 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Action Recognition with Action Prototypes
Dec 11, 2023



Early action recognition is an important and challenging problem that enables the recognition of an action from a partially observed video stream where the activity is potentially unfinished or even not started. In this work, we propose a novel model that learns a prototypical representation of the full action for each class and uses it to regularize the architecture and the visual representations of the partial observations. Our model is very simple in design and also efficient. We decompose the video into short clips, where a visual encoder extracts features from each clip independently. Later, a decoder aggregates together in an online fashion features from all the clips for the final class prediction. During training, for each partial observation, the model is jointly trained to both predict the label as well as the action prototypical representation which acts as a regularizer. We evaluate our method on multiple challenging real-world datasets and outperform the current state-of-the-art by a significant margin. For example, on early recognition observing only the first 10% of each video, our method improves the SOTA by +2.23 Top-1 accuracy on Something-Something-v2, +3.55 on UCF-101, +3.68 on SSsub21, and +5.03 on EPIC-Kitchens-55, where prior work used either multi-modal inputs (e.g. optical-flow) or batched inference. Finally, we also present exhaustive ablation studies to motivate the design choices we made, as well as gather insights regarding what our model is learning semantically.
Distilling Knowledge for Short-to-Long Term Trajectory Prediction
May 15, 2023



Long-term trajectory forecasting is a challenging problem in the field of computer vision and machine learning. In this paper, we propose a new method dubbed Di-Long ("Distillation for Long-Term trajectory") for long-term trajectory forecasting, which is based on knowledge distillation. Our approach involves training a student network to solve the long-term trajectory forecasting problem, whereas the teacher network from which the knowledge is distilled has a longer observation, and solves a short-term trajectory prediction problem by regularizing the student's predictions. Specifically, we use a teacher model to generate plausible trajectories for a shorter time horizon, and then distill the knowledge from the teacher model to a student model that solves the problem for a much higher time horizon. Our experiments show that the proposed Di-Long approach is beneficial for long-term forecasting, and our model achieves state-of-the-art performance on the Intersection Drone Dataset (inD) and the Stanford Drone Dataset (SDD).
TAMFormer: Multi-Modal Transformer with Learned Attention Mask for Early Intent Prediction
Oct 26, 2022Human intention prediction is a growing area of research where an activity in a video has to be anticipated by a vision-based system. To this end, the model creates a representation of the past, and subsequently, it produces future hypotheses about upcoming scenarios. In this work, we focus on pedestrians' early intention prediction in which, from a current observation of an urban scene, the model predicts the future activity of pedestrians that approach the street. Our method is based on a multi-modal transformer that encodes past observations and produces multiple predictions at different anticipation times. Moreover, we propose to learn the attention masks of our transformer-based model (Temporal Adaptive Mask Transformer) in order to weigh differently present and past temporal dependencies. We investigate our method on several public benchmarks for early intention prediction, improving the prediction performances at different anticipation times compared to the previous works.
Where are my Neighbors? Exploiting Patches Relations in Self-Supervised Vision Transformer
Jun 01, 2022
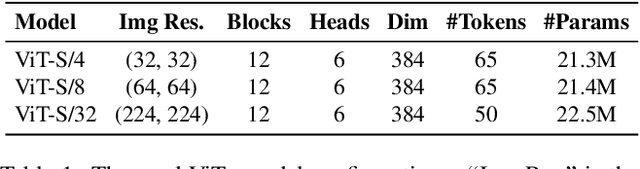


Vision Transformers (ViTs) enabled the use of transformer architecture on vision tasks showing impressive performances when trained on big datasets. However, on relatively small datasets, ViTs are less accurate given their lack of inductive bias. To this end, we propose a simple but still effective self-supervised learning (SSL) strategy to train ViTs, that without any external annotation, can significantly improve the results. Specifically, we define a set of SSL tasks based on relations of image patches that the model has to solve before or jointly during the downstream training. Differently from ViT, our RelViT model optimizes all the output tokens of the transformer encoder that are related to the image patches, thus exploiting more training signal at each training step. We investigated our proposed methods on several image benchmarks finding that RelViT improves the SSL state-of-the-art methods by a large margin, especially on small datasets.
SlowFast Rolling-Unrolling LSTMs for Action Anticipation in Egocentric Videos
Sep 02, 2021

