 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Dirichlet Energies as Over-smoothing Measures
Dec 10, 2025We analyze the distinctions between two functionals often used as over-smoothing measures: the Dirichlet energies induced by the unnormalized graph Laplacian and the normalized graph Laplacian. We demonstrate that the latter fails to satisfy the axiomatic definition of a node-similarity measure proposed by Rusch \textit{et al.} By formalizing fundamental spectral properties of these two definitions, we highlight critical distinctions necessary to select the metric that is spectrally compatible with the GNN architecture, thereby resolving ambiguities in monitoring the dynamics.
Unveiling the Actual Performance of Neural-based Models for Equation Discovery on Graph Dynamical Systems
Aug 25, 2025The ``black-box'' nature of deep learning models presents a significant barrier to their adoption for scientific discovery, where interpretability is paramount. This challenge is especially pronounced in discovering the governing equations of dynamical processes on networks or graphs, since even their topological structure further affects the processes' behavior. This paper provides a rigorous, comparative assessment of state-of-the-art symbolic regression techniques for this task. We evaluate established methods, including sparse regression and MLP-based architectures, and introduce a novel adaptation of Kolmogorov-Arnold Networks (KANs) for graphs, designed to exploit their inherent interpretability. Across a suite of synthetic and real-world dynamical systems, our results demonstrate that both MLP and KAN-based architectures can successfully identify the underlying symbolic equations, significantly surpassing existing baselines. Critically, we show that KANs achieve this performance with greater parsimony and transparency, as their learnable activation functions provide a clearer mapping to the true physical dynamics. This study offers a practical guide for researchers, clarifying the trade-offs between model expressivity and interpretability, and establishes the viability of neural-based architectures for robust scientific discovery on complex systems.
A Spectral Interpretation of Redundancy in a Graph Reservoir
Jul 17, 2025Reservoir computing has been successfully applied to graphs as a preprocessing method to improve the training efficiency of Graph Neural Networks (GNNs). However, a common issue that arises when repeatedly applying layer operators on graphs is over-smoothing, which consists in the convergence of graph signals toward low-frequency components of the graph Laplacian. This work revisits the definition of the reservoir in the Multiresolution Reservoir Graph Neural Network (MRGNN), a spectral reservoir model, and proposes a variant based on a Fairing algorithm originally introduced in the field of surface design in computer graphics. This algorithm provides a pass-band spectral filter that allows smoothing without shrinkage, and it can be adapted to the graph setting through the Laplacian operator. Given its spectral formulation, this method naturally connects to GNN architectures for tasks where smoothing, when properly controlled, can be beneficial,such as graph classification. The core contribution of the paper lies in the theoretical analysis of the algorithm from a random walks perspective. In particular, it shows how tuning the spectral coefficients can be interpreted as modulating the contribution of redundant random walks. Exploratory experiments based on the MRGNN architecture illustrate the potential of this approach and suggest promising directions for future research.
