 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralising via Meta-Examples for Continual Learning in the Wild
Jan 28, 2021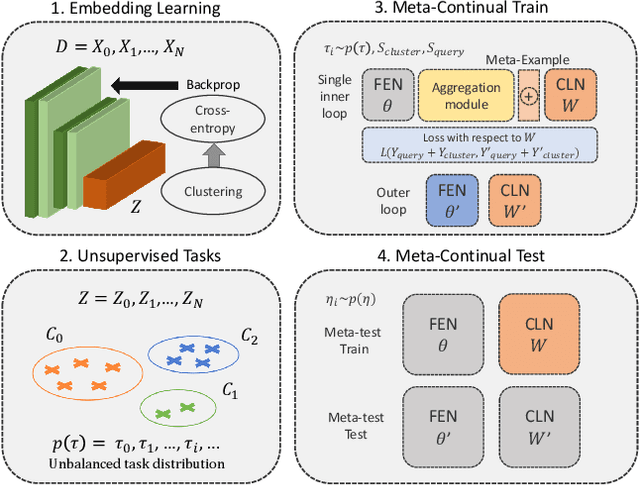
Learning quickly and continually is still an ambitious task for neural networks. Indeed, many real-world applications do not reflect the learning setting where neural networks shine, as data are usually few, mostly unlabelled and come as a stream. To narrow this gap, we introduce FUSION - Few-shot UnSupervIsed cONtinual learning - a novel strategy which aims to deal with neural networks that "learn in the wild", simulating a real distribution and flow of unbalanced tasks. We equip FUSION with MEML - Meta-Example Meta-Learning - a new module that simultaneously alleviates catastrophic forgetting and favours the generalisation and future learning of new tasks. To encourage features reuse during the meta-optimisation, our model exploits a single inner loop per task, taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. To further enhance the generalisation capability of MEML, we extend it by adopting a technique that creates various augmented tasks and optimises over the hardest. Experimental results on few-shot learning benchmarks show that our model exceeds the other baselines in both FUSION and fully supervised case. We also explore how it behaves in standard continual learning consistently outperforming state-of-the-art approaches.
Few-Shot Unsupervised Continual Learning through Meta-Examples
Sep 17, 2020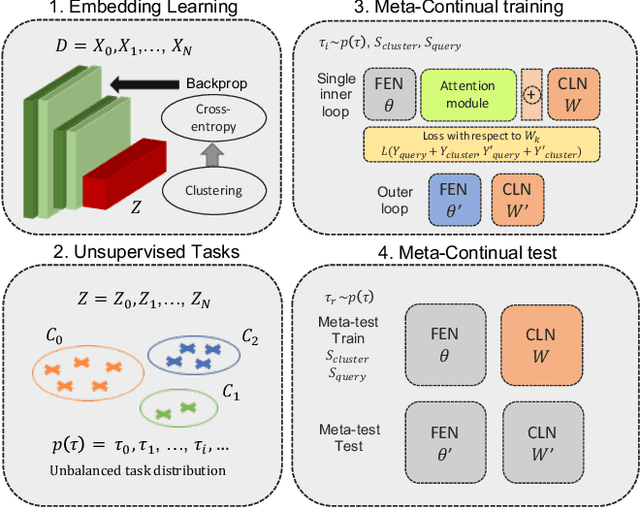
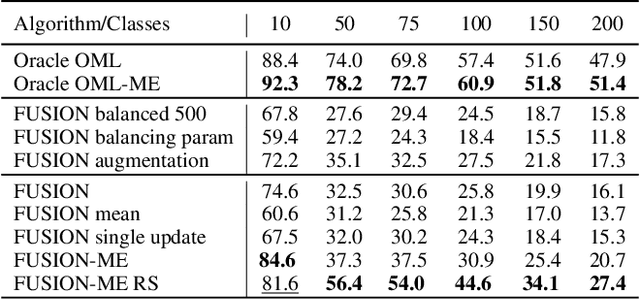
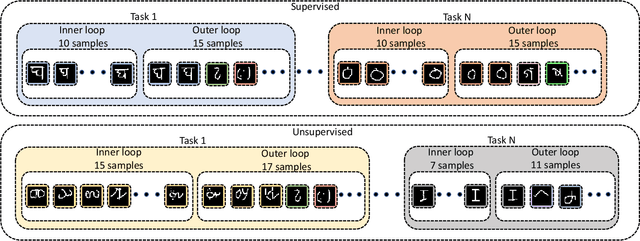
