 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Oct 13, 2019
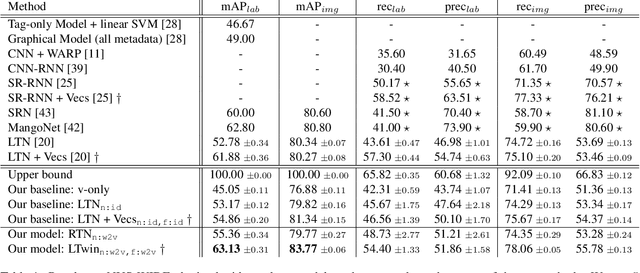


Images represent a commonly used form of visual communication among people. Nevertheless, image classification may be a challenging task when dealing with unclear or non-common images needing more context to be correctly annotated. Metadata accompanying images on social-media represent an ideal source of additional information for retrieving proper neighbourhoods easing image annotation task. To this end, we blend visual features extracted from neighbours and their metadata to jointly leverage context and visual cues. Our models use multiple semantic embeddings to properly map metadata to a meaningful semantic space decoupling the neural model from the low-level representation of metadata and achieve robustness to vocabulary changes between training and testing phases. Convolutional and recurrent neural networks (CNNs-RNNs) are jointly adopted to infer similarity among neighbours and query images. We perform comprehensive experiments on the NUS-WIDE dataset showing that our models outperform state-of-the-art architectures based on images and metadata, and decrease both sensory and semantic gaps to better annotate images.