LLMs as Data Annotators: How Close Are We to Human Performance
Apr 21, 2025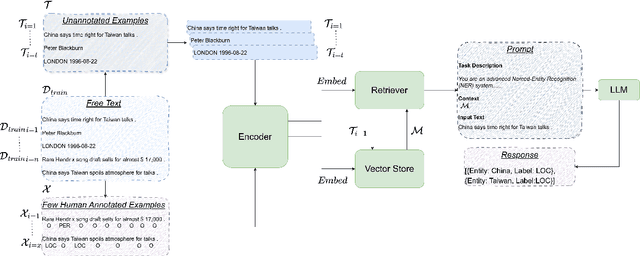
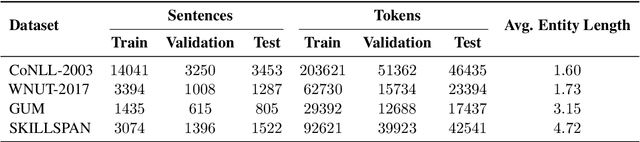
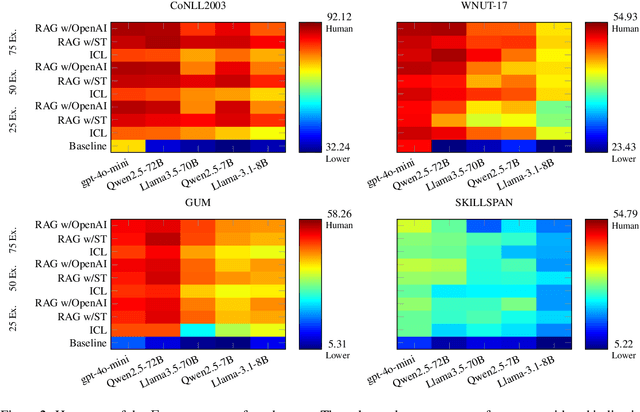
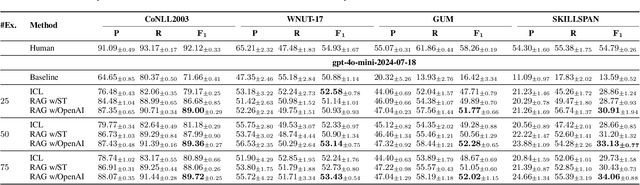
In NLP, fine-tuning LLMs is effective for various applications but requires high-quality annotated data. However, manual annotation of data is labor-intensive, time-consuming, and costly. Therefore, LLMs are increasingly used to automate the process, often employing in-context learning (ICL) in which some examples related to the task are given in the prompt for better performance. However, manually selecting context examples can lead to inefficiencies and suboptimal model performance. This paper presents comprehensive experiments comparing several LLMs, considering different embedding models, across various datasets for the Named Entity Recognition (NER) task. The evaluation encompasses models with approximately $7$B and $70$B parameters, including both proprietary and non-proprietary models. Furthermore, leveraging the success of Retrieval-Augmented Generation (RAG), it also considers a method that addresses the limitations of ICL by automatically retrieving contextual examples, thereby enhancing performance. The results highlight the importance of selecting the appropriate LLM and embedding model, understanding the trade-offs between LLM sizes and desired performance, and the necessity to direct research efforts towards more challenging datasets.
Exact Computation of Any-Order Shapley Interactions for Graph Neural Networks
Jan 28, 2025Albeit the ubiquitous use of Graph Neural Networks (GNNs) in machine learning (ML) prediction tasks involving graph-structured data, their interpretability remains challenging. In explainable artificial intelligence (XAI), the Shapley Value (SV) is the predominant method to quantify contributions of individual features to a ML model's output. Addressing the limitations of SVs in complex prediction models, Shapley Interactions (SIs) extend the SV to groups of features. In this work, we explain single graph predictions of GNNs with SIs that quantify node contributions and interactions among multiple nodes. By exploiting the GNN architecture, we show that the structure of interactions in node embeddings are preserved for graph prediction. As a result, the exponential complexity of SIs depends only on the receptive fields, i.e. the message-passing ranges determined by the connectivity of the graph and the number of convolutional layers. Based on our theoretical results, we introduce GraphSHAP-IQ, an efficient approach to compute any-order SIs exactly. GraphSHAP-IQ is applicable to popular message passing techniques in conjunction with a linear global pooling and output layer. We showcase that GraphSHAP-IQ substantially reduces the exponential complexity of computing exact SIs on multiple benchmark datasets. Beyond exact computation, we evaluate GraphSHAP-IQ's approximation of SIs on popular GNN architectures and compare with existing baselines. Lastly, we visualize SIs of real-world water distribution networks and molecule structures using a SI-Graph.
IFH: a Diffusion Framework for Flexible Design of Graph Generative Models
Aug 23, 2024Graph generative models can be classified into two prominent families: one-shot models, which generate a graph in one go, and sequential models, which generate a graph by successive additions of nodes and edges. Ideally, between these two extreme models lies a continuous range of models that adopt different levels of sequentiality. This paper proposes a graph generative model, called Insert-Fill-Halt (IFH), that supports the specification of a sequentiality degree. IFH is based upon the theory of Denoising Diffusion Probabilistic Models (DDPM), designing a node removal process that gradually destroys a graph. An insertion process learns to reverse this removal process by inserting arcs and nodes according to the specified sequentiality degree. We evaluate the performance of IFH in terms of quality, run time, and memory, depending on different sequentiality degrees. We also show that using DiGress, a diffusion-based one-shot model, as a generative step in IFH leads to improvement to the model itself, and is competitive with the current state-of-the-art.
