 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Visual Enumeration Abilities of Specialized Counting Architectures and Vision-Language Models
Dec 17, 2025Counting the number of items in a visual scene remains a fundamental yet challenging task in computer vision. Traditional approaches to solving this problem rely on domain-specific counting architectures, which are trained using datasets annotated with a predefined set of object categories. However, recent progress in creating large-scale multimodal vision-language models (VLMs) suggests that these domain-general architectures may offer a flexible alternative for open-set object counting. In this study, we therefore systematically compare the performance of state-of-the-art specialized counting architectures against VLMs on two popular counting datasets, as well as on a novel benchmark specifically created to have a finer-grained control over the visual properties of test images. Our findings show that most VLMs can approximately enumerate the number of items in a visual scene, matching or even surpassing the performance of specialized computer vision architectures. Notably, enumeration accuracy significantly improves when VLMs are prompted to generate intermediate representations (i.e., locations and verbal labels) of each object to be counted. Nevertheless, none of the models can reliably count the number of objects in complex visual scenes, showing that further research is still needed to create AI systems that can reliably deploy counting procedures in realistic environments.
LangNavBench: Evaluation of Natural Language Understanding in Semantic Navigation
Jul 09, 2025Recent progress in large vision-language models has driven improvements in language-based semantic navigation, where an embodied agent must reach a target object described in natural language. Despite these advances, we still lack a clear, language-focused benchmark for testing how well such agents ground the words in their instructions. We address this gap with LangNav, an open-set dataset specifically created to test an agent's ability to locate objects described at different levels of detail, from broad category names to fine attributes and object-object relations. Every description in LangNav was manually checked, yielding a lower error rate than existing lifelong- and semantic-navigation datasets. On top of LangNav we build LangNavBench, a benchmark that measures how well current semantic-navigation methods understand and act on these descriptions while moving toward their targets. LangNavBench allows us to systematically compare models on their handling of attributes, spatial and relational cues, and category hierarchies, offering the first thorough, language-centric evaluation of embodied navigation systems. We also present Multi-Layered Feature Map (MLFM), a method that builds a queryable multi-layered semantic map, particularly effective when dealing with small objects or instructions involving spatial relations. MLFM outperforms state-of-the-art mapping-based navigation baselines on the LangNav dataset.
Temporally-Aware Supervised Contrastive Learning for Polyp Counting in Colonoscopy
Jul 03, 2025
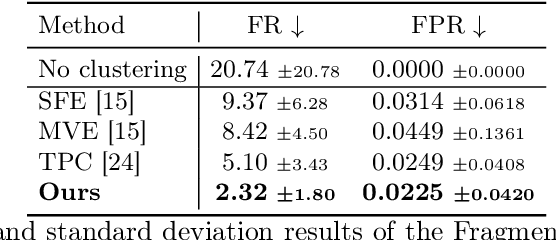


Automated polyp counting in colonoscopy is a crucial step toward automated procedure reporting and quality control, aiming to enhance the cost-effectiveness of colonoscopy screening. Counting polyps in a procedure involves detecting and tracking polyps, and then clustering tracklets that belong to the same polyp entity. Existing methods for polyp counting rely on self-supervised learning and primarily leverage visual appearance, neglecting temporal relationships in both tracklet feature learning and clustering stages. In this work, we introduce a paradigm shift by proposing a supervised contrastive loss that incorporates temporally-aware soft targets. Our approach captures intra-polyp variability while preserving inter-polyp discriminability, leading to more robust clustering. Additionally, we improve tracklet clustering by integrating a temporal adjacency constraint, reducing false positive re-associations between visually similar but temporally distant tracklets. We train and validate our method on publicly available datasets and evaluate its performance with a leave-one-out cross-validation strategy. Results demonstrate a 2.2x reduction in fragmentation rate compared to prior approaches. Our results highlight the importance of temporal awareness in polyp counting, establishing a new state-of-the-art. Code is available at https://github.com/lparolari/temporally-aware-polyp-counting.
Harlequin: Color-driven Generation of Synthetic Data for Referring Expression Comprehension
Nov 22, 2024Referring Expression Comprehension (REC) aims to identify a particular object in a scene by a natural language expression, and is an important topic in visual language understanding. State-of-the-art methods for this task are based on deep learning, which generally requires expensive and manually labeled annotations. Some works tackle the problem with limited-supervision learning or relying on Large Vision and Language Models. However, the development of techniques to synthesize labeled data is overlooked. In this paper, we propose a novel framework that generates artificial data for the REC task, taking into account both textual and visual modalities. At first, our pipeline processes existing data to create variations in the annotations. Then, it generates an image using altered annotations as guidance. The result of this pipeline is a new dataset, called Harlequin, made by more than 1M queries. This approach eliminates manual data collection and annotation, enabling scalability and facilitating arbitrary complexity. We pre-train three REC models on Harlequin, then fine-tuned and evaluated on human-annotated datasets. Our experiments show that the pre-training on artificial data is beneficial for performance.
FastSTI: A Fast Conditional Pseudo Numerical Diffusion Model for Spatio-temporal Traffic Data Imputation
Oct 20, 2024High-quality spatiotemporal traffic data is crucial for intelligent transportation systems (ITS) and their data-driven applications. Inevitably, the issue of missing data caused by various disturbances threatens the reliability of data acquisition. Recent studies of diffusion probability models have demonstrated the superiority of deep generative models in imputation tasks by precisely capturing the spatio-temporal correlation of traffic data. One drawback of diffusion models is their slow sampling/denoising process. In this work, we aim to accelerate the imputation process while retaining the performance. We propose a fast conditional diffusion model for spatiotemporal traffic data imputation (FastSTI). To speed up the process yet, obtain better performance, we propose the application of a high-order pseudo-numerical solver. Our method further revs the imputation by introducing a predefined alignment strategy of variance schedule during the sampling process. Evaluating FastSTI on two types of real-world traffic datasets (traffic speed and flow) with different missing data scenarios proves its ability to impute higher-quality samples in only six sampling steps, especially under high missing rates (60\% $\sim$ 90\%). The experimental results illustrate a speed-up of $\textbf{8.3} \times$ faster than the current state-of-the-art model while achieving better performance.
* This paper has been accepted by IEEE Transactions on Intelligent Transportation Systems for publication. Permission from IEEE must be obtained for all other uses, in any current or future media
Following the Human Thread in Social Navigation
Apr 17, 2024