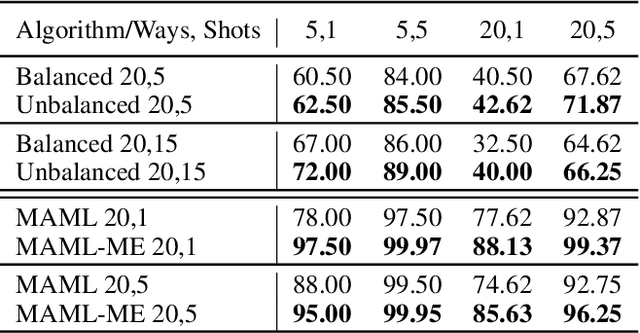
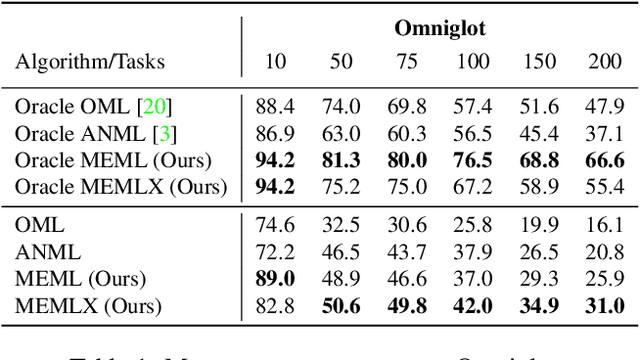
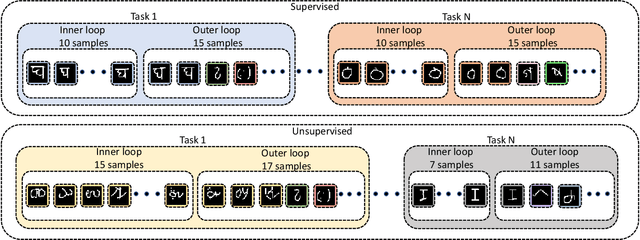
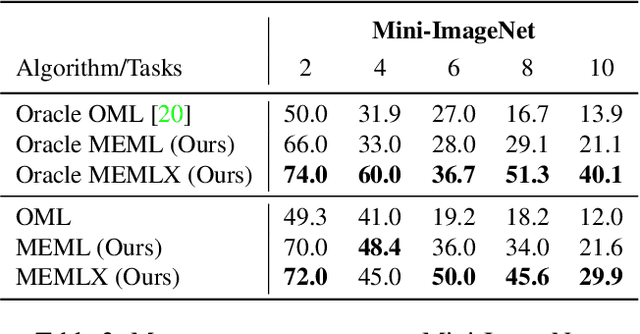
In real-world applications, data do not reflect the ones commonly used for neural networks training, since they are usually few, unbalanced, unlabeled and can be available as a stream. Hence many existing deep learning solutions suffer from a limited range of applications, in particular in the case of online streaming data that evolve over time. To narrow this gap, in this work we introduce a novel and complex setting involving unsupervised meta-continual learning with unbalanced tasks. These tasks are built through a clustering procedure applied to a fitted embedding space. We exploit a meta-learning scheme that simultaneously alleviates catastrophic forgetting and favors the generalization to new tasks, even Out-of-Distribution ones. Moreover, to encourage feature reuse during the meta-optimization, we exploit a single inner loop taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. Experimental results on few-shot learning benchmarks show competitive performance even compared to the supervised case. Additionally, we empirically observe that in an unsupervised scenario, the small tasks and the variability in the clusters pooling play a crucial role in the generalization capability of the network. Further, on complex datasets, the exploitation of more clusters than the true number of classes leads to higher results, even compared to the ones obtained with full supervision, suggesting that a predefined partitioning into classes can miss relevant structural information.
