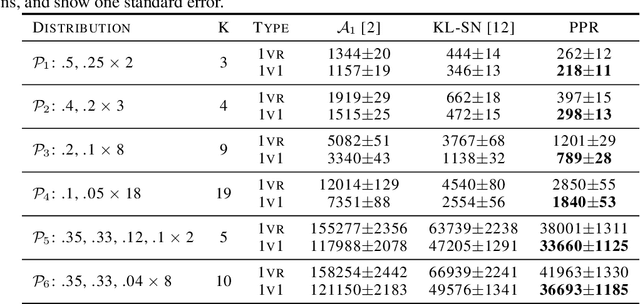
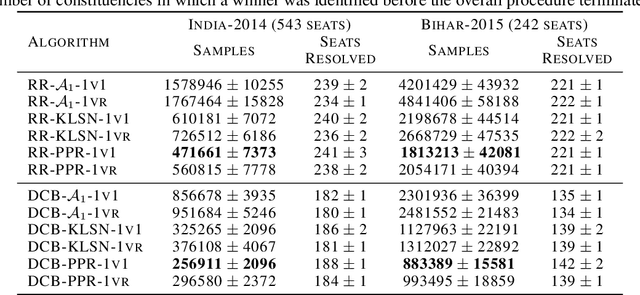
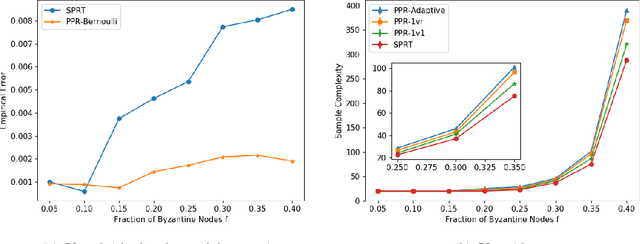
We consider the problem of correctly identifying the mode of a discrete distribution $\mathcal{P}$ with sufficiently high probability by observing a sequence of i.i.d. samples drawn according to $\mathcal{P}$. This problem reduces to the estimation of a single parameter when $\mathcal{P}$ has a support set of size $K = 2$. Noting the efficiency of prior-posterior-ratio (PPR) martingale confidence sequences for handling this special case, we propose a generalisation to mode estimation, in which $\mathcal{P}$ may take $K \geq 2$ values. We observe that the "one-versus-one" principle yields a more efficient generalisation than the "one-versus-rest" alternative. Our resulting stopping rule, denoted PPR-ME, is optimal in its sample complexity up to a logarithmic factor. Moreover, PPR-ME empirically outperforms several other competing approaches for mode estimation. We demonstrate the gains offered by PPR-ME in two practical applications: (1) sample-based forecasting of the winner in indirect election systems, and (2) efficient verification of smart contracts in permissionless blockchains.
Sentiment Analysis of Covid-19 Tweets using Evolutionary Classification-Based LSTM Model
Jun 13, 2021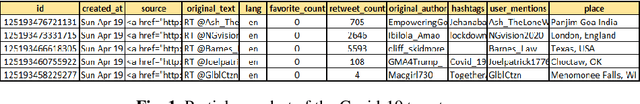



As the Covid-19 outbreaks rapidly all over the world day by day and also affects the lives of million, a number of countries declared complete lock-down to check its intensity. During this lockdown period, social media plat-forms have played an important role to spread information about this pandemic across the world, as people used to express their feelings through the social networks. Considering this catastrophic situation, we developed an experimental approach to analyze the reactions of people on Twitter taking into ac-count the popular words either directly or indirectly based on this pandemic. This paper represents the sentiment analysis on collected large number of tweets on Coronavirus or Covid-19. At first, we analyze the trend of public sentiment on the topics related to Covid-19 epidemic using an evolutionary classification followed by the n-gram analysis. Then we calculated the sentiment ratings on collected tweet based on their class. Finally, we trained the long-short term network using two types of rated tweets to predict sentiment on Covid-19 data and obtained an overall accuracy of 84.46%.
