 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer for Scene-specific Motion Prediction
Jul 26, 2016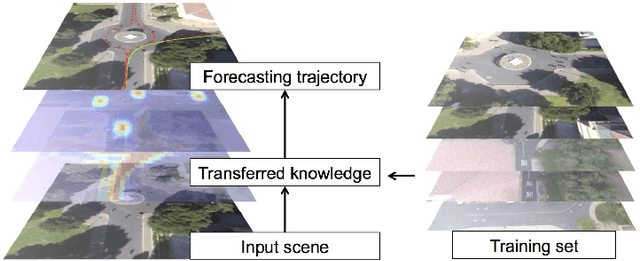
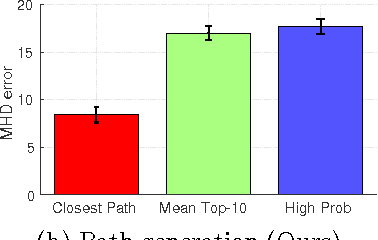
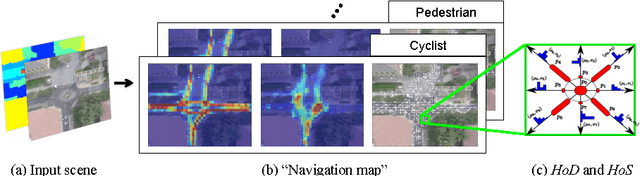
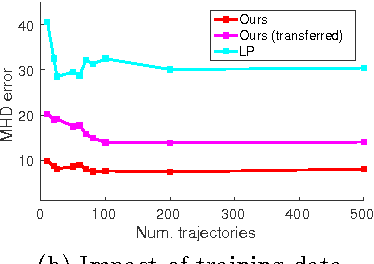
When given a single frame of the video, humans can not only interpret the content of the scene, but also they are able to forecast the near future. This ability is mostly driven by their rich prior knowledge about the visual world, both in terms of (i) the dynamics of moving agents, as well as (ii) the semantic of the scene. In this work we exploit the interplay between these two key elements to predict scene-specific motion patterns. First, we extract patch descriptors encoding the probability of moving to the adjacent patches, and the probability of being in that particular patch or changing behavior. Then, we introduce a Dynamic Bayesian Network which exploits this scene specific knowledge for trajectory prediction. Experimental results demonstrate that our method is able to accurately predict trajectories and transfer predictions to a novel scene characterized by similar elements.
3-D Hand Pose Estimation from Kinect's Point Cloud Using Appearance Matching
Apr 07, 2016

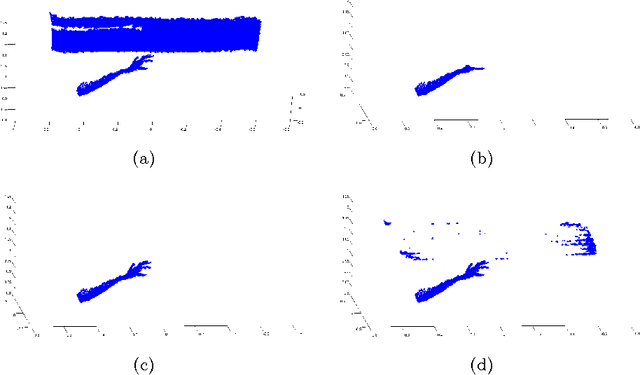
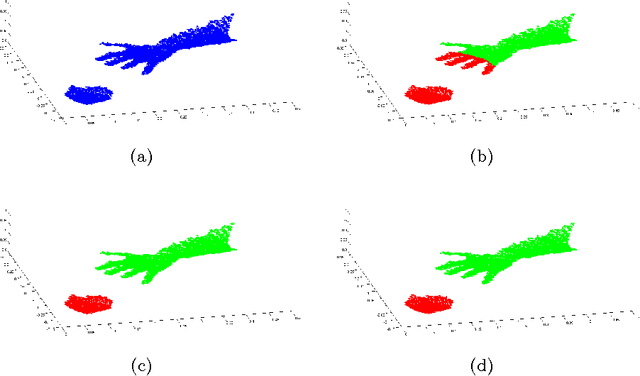
We present a novel appearance-based approach for pose estimation of a human hand using the point clouds provided by the low-cost Microsoft Kinect sensor. Both the free-hand case, in which the hand is isolated from the surrounding environment, and the hand-object case, in which the different types of interactions are classified, have been considered. The hand-object case is clearly the most challenging task having to deal with multiple tracks. The approach proposed here belongs to the class of partial pose estimation where the estimated pose in a frame is used for the initialization of the next one. The pose estimation is obtained by applying a modified version of the Iterative Closest Point (ICP) algorithm to synthetic models to obtain the rigid transformation that aligns each model with respect to the input data. The proposed framework uses a "pure" point cloud as provided by the Kinect sensor without any other information such as RGB values or normal vector components. For this reason, the proposed method can also be applied to data obtained from other types of depth sensor, or RGB-D camera.
Semantic Cross-View Matching
Oct 31, 2015
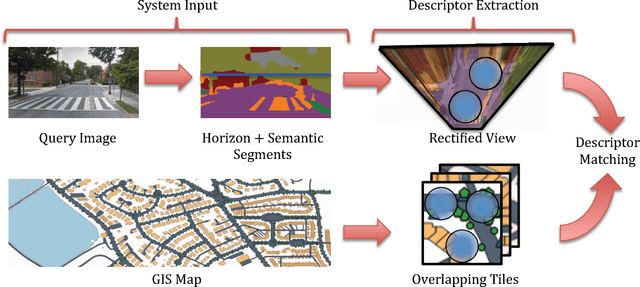

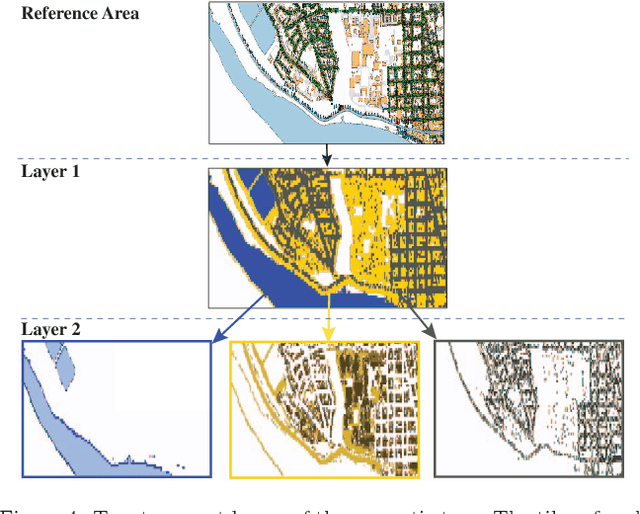
Matching cross-view images is challenging because the appearance and viewpoints are significantly different. While low-level features based on gradient orientations or filter responses can drastically vary with such changes in viewpoint, semantic information of images however shows an invariant characteristic in this respect. Consequently, semantically labeled regions can be used for performing cross-view matching. In this paper, we therefore explore this idea and propose an automatic method for detecting and representing the semantic information of an RGB image with the goal of performing cross-view matching with a (non-RGB) geographic information system (GIS). A segmented image forms the input to our system with segments assigned to semantic concepts such as traffic signs, lakes, roads, foliage, etc. We design a descriptor to robustly capture both, the presence of semantic concepts and the spatial layout of those segments. Pairwise distances between the descriptors extracted from the GIS map and the query image are then used to generate a shortlist of the most promising locations with similar semantic concepts in a consistent spatial layout. An experimental evaluation with challenging query images and a large urban area shows promising results.