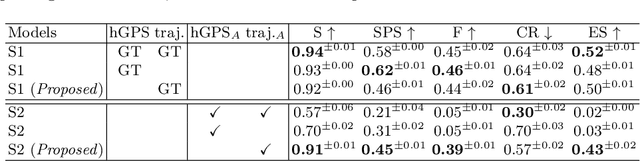
The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
Weakly-Supervised Visual-Textual Grounding with Semantic Prior Refinement
May 18, 2023

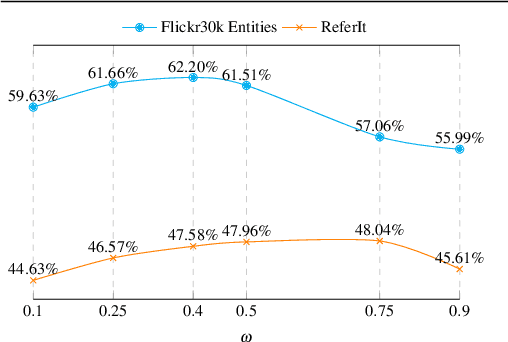

Using only image-sentence pairs, weakly-supervised visual-textual grounding aims to learn region-phrase correspondences of the respective entity mentions. Compared to the supervised approach, learning is more difficult since bounding boxes and textual phrases correspondences are unavailable. In light of this, we propose the Semantic Prior Refinement Model (SPRM), whose predictions are obtained by combining the output of two main modules. The first untrained module aims to return a rough alignment between textual phrases and bounding boxes. The second trained module is composed of two sub-components that refine the rough alignment to improve the accuracy of the final phrase-bounding box alignments. The model is trained to maximize the multimodal similarity between an image and a sentence, while minimizing the multimodal similarity of the same sentence and a new unrelated image, carefully selected to help the most during training. Our approach shows state-of-the-art results on two popular datasets, Flickr30k Entities and ReferIt, shining especially on ReferIt with a 9.6% absolute improvement. Moreover, thanks to the untrained component, it reaches competitive performances just using a small fraction of training examples.
Distilling Knowledge for Short-to-Long Term Trajectory Prediction
May 15, 2023



Long-term trajectory forecasting is a challenging problem in the field of computer vision and machine learning. In this paper, we propose a new method dubbed Di-Long ("Distillation for Long-Term trajectory") for long-term trajectory forecasting, which is based on knowledge distillation. Our approach involves training a student network to solve the long-term trajectory forecasting problem, whereas the teacher network from which the knowledge is distilled has a longer observation, and solves a short-term trajectory prediction problem by regularizing the student's predictions. Specifically, we use a teacher model to generate plausible trajectories for a shorter time horizon, and then distill the knowledge from the teacher model to a student model that solves the problem for a much higher time horizon. Our experiments show that the proposed Di-Long approach is beneficial for long-term forecasting, and our model achieves state-of-the-art performance on the Intersection Drone Dataset (inD) and the Stanford Drone Dataset (SDD).
Exploiting Socially-Aware Tasks for Embodied Social Navigation
Dec 01, 2022Learning how to navigate among humans in an occluded and spatially constrained indoor environment, is a key ability required to embodied agent to be integrated into our society. In this paper, we propose an end-to-end architecture that exploits Socially-Aware Tasks (referred as to Risk and Social Compass) to inject into a reinforcement learning navigation policy the ability to infer common-sense social behaviors. To this end, our tasks exploit the notion of immediate and future dangers of collision. Furthermore, we propose an evaluation protocol specifically designed for the Social Navigation Task in simulated environments. This is done to capture fine-grained features and characteristics of the policy by analyzing the minimal unit of human-robot spatial interaction, called Encounter. We validate our approach on Gibson4+ and Habitat-Matterport3D datasets.
TAMFormer: Multi-Modal Transformer with Learned Attention Mask for Early Intent Prediction
Oct 26, 2022Human intention prediction is a growing area of research where an activity in a video has to be anticipated by a vision-based system. To this end, the model creates a representation of the past, and subsequently, it produces future hypotheses about upcoming scenarios. In this work, we focus on pedestrians' early intention prediction in which, from a current observation of an urban scene, the model predicts the future activity of pedestrians that approach the street. Our method is based on a multi-modal transformer that encodes past observations and produces multiple predictions at different anticipation times. Moreover, we propose to learn the attention masks of our transformer-based model (Temporal Adaptive Mask Transformer) in order to weigh differently present and past temporal dependencies. We investigate our method on several public benchmarks for early intention prediction, improving the prediction performances at different anticipation times compared to the previous works.