 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-driven Self-Attentive Recurrent Networks for Trajectory Prediction
Apr 25, 2022



Human trajectory forecasting is a key component of autonomous vehicles, social-aware robots and advanced video-surveillance applications. This challenging task typically requires knowledge about past motion, the environment and likely destination areas. In this context, multi-modality is a fundamental aspect and its effective modeling can be beneficial to any architecture. Inferring accurate trajectories is nevertheless challenging, due to the inherently uncertain nature of the future. To overcome these difficulties, recent models use different inputs and propose to model human intentions using complex fusion mechanisms. In this respect, we propose a lightweight attention-based recurrent backbone that acts solely on past observed positions. Although this backbone already provides promising results, we demonstrate that its prediction accuracy can be improved considerably when combined with a scene-aware goal-estimation module. To this end, we employ a common goal module, based on a U-Net architecture, which additionally extracts semantic information to predict scene-compliant destinations. We conduct extensive experiments on publicly-available datasets (i.e. SDD, inD, ETH/UCY) and show that our approach performs on par with state-of-the-art techniques while reducing model complexity.
How many Observations are Enough? Knowledge Distillation for Trajectory Forecasting
Mar 09, 2022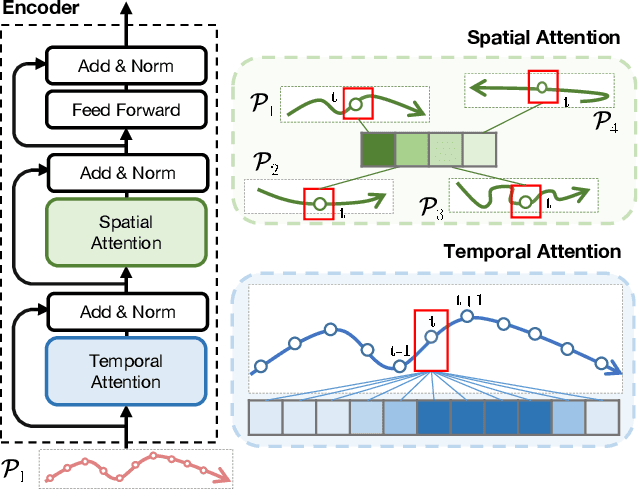
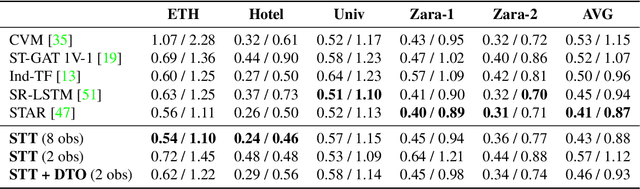
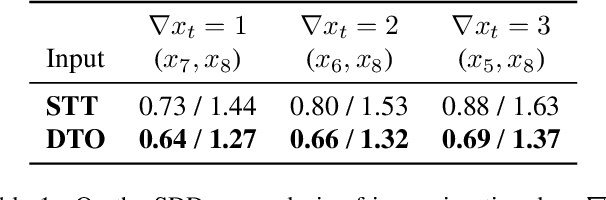
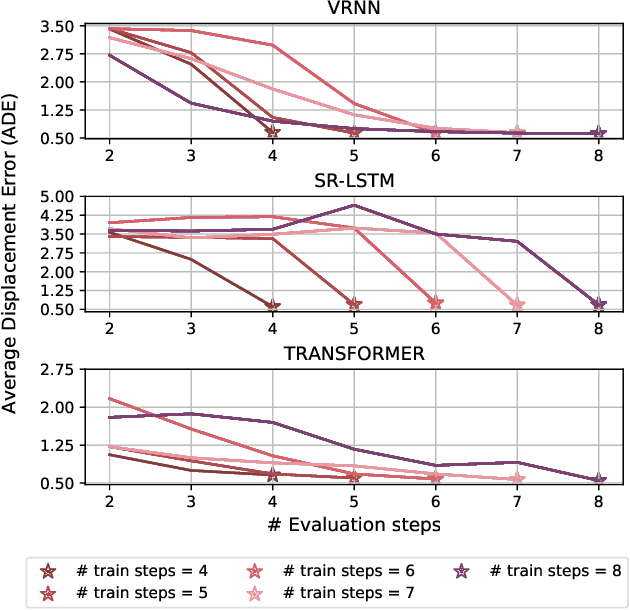
Accurate prediction of future human positions is an essential task for modern video-surveillance systems. Current state-of-the-art models usually rely on a "history" of past tracked locations (e.g., 3 to 5 seconds) to predict a plausible sequence of future locations (e.g., up to the next 5 seconds). We feel that this common schema neglects critical traits of realistic applications: as the collection of input trajectories involves machine perception (i.e., detection and tracking), incorrect detection and fragmentation errors may accumulate in crowded scenes, leading to tracking drifts. On this account, the model would be fed with corrupted and noisy input data, thus fatally affecting its prediction performance. In this regard, we focus on delivering accurate predictions when only few input observations are used, thus potentially lowering the risks associated with automatic perception. To this end, we conceive a novel distillation strategy that allows a knowledge transfer from a teacher network to a student one, the latter fed with fewer observations (just two ones). We show that a properly defined teacher supervision allows a student network to perform comparably to state-of-the-art approaches that demand more observations. Besides, extensive experiments on common trajectory forecasting datasets highlight that our student network better generalizes to unseen scenarios.
SlowFast Rolling-Unrolling LSTMs for Action Anticipation in Egocentric Videos
Sep 02, 2021