DAG-Net: Double Attentive Graph Neural Network for Trajectory Forecasting
May 26, 2020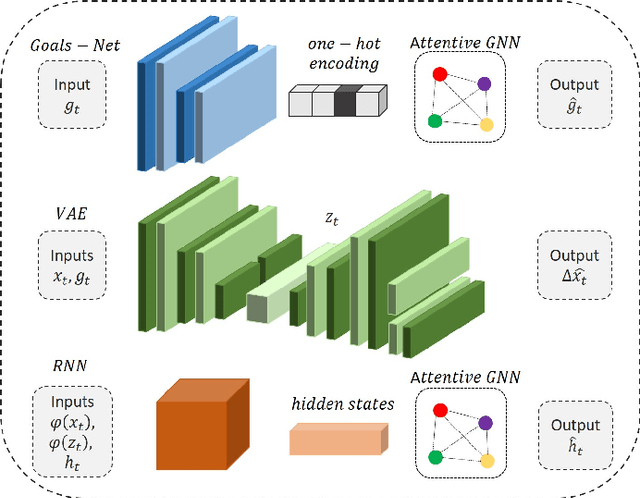
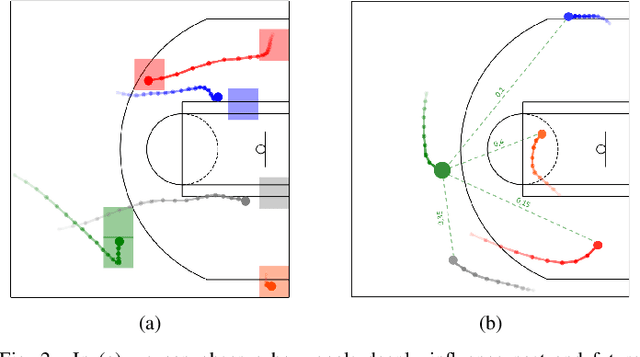
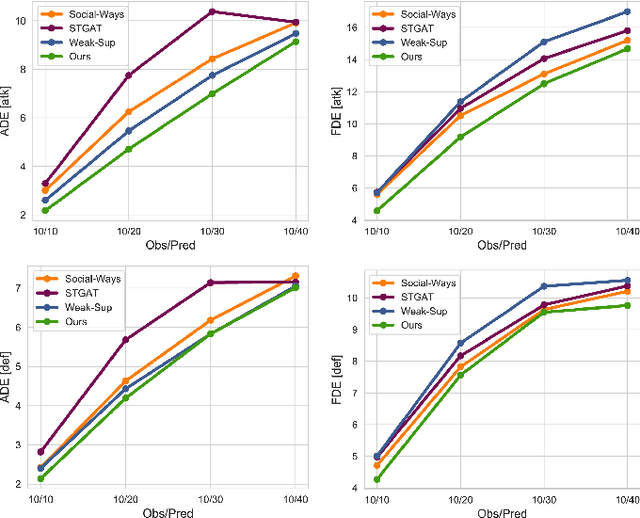
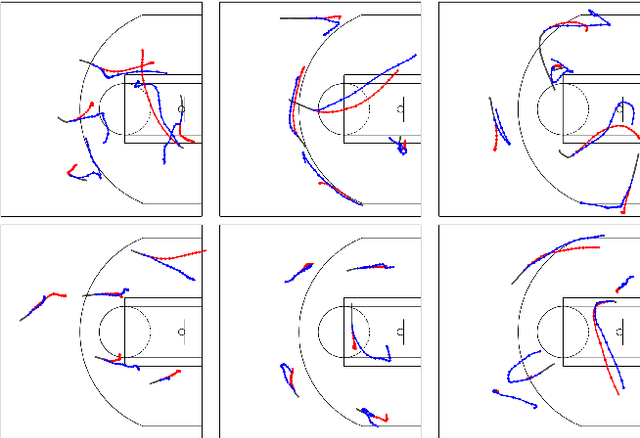
Understanding human motion behaviour is a critical task for several possible applications like self-driving cars or social robots, and in general for all those settings where an autonomous agent has to navigate inside a human-centric environment. This is non-trivial because human motion is inherently multi-modal: given a history of human motion paths, there are many plausible ways by which people could move in the future. Additionally, people activities are often driven by goals, e.g. reaching particular locations or interacting with the environment. We address both the aforementioned aspects by proposing a new recurrent generative model that considers both single agents' future goals and interactions between different agents. The model exploits a double attention-based graph neural network to collect information about the mutual influences among different agents and integrates it with data about agents' possible future objectives. Our proposal is general enough to be applied in different scenarios: the model achieves state-of-the-art results in both urban environments and also in sports applications.