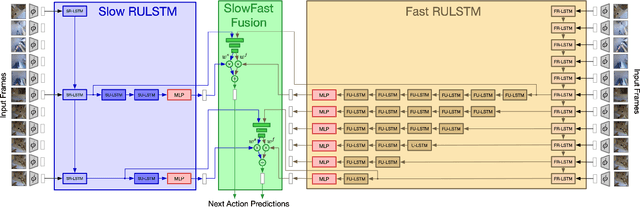

Action anticipation in egocentric videos is a difficult task due to the inherently multi-modal nature of human actions. Additionally, some actions happen faster or slower than others depending on the actor or surrounding context which could vary each time and lead to different predictions. Based on this idea, we build upon RULSTM architecture, which is specifically designed for anticipating human actions, and propose a novel attention-based technique to evaluate, simultaneously, slow and fast features extracted from three different modalities, namely RGB, optical flow, and extracted objects. Two branches process information at different time scales, i.e., frame-rates, and several fusion schemes are considered to improve prediction accuracy. We perform extensive experiments on EpicKitchens-55 and EGTEA Gaze+ datasets, and demonstrate that our technique systematically improves the results of RULSTM architecture for Top-5 accuracy metric at different anticipation times.
Conditional Variational Capsule Network for Open Set Recognition
Apr 19, 2021
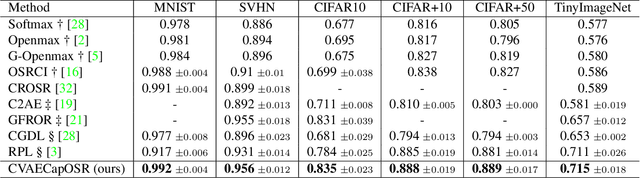
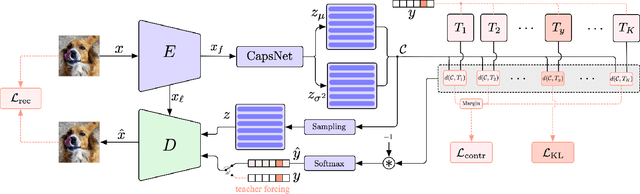

In open set recognition, a classifier has to detect unknown classes that are not known at training time. In order to recognize new classes, the classifier has to project the input samples of known classes in very compact and separated regions of the features space in order to discriminate outlier samples of unknown classes. Recently proposed Capsule Networks have shown to outperform alternatives in many fields, particularly in image recognition, however they have not been fully applied yet to open-set recognition. In capsule networks, scalar neurons are replaced by capsule vectors or matrices, whose entries represent different properties of objects. In our proposal, during training, capsules features of the same known class are encouraged to match a pre-defined gaussian, one for each class. To this end, we use the variational autoencoder framework, with a set of gaussian prior as the approximation for the posterior distribution. In this way, we are able to control the compactness of the features of the same class around the center of the gaussians, thus controlling the ability of the classifier in detecting samples from unknown classes. We conducted several experiments and ablation of our model, obtaining state of the art results on different datasets in the open set recognition and unknown detection tasks.
Improved Robustness to Disfluencies in RNN-Transducer Based Speech Recognition
Dec 11, 2020



Automatic Speech Recognition (ASR) based on Recurrent Neural Network Transducers (RNN-T) is gaining interest in the speech community. We investigate data selection and preparation choices aiming for improved robustness of RNN-T ASR to speech disfluencies with a focus on partial words. For evaluation we use clean data, data with disfluencies and a separate dataset with speech affected by stuttering. We show that after including a small amount of data with disfluencies in the training set the recognition accuracy on the tests with disfluencies and stuttering improves. Increasing the amount of training data with disfluencies gives additional gains without degradation on the clean data. We also show that replacing partial words with a dedicated token helps to get even better accuracy on utterances with disfluencies and stutter. The evaluation of our best model shows 22.5% and 16.4% relative WER reduction on those two evaluation sets.
Knowledge Distillation for Action Anticipation via Label Smoothing
Apr 16, 2020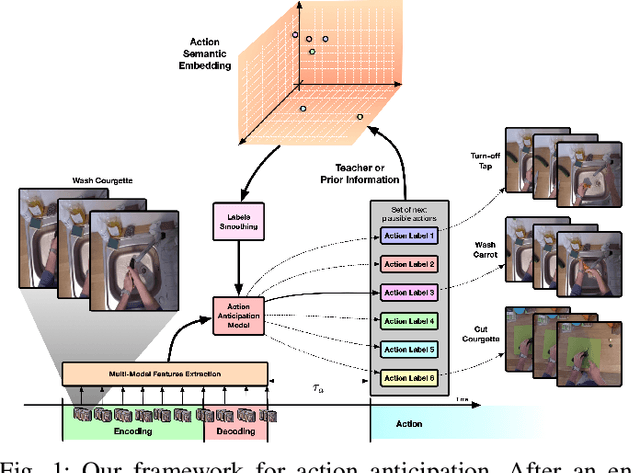

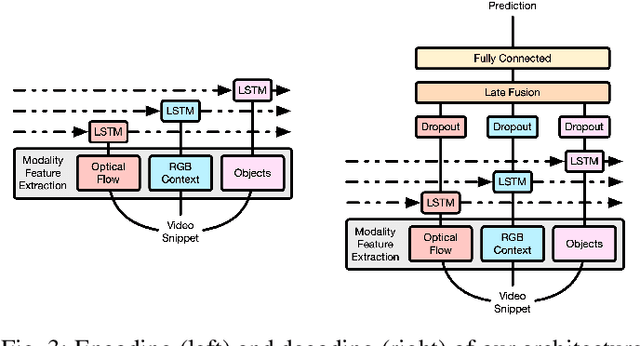

Human capability to anticipate near future from visual observations and non-verbal cues is essential for developing intelligent systems that need to interact with people. Several research areas, such as human-robot interaction (HRI), assisted living or autonomous driving need to foresee future events to avoid crashes or help visually impaired people. Such challenging task requires to capture and understand the underlying structure of the analyzed domain in order to reduce prediction uncertainty. Since the action anticipation task can be seen as a multi-label problem with missing labels, we design and extend the idea of label smoothing extracting semantics from the target labels. We show that such generalization is equivalent to considering a knowledge distillation framework where a teacher injects useful semantic information into the model during training. In our experiments, we implement a multi-modal framework based on long short-term memory (LSTM) networks to anticipate future actions which is able to summarise past observations while making predictions of the future at different time steps. To validate our soft labeling procedure we perform extensive experiments on the egocentric EPIC-Kitchens dataset which includes more than 2500 action classes. The experiments show that label smoothing systematically improves performance of state-of-the-art models.