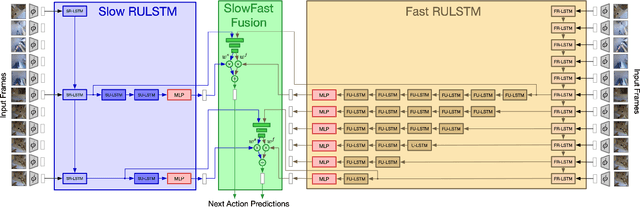

Action anticipation in egocentric videos is a difficult task due to the inherently multi-modal nature of human actions. Additionally, some actions happen faster or slower than others depending on the actor or surrounding context which could vary each time and lead to different predictions. Based on this idea, we build upon RULSTM architecture, which is specifically designed for anticipating human actions, and propose a novel attention-based technique to evaluate, simultaneously, slow and fast features extracted from three different modalities, namely RGB, optical flow, and extracted objects. Two branches process information at different time scales, i.e., frame-rates, and several fusion schemes are considered to improve prediction accuracy. We perform extensive experiments on EpicKitchens-55 and EGTEA Gaze+ datasets, and demonstrate that our technique systematically improves the results of RULSTM architecture for Top-5 accuracy metric at different anticipation times.
AC-VRNN: Attentive Conditional-VRNN for Multi-Future Trajectory Prediction
May 17, 2020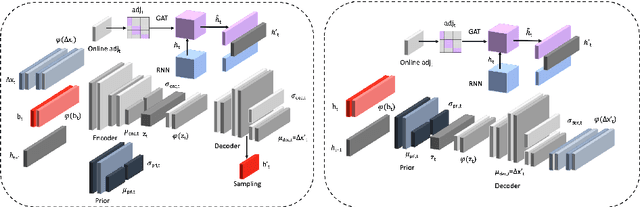
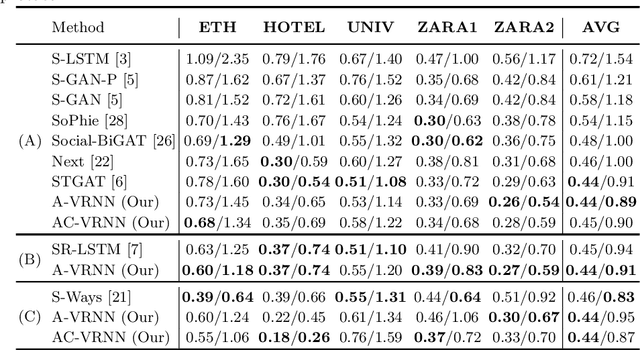
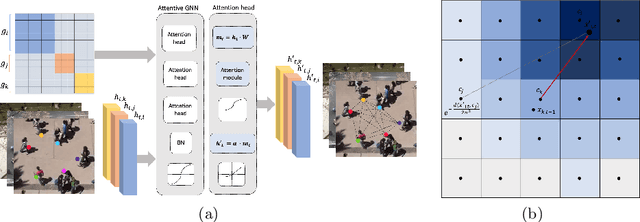
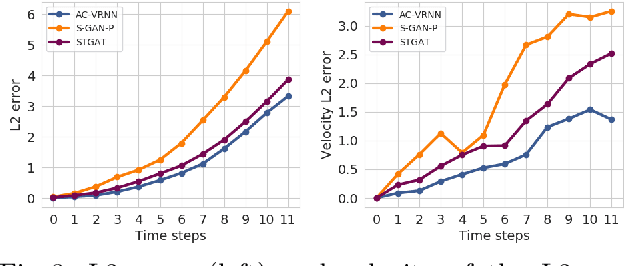
Anticipating human motion in crowded scenarios is essential for developing intelligent transportation systems, social-aware robots and advanced video-surveillance applications. An important aspect of such task is represented by the inherently multi-modal nature of human paths which makes socially-acceptable multiple futures when human interactions are involved. To this end, we propose a new generative model for multi-future trajectory prediction based on Conditional Variational Recurrent Neural Networks (C-VRNNs). Conditioning relies on prior belief maps, representing most likely moving directions and forcing the model to consider the collective agents' motion. Human interactions are modeled in a structured way with a graph attention mechanism, providing an online attentive hidden state refinement of the recurrent estimation. Compared to sequence-to-sequence methods, our model operates step-by-step, generating more refined and accurate predictions. To corroborate our model, we perform extensive experiments on publicly-available datasets (ETH, UCY and Stanford Drone Dataset) and demonstrate its effectiveness compared to state-of-the-art methods.
Knowledge Distillation for Action Anticipation via Label Smoothing
Apr 16, 2020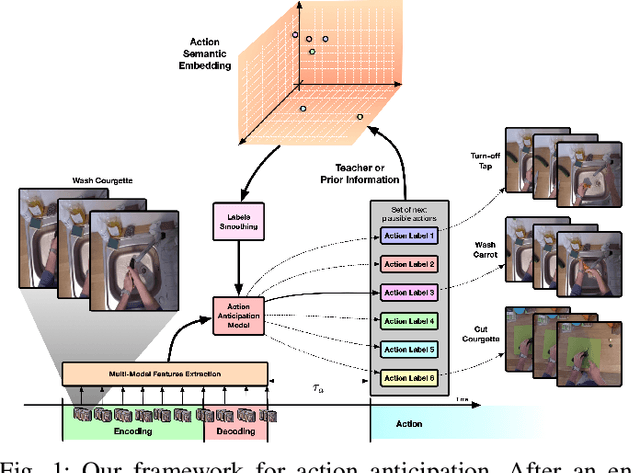

