 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Cross-View Matching
Paper and Code
Oct 31, 2015
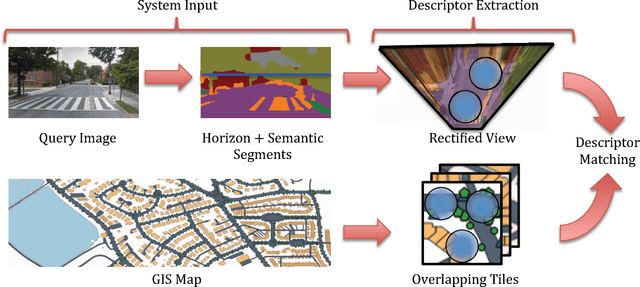

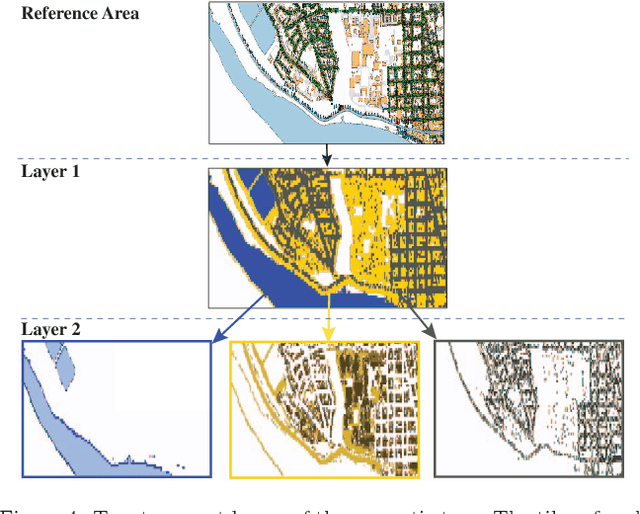
Matching cross-view images is challenging because the appearance and viewpoints are significantly different. While low-level features based on gradient orientations or filter responses can drastically vary with such changes in viewpoint, semantic information of images however shows an invariant characteristic in this respect. Consequently, semantically labeled regions can be used for performing cross-view matching. In this paper, we therefore explore this idea and propose an automatic method for detecting and representing the semantic information of an RGB image with the goal of performing cross-view matching with a (non-RGB) geographic information system (GIS). A segmented image forms the input to our system with segments assigned to semantic concepts such as traffic signs, lakes, roads, foliage, etc. We design a descriptor to robustly capture both, the presence of semantic concepts and the spatial layout of those segments. Pairwise distances between the descriptors extracted from the GIS map and the query image are then used to generate a shortlist of the most promising locations with similar semantic concepts in a consistent spatial layout. An experimental evaluation with challenging query images and a large urban area shows promising results.