Assessing the Emergent Symbolic Reasoning Abilities of Llama Large Language Models
Jun 05, 2024


Large Language Models (LLMs) achieve impressive performance in a wide range of tasks, even if they are often trained with the only objective of chatting fluently with users. Among other skills, LLMs show emergent abilities in mathematical reasoning benchmarks, which can be elicited with appropriate prompting methods. In this work, we systematically investigate the capabilities and limitations of popular open-source LLMs on different symbolic reasoning tasks. We evaluate three models of the Llama 2 family on two datasets that require solving mathematical formulas of varying degrees of difficulty. We test a generalist LLM (Llama 2 Chat) as well as two fine-tuned versions of Llama 2 (MAmmoTH and MetaMath) specifically designed to tackle mathematical problems. We observe that both increasing the scale of the model and fine-tuning it on relevant tasks lead to significant performance gains. Furthermore, using fine-grained evaluation measures, we find that such performance gains are mostly observed with mathematical formulas of low complexity, which nevertheless often remain challenging even for the largest fine-tuned models.
Benchmarking GPT-4 on Algorithmic Problems: A Systematic Evaluation of Prompting Strategies
Feb 27, 2024



Large Language Models (LLMs) have revolutionized the field of Natural Language Processing thanks to their ability to reuse knowledge acquired on massive text corpora on a wide variety of downstream tasks, with minimal (if any) tuning steps. At the same time, it has been repeatedly shown that LLMs lack systematic generalization, which allows to extrapolate the learned statistical regularities outside the training distribution. In this work, we offer a systematic benchmarking of GPT-4, one of the most advanced LLMs available, on three algorithmic tasks characterized by the possibility to control the problem difficulty with two parameters. We compare the performance of GPT-4 with that of its predecessor (GPT-3.5) and with a variant of the Transformer-Encoder architecture recently introduced to solve similar tasks, the Neural Data Router. We find that the deployment of advanced prompting techniques allows GPT-4 to reach superior accuracy on all tasks, demonstrating that state-of-the-art LLMs constitute a very strong baseline also in challenging tasks that require systematic generalization.
A Neural Rewriting System to Solve Algorithmic Problems
Feb 27, 2024



Modern neural network architectures still struggle to learn algorithmic procedures that require to systematically apply compositional rules to solve out-of-distribution problem instances. In this work, we propose an original approach to learn algorithmic tasks inspired by rewriting systems, a classic framework in symbolic artificial intelligence. We show that a rewriting system can be implemented as a neural architecture composed by specialized modules: the Selector identifies the target sub-expression to process, the Solver simplifies the sub-expression by computing the corresponding result, and the Combiner produces a new version of the original expression by replacing the sub-expression with the solution provided. We evaluate our model on three types of algorithmic tasks that require simplifying symbolic formulas involving lists, arithmetic, and algebraic expressions. We test the extrapolation capabilities of the proposed architecture using formulas involving a higher number of operands and nesting levels than those seen during training, and we benchmark its performance against the Neural Data Router, a recent model specialized for systematic generalization, and a state-of-the-art large language model (GPT-4) probed with advanced prompting strategies.
A Hybrid System for Systematic Generalization in Simple Arithmetic Problems
Jun 29, 2023Solving symbolic reasoning problems that require compositionality and systematicity is considered one of the key ingredients of human intelligence. However, symbolic reasoning is still a great challenge for deep learning models, which often cannot generalize the reasoning pattern to out-of-distribution test cases. In this work, we propose a hybrid system capable of solving arithmetic problems that require compositional and systematic reasoning over sequences of symbols. The model acquires such a skill by learning appropriate substitution rules, which are applied iteratively to the input string until the expression is completely resolved. We show that the proposed system can accurately solve nested arithmetical expressions even when trained only on a subset including the simplest cases, significantly outperforming both a sequence-to-sequence model trained end-to-end and a state-of-the-art large language model.