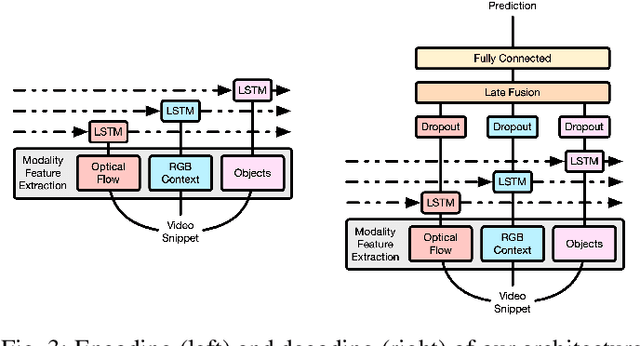

Human capability to anticipate near future from visual observations and non-verbal cues is essential for developing intelligent systems that need to interact with people. Several research areas, such as human-robot interaction (HRI), assisted living or autonomous driving need to foresee future events to avoid crashes or help visually impaired people. Such challenging task requires to capture and understand the underlying structure of the analyzed domain in order to reduce prediction uncertainty. Since the action anticipation task can be seen as a multi-label problem with missing labels, we design and extend the idea of label smoothing extracting semantics from the target labels. We show that such generalization is equivalent to considering a knowledge distillation framework where a teacher injects useful semantic information into the model during training. In our experiments, we implement a multi-modal framework based on long short-term memory (LSTM) networks to anticipate future actions which is able to summarise past observations while making predictions of the future at different time steps. To validate our soft labeling procedure we perform extensive experiments on the egocentric EPIC-Kitchens dataset which includes more than 2500 action classes. The experiments show that label smoothing systematically improves performance of state-of-the-art models.
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Oct 13, 2019