AC-VRNN: Attentive Conditional-VRNN for Multi-Future Trajectory Prediction
May 17, 2020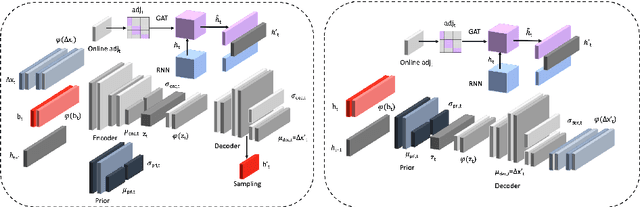
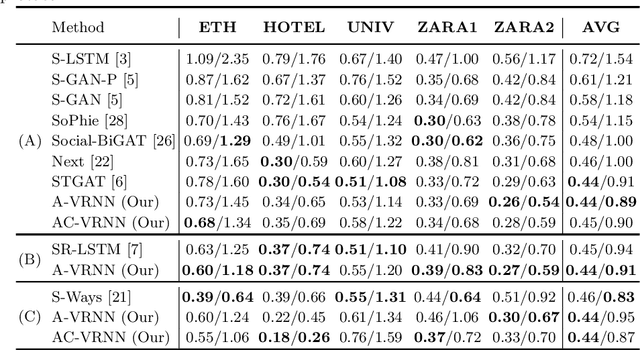
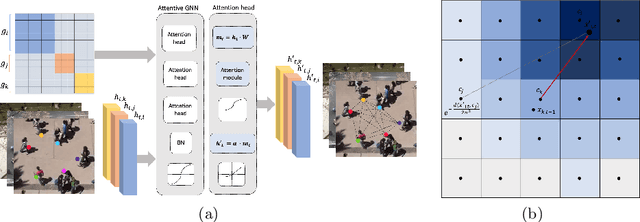
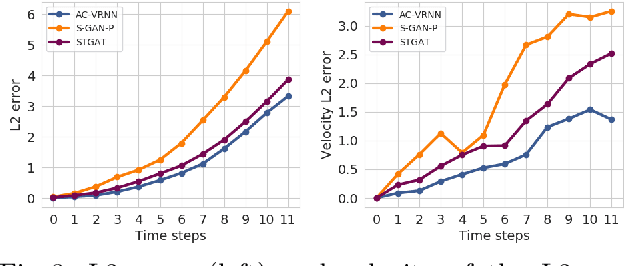
Anticipating human motion in crowded scenarios is essential for developing intelligent transportation systems, social-aware robots and advanced video-surveillance applications. An important aspect of such task is represented by the inherently multi-modal nature of human paths which makes socially-acceptable multiple futures when human interactions are involved. To this end, we propose a new generative model for multi-future trajectory prediction based on Conditional Variational Recurrent Neural Networks (C-VRNNs). Conditioning relies on prior belief maps, representing most likely moving directions and forcing the model to consider the collective agents' motion. Human interactions are modeled in a structured way with a graph attention mechanism, providing an online attentive hidden state refinement of the recurrent estimation. Compared to sequence-to-sequence methods, our model operates step-by-step, generating more refined and accurate predictions. To corroborate our model, we perform extensive experiments on publicly-available datasets (ETH, UCY and Stanford Drone Dataset) and demonstrate its effectiveness compared to state-of-the-art methods.
Learning to Grasp from 2.5D images: a Deep Reinforcement Learning Approach
Aug 08, 2019


In this paper, we propose a deep reinforcement learning (DRL) solution to the grasping problem using 2.5D images as the only source of information. In particular, we developed a simulated environment where a robot equipped with a vacuum gripper has the aim of reaching blocks with planar surfaces. These blocks can have different dimensions, shapes, position and orientation. Unity 3D allowed us to simulate a real-world setup, where a depth camera is placed in a fixed position and the stream of images is used by our policy network to learn how to solve the task. We explored different DRL algorithms and problem configurations. The experiments demonstrated the effectiveness of the proposed DRL algorithm applied to grasp tasks guided by visual depth camera inputs. When using the proper policy, the proposed method estimates a robot tool configuration that reaches the object surface with negligible position and orientation errors. This is, to the best of our knowledge, the first successful attempt of using 2.5D images only as of the input of a DRL algorithm, to solve the grasping problem regressing 3D world coordinates.