 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-VRNN: Attentive Conditional-VRNN for Multi-Future Trajectory Prediction
Paper and Code
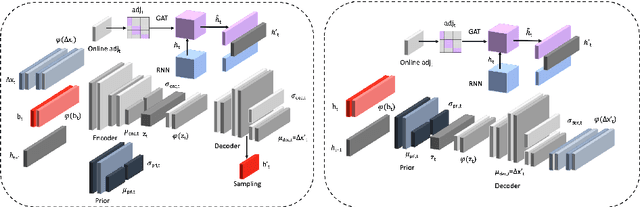
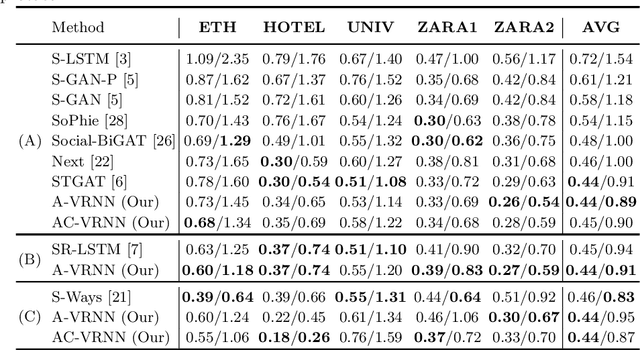
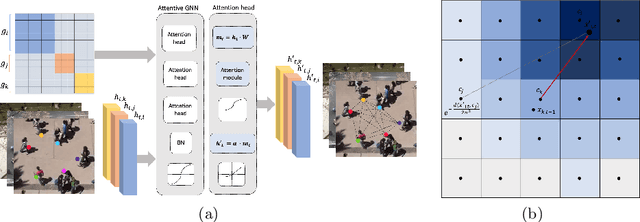
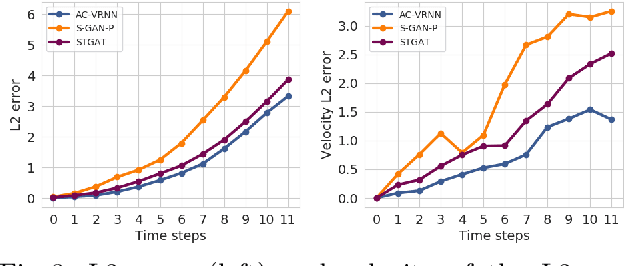
Anticipating human motion in crowded scenarios is essential for developing intelligent transportation systems, social-aware robots and advanced video-surveillance applications. An important aspect of such task is represented by the inherently multi-modal nature of human paths which makes socially-acceptable multiple futures when human interactions are involved. To this end, we propose a new generative model for multi-future trajectory prediction based on Conditional Variational Recurrent Neural Networks (C-VRNNs). Conditioning relies on prior belief maps, representing most likely moving directions and forcing the model to consider the collective agents' motion. Human interactions are modeled in a structured way with a graph attention mechanism, providing an online attentive hidden state refinement of the recurrent estimation. Compared to sequence-to-sequence methods, our model operates step-by-step, generating more refined and accurate predictions. To corroborate our model, we perform extensive experiments on publicly-available datasets (ETH, UCY and Stanford Drone Dataset) and demonstrate its effectiveness compared to state-of-the-art methods.