 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning under Noisy Temporal Self-Supervision for Colonoscopy Videos
May 12, 2026Learning robust representations of polyp tracklets is key to enabling multiple AI-assisted colonoscopy applications, from polyp characterization to automated reporting and retrieval. Supervised contrastive learning is an effective approach for learning such representations, but it typically relies on correct positive and negative definitions. Collecting these labels requires linking tracklets that depict the same underlying polyp entity throughout the video, which is costly and demands specialized clinical expertise. In this work, we leverage the sequential workflow of colonoscopy procedures to derive self-supervised associations from temporal structure. Since temporally derived associations are not guaranteed to be correct, we introduce a noise-aware contrastive loss to account for noisy associations. We demonstrate the effectiveness of the learned representations across multiple downstream tasks, including polyp retrieval and re-identification, size estimation, and histology classification. Our method outperforms prior self-supervised and supervised baselines, and matches or exceeds recent foundation models across all tasks, using a lightweight encoder trained on only 27 videos. Code is available at https://github.com/lparolari/ntssl.
Benchmarking Layout-Guided Diffusion Models through Unified Semantic-Spatial Evaluation in Closed and Open Settings
Apr 28, 2026Evaluating layout-guided text-to-image generative models requires assessing both semantic alignment with textual prompts and spatial fidelity to prescribed layouts. Assessing layout alignment requires collecting fine-grained annotations, which is costly and labor-intensive. Consequently, current benchmarks rarely provide comprehensive layout evaluation and often remain limited in scale or coverage, making model comparison, ranking, and interpretation difficult. In this work, we introduce a closed-set benchmark (C-Bench) designed to isolate key generative capabilities while providing varying levels of complexity in both prompt structure and layout. To complement this controlled setting, we propose an open-set benchmark (O-Bench) that evaluates models using real-world prompts and layouts, offering a measure of semantic and spatial alignment in the wild. We further develop a unified evaluation protocol that combines semantic and spatial accuracy into a single score, ensuring consistent model ranking. Using our benchmarks, we conduct a large-scale evaluation of six state-of-the-art layout-guided diffusion models, totaling 319,086 generated and evaluated images. We establish a model ranking based on their overall performance and provide detailed breakdowns for text and layout alignment to enhance interpretability. Fine-grained analyses across scenarios and prompt complexities highlight the strengths and limitations of current models. Code is available at https://github.com/lparolari/cobench.
Temporally-Aware Supervised Contrastive Learning for Polyp Counting in Colonoscopy
Jul 03, 2025
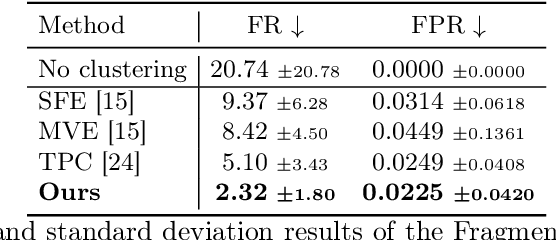


Automated polyp counting in colonoscopy is a crucial step toward automated procedure reporting and quality control, aiming to enhance the cost-effectiveness of colonoscopy screening. Counting polyps in a procedure involves detecting and tracking polyps, and then clustering tracklets that belong to the same polyp entity. Existing methods for polyp counting rely on self-supervised learning and primarily leverage visual appearance, neglecting temporal relationships in both tracklet feature learning and clustering stages. In this work, we introduce a paradigm shift by proposing a supervised contrastive loss that incorporates temporally-aware soft targets. Our approach captures intra-polyp variability while preserving inter-polyp discriminability, leading to more robust clustering. Additionally, we improve tracklet clustering by integrating a temporal adjacency constraint, reducing false positive re-associations between visually similar but temporally distant tracklets. We train and validate our method on publicly available datasets and evaluate its performance with a leave-one-out cross-validation strategy. Results demonstrate a 2.2x reduction in fragmentation rate compared to prior approaches. Our results highlight the importance of temporal awareness in polyp counting, establishing a new state-of-the-art. Code is available at https://github.com/lparolari/temporally-aware-polyp-counting.
Harlequin: Color-driven Generation of Synthetic Data for Referring Expression Comprehension
Nov 22, 2024Referring Expression Comprehension (REC) aims to identify a particular object in a scene by a natural language expression, and is an important topic in visual language understanding. State-of-the-art methods for this task are based on deep learning, which generally requires expensive and manually labeled annotations. Some works tackle the problem with limited-supervision learning or relying on Large Vision and Language Models. However, the development of techniques to synthesize labeled data is overlooked. In this paper, we propose a novel framework that generates artificial data for the REC task, taking into account both textual and visual modalities. At first, our pipeline processes existing data to create variations in the annotations. Then, it generates an image using altered annotations as guidance. The result of this pipeline is a new dataset, called Harlequin, made by more than 1M queries. This approach eliminates manual data collection and annotation, enabling scalability and facilitating arbitrary complexity. We pre-train three REC models on Harlequin, then fine-tuned and evaluated on human-annotated datasets. Our experiments show that the pre-training on artificial data is beneficial for performance.
Weakly-Supervised Visual-Textual Grounding with Semantic Prior Refinement
May 18, 2023

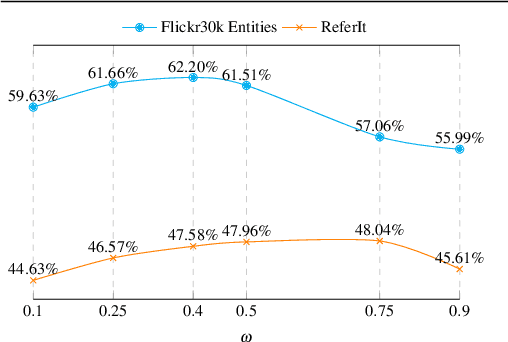

Using only image-sentence pairs, weakly-supervised visual-textual grounding aims to learn region-phrase correspondences of the respective entity mentions. Compared to the supervised approach, learning is more difficult since bounding boxes and textual phrases correspondences are unavailable. In light of this, we propose the Semantic Prior Refinement Model (SPRM), whose predictions are obtained by combining the output of two main modules. The first untrained module aims to return a rough alignment between textual phrases and bounding boxes. The second trained module is composed of two sub-components that refine the rough alignment to improve the accuracy of the final phrase-bounding box alignments. The model is trained to maximize the multimodal similarity between an image and a sentence, while minimizing the multimodal similarity of the same sentence and a new unrelated image, carefully selected to help the most during training. Our approach shows state-of-the-art results on two popular datasets, Flickr30k Entities and ReferIt, shining especially on ReferIt with a 9.6% absolute improvement. Moreover, thanks to the untrained component, it reaches competitive performances just using a small fraction of training examples.