 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Unsupervised Continual Learning through Meta-Examples
Paper and Code
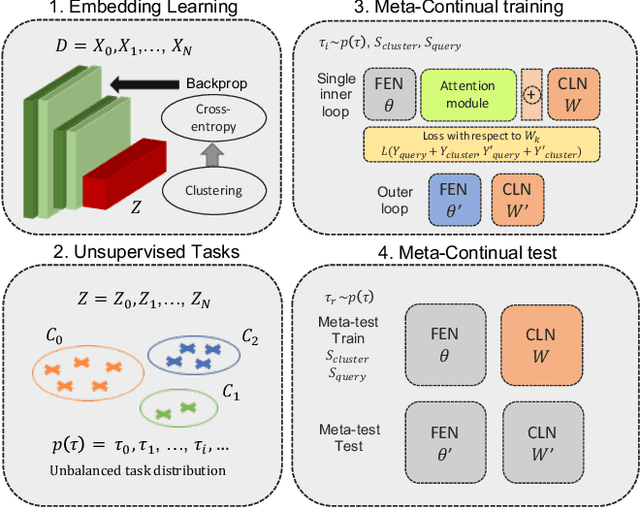
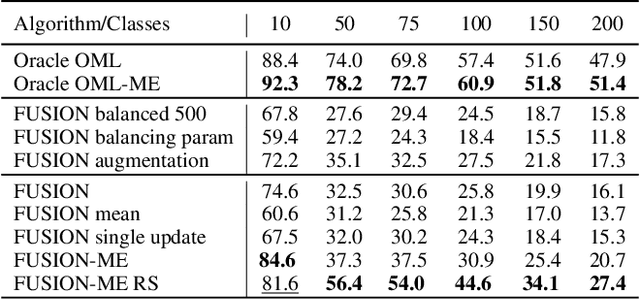
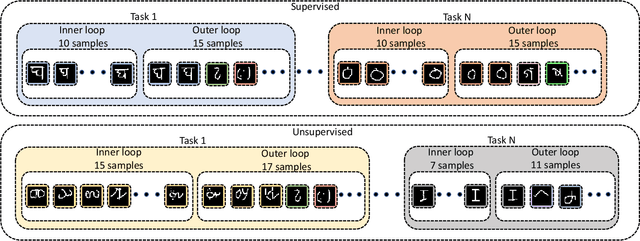
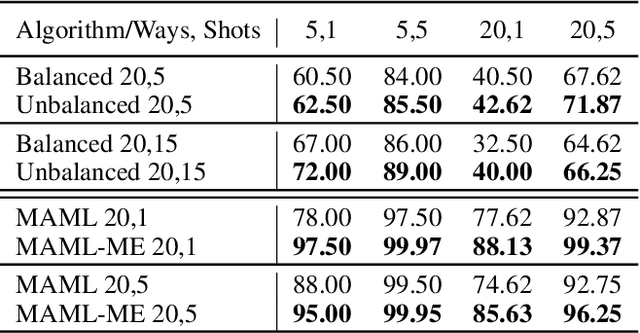
In real-world applications, data do not reflect the ones commonly used for neural networks training, since they are usually few, unbalanced, unlabeled and can be available as a stream. Hence many existing deep learning solutions suffer from a limited range of applications, in particular in the case of online streaming data that evolve over time. To narrow this gap, in this work we introduce a novel and complex setting involving unsupervised meta-continual learning with unbalanced tasks. These tasks are built through a clustering procedure applied to a fitted embedding space. We exploit a meta-learning scheme that simultaneously alleviates catastrophic forgetting and favors the generalization to new tasks, even Out-of-Distribution ones. Moreover, to encourage feature reuse during the meta-optimization, we exploit a single inner loop taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. Experimental results on few-shot learning benchmarks show competitive performance even compared to the supervised case. Additionally, we empirically observe that in an unsupervised scenario, the small tasks and the variability in the clusters pooling play a crucial role in the generalization capability of the network. Further, on complex datasets, the exploitation of more clusters than the true number of classes leads to higher results, even compared to the ones obtained with full supervision, suggesting that a predefined partitioning into classes can miss relevant structural information.