 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastSTI: A Fast Conditional Pseudo Numerical Diffusion Model for Spatio-temporal Traffic Data Imputation
Oct 20, 2024High-quality spatiotemporal traffic data is crucial for intelligent transportation systems (ITS) and their data-driven applications. Inevitably, the issue of missing data caused by various disturbances threatens the reliability of data acquisition. Recent studies of diffusion probability models have demonstrated the superiority of deep generative models in imputation tasks by precisely capturing the spatio-temporal correlation of traffic data. One drawback of diffusion models is their slow sampling/denoising process. In this work, we aim to accelerate the imputation process while retaining the performance. We propose a fast conditional diffusion model for spatiotemporal traffic data imputation (FastSTI). To speed up the process yet, obtain better performance, we propose the application of a high-order pseudo-numerical solver. Our method further revs the imputation by introducing a predefined alignment strategy of variance schedule during the sampling process. Evaluating FastSTI on two types of real-world traffic datasets (traffic speed and flow) with different missing data scenarios proves its ability to impute higher-quality samples in only six sampling steps, especially under high missing rates (60\% $\sim$ 90\%). The experimental results illustrate a speed-up of $\textbf{8.3} \times$ faster than the current state-of-the-art model while achieving better performance.
* This paper has been accepted by IEEE Transactions on Intelligent Transportation Systems for publication. Permission from IEEE must be obtained for all other uses, in any current or future media
Temporal Divide-and-Conquer Anomaly Actions Localization in Semi-Supervised Videos with Hierarchical Transformer
Aug 24, 2024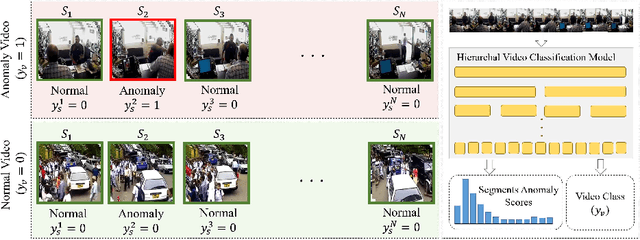
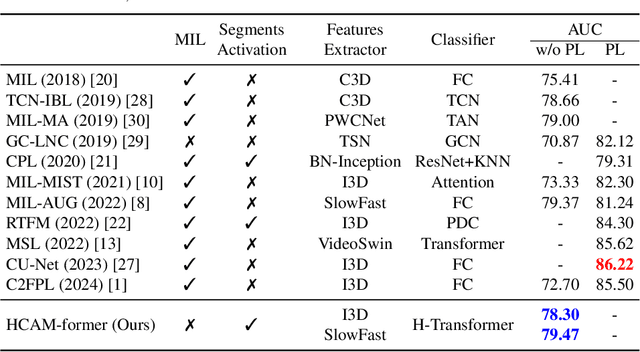
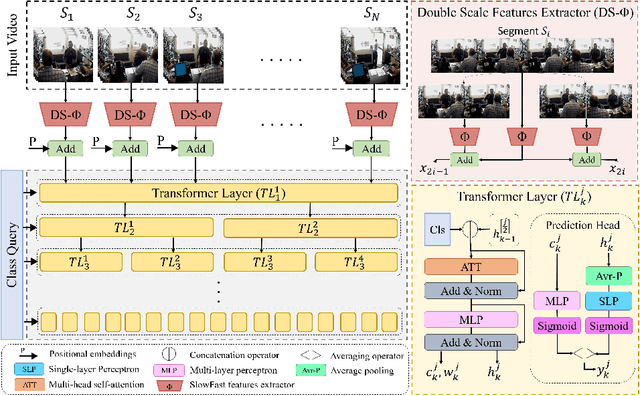
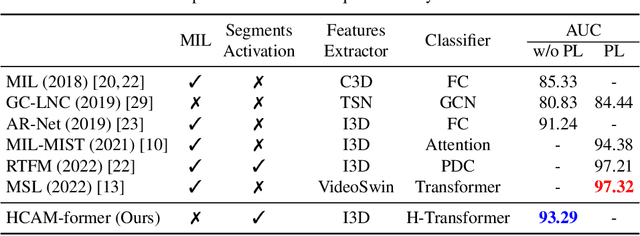
Anomaly action detection and localization play an essential role in security and advanced surveillance systems. However, due to the tremendous amount of surveillance videos, most of the available data for the task is unlabeled or semi-labeled with the video class known, but the location of the anomaly event is unknown. In this work, we target anomaly localization in semi-supervised videos. While the mainstream direction in addressing this task is focused on segment-level multi-instance learning and the generation of pseudo labels, we aim to explore a promising yet unfulfilled direction to solve the problem by learning the temporal relations within videos in order to locate anomaly events. To this end, we propose a hierarchical transformer model designed to evaluate the significance of observed actions in anomalous videos with a divide-and-conquer strategy along the temporal axis. Our approach segments a parent video hierarchically into multiple temporal children instances and measures the influence of the children nodes in classifying the abnormality of the parent video. Evaluating our model on two well-known anomaly detection datasets, UCF-crime and ShanghaiTech, proves its ability to interpret the observed actions within videos and localize the anomalous ones. Our proposed approach outperforms previous works relying on segment-level multiple-instance learning approaches while reaching a promising performance compared to the more recent pseudo-labeling-based approaches.
TAMFormer: Multi-Modal Transformer with Learned Attention Mask for Early Intent Prediction
Oct 26, 2022Human intention prediction is a growing area of research where an activity in a video has to be anticipated by a vision-based system. To this end, the model creates a representation of the past, and subsequently, it produces future hypotheses about upcoming scenarios. In this work, we focus on pedestrians' early intention prediction in which, from a current observation of an urban scene, the model predicts the future activity of pedestrians that approach the street. Our method is based on a multi-modal transformer that encodes past observations and produces multiple predictions at different anticipation times. Moreover, we propose to learn the attention masks of our transformer-based model (Temporal Adaptive Mask Transformer) in order to weigh differently present and past temporal dependencies. We investigate our method on several public benchmarks for early intention prediction, improving the prediction performances at different anticipation times compared to the previous works.
SlowFast Rolling-Unrolling LSTMs for Action Anticipation in Egocentric Videos
Sep 02, 2021

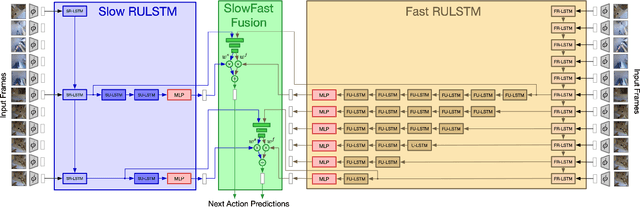

Action anticipation in egocentric videos is a difficult task due to the inherently multi-modal nature of human actions. Additionally, some actions happen faster or slower than others depending on the actor or surrounding context which could vary each time and lead to different predictions. Based on this idea, we build upon RULSTM architecture, which is specifically designed for anticipating human actions, and propose a novel attention-based technique to evaluate, simultaneously, slow and fast features extracted from three different modalities, namely RGB, optical flow, and extracted objects. Two branches process information at different time scales, i.e., frame-rates, and several fusion schemes are considered to improve prediction accuracy. We perform extensive experiments on EpicKitchens-55 and EGTEA Gaze+ datasets, and demonstrate that our technique systematically improves the results of RULSTM architecture for Top-5 accuracy metric at different anticipation times.