* 11 pages, 8 figures, 5 tables
Parallel Deep Learning-Driven Sarcasm Detection from Pop Culture Text and English Humor Literature
Jun 10, 2021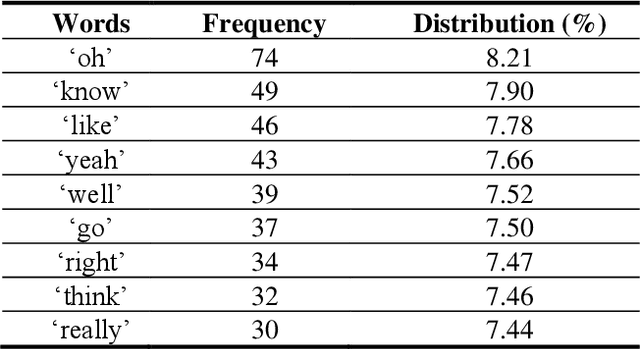
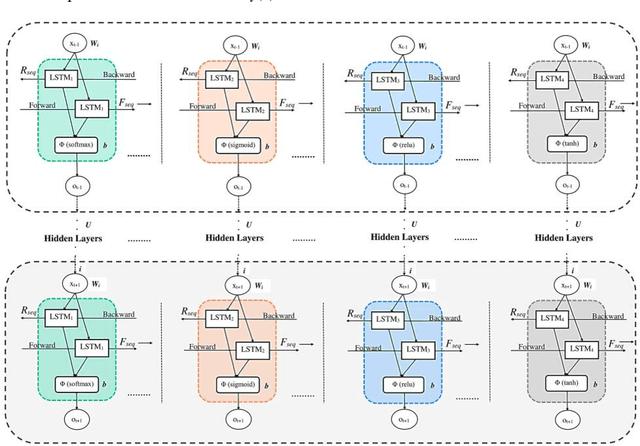
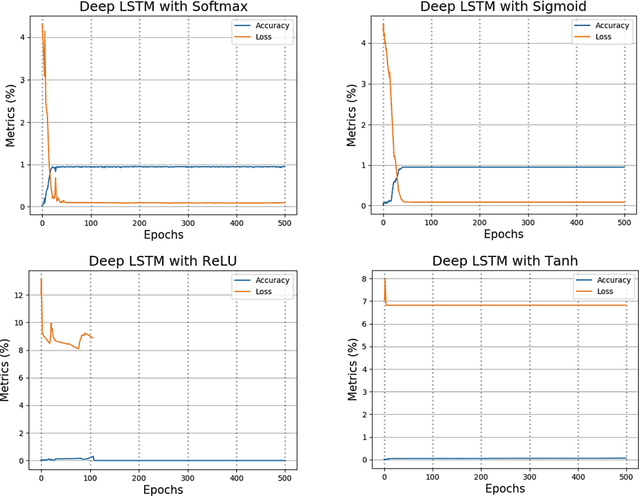
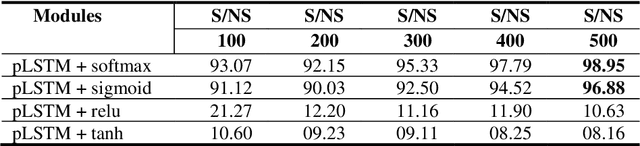
Sarcasm is a sophisticated way of wrapping any immanent truth, mes-sage, or even mockery within a hilarious manner. The advent of communications using social networks has mass-produced new avenues of socialization. It can be further said that humor, irony, sarcasm, and wit are the four chariots of being socially funny in the modern days. In this paper, we manually extract the sarcastic word distribution features of a benchmark pop culture sarcasm corpus, containing sarcastic dialogues and monologues. We generate input sequences formed of the weighted vectors from such words. We further propose an amalgamation of four parallel deep long-short term networks (pLSTM), each with distinctive activation classifier. These modules are primarily aimed at successfully detecting sarcasm from the text corpus. Our proposed model for detecting sarcasm peaks a training accuracy of 98.95% when trained with the discussed dataset. Consecutively, it obtains the highest of 98.31% overall validation accuracy on two handpicked Project Gutenberg English humor literature among all the test cases. Our approach transcends previous state-of-the-art works on several sarcasm corpora and results in a new gold standard performance for sarcasm detection.
* 10 pages, 2 figures, 4 tables
Detecting Generic Music Features with Single Layer Feedforward Network using Unsupervised Hebbian Computation
Aug 31, 2020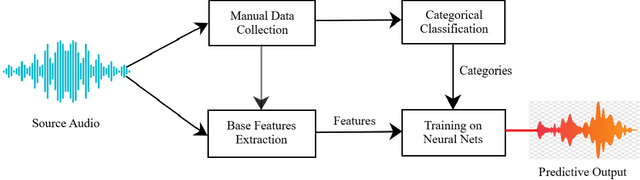


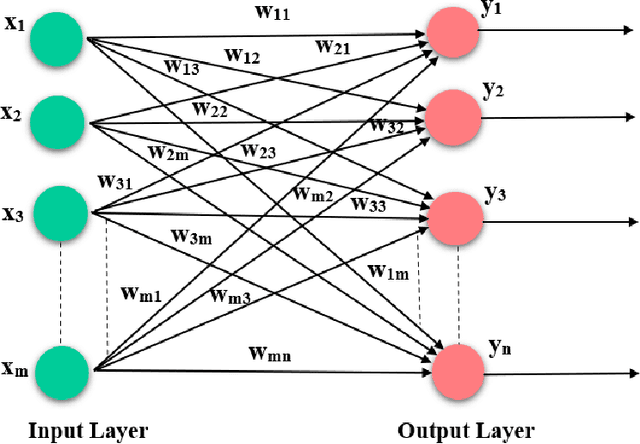
With the ever-increasing number of digital music and vast music track features through popular online music streaming software and apps, feature recognition using the neural network is being used for experimentation to produce a wide range of results across a variety of experiments recently. Through this work, the authors extract information on such features from a popular open-source music corpus and explored new recognition techniques, by applying unsupervised Hebbian learning techniques on their single-layer neural network using the same dataset. The authors show the detailed empirical findings to simulate how such an algorithm can help a single layer feedforward network in training for music feature learning as patterns. The unsupervised training algorithm enhances their proposed neural network to achieve an accuracy of 90.36% for successful music feature detection. For comparative analysis against similar tasks, authors put their results with the likes of several previous benchmark works. They further discuss the limitations and thorough error analysis of their work. The authors hope to discover and gather new information about this particular classification technique and its performance, and further understand future potential directions and prospects that could improve the art of computational music feature recognition.