Images represent a commonly used form of visual communication among people. Nevertheless, image classification may be a challenging task when dealing with unclear or non-common images needing more context to be correctly annotated. Metadata accompanying images on social-media represent an ideal source of additional information for retrieving proper neighbourhoods easing image annotation task. To this end, we blend visual features extracted from neighbours and their metadata to jointly leverage context and visual cues. Our models use multiple semantic embeddings to properly map metadata to a meaningful semantic space decoupling the neural model from the low-level representation of metadata and achieve robustness to vocabulary changes between training and testing phases. Convolutional and recurrent neural networks (CNNs-RNNs) are jointly adopted to infer similarity among neighbours and query images. We perform comprehensive experiments on the NUS-WIDE dataset showing that our models outperform state-of-the-art architectures based on images and metadata, and decrease both sensory and semantic gaps to better annotate images.
Social and Scene-Aware Trajectory Prediction in Crowded Spaces
Sep 19, 2019


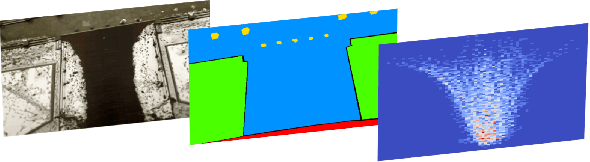
Mimicking human ability to forecast future positions or interpret complex interactions in urban scenarios, such as streets, shopping malls or squares, is essential to develop socially compliant robots or self-driving cars. Autonomous systems may gain advantage on anticipating human motion to avoid collisions or to naturally behave alongside people. To foresee plausible trajectories, we construct an LSTM (long short-term memory)-based model considering three fundamental factors: people interactions, past observations in terms of previously crossed areas and semantics of surrounding space. Our model encompasses several pooling mechanisms to join the above elements defining multiple tensors, namely social, navigation and semantic tensors. The network is tested in unstructured environments where complex paths emerge according to both internal (intentions) and external (other people, not accessible areas) motivations. As demonstrated, modeling paths unaware of social interactions or context information, is insufficient to correctly predict future positions. Experimental results corroborate the effectiveness of the proposed framework in comparison to LSTM-based models for human path prediction.
3-D Hand Pose Estimation from Kinect's Point Cloud Using Appearance Matching
Apr 07, 2016

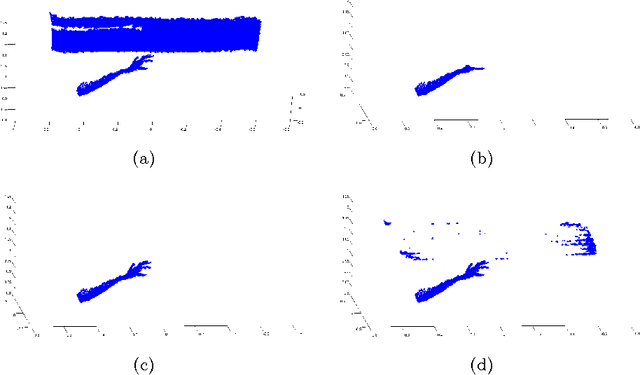
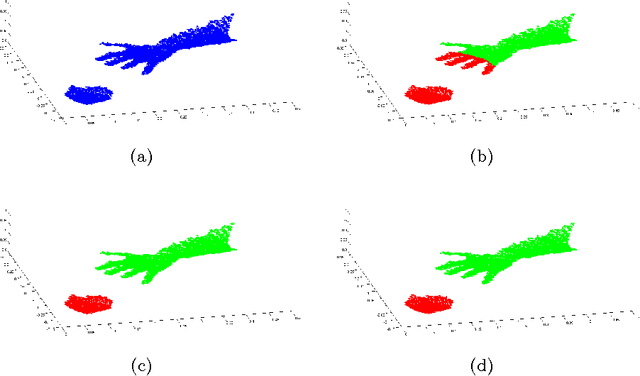
We present a novel appearance-based approach for pose estimation of a human hand using the point clouds provided by the low-cost Microsoft Kinect sensor. Both the free-hand case, in which the hand is isolated from the surrounding environment, and the hand-object case, in which the different types of interactions are classified, have been considered. The hand-object case is clearly the most challenging task having to deal with multiple tracks. The approach proposed here belongs to the class of partial pose estimation where the estimated pose in a frame is used for the initialization of the next one. The pose estimation is obtained by applying a modified version of the Iterative Closest Point (ICP) algorithm to synthetic models to obtain the rigid transformation that aligns each model with respect to the input data. The proposed framework uses a "pure" point cloud as provided by the Kinect sensor without any other information such as RGB values or normal vector components. For this reason, the proposed method can also be applied to data obtained from other types of depth sensor, or RGB-D camera.