 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally-Aware Supervised Contrastive Learning for Polyp Counting in Colonoscopy
Jul 03, 2025Automated polyp counting in colonoscopy is a crucial step toward automated procedure reporting and quality control, aiming to enhance the cost-effectiveness of colonoscopy screening. Counting polyps in a procedure involves detecting and tracking polyps, and then clustering tracklets that belong to the same polyp entity. Existing methods for polyp counting rely on self-supervised learning and primarily leverage visual appearance, neglecting temporal relationships in both tracklet feature learning and clustering stages. In this work, we introduce a paradigm shift by proposing a supervised contrastive loss that incorporates temporally-aware soft targets. Our approach captures intra-polyp variability while preserving inter-polyp discriminability, leading to more robust clustering. Additionally, we improve tracklet clustering by integrating a temporal adjacency constraint, reducing false positive re-associations between visually similar but temporally distant tracklets. We train and validate our method on publicly available datasets and evaluate its performance with a leave-one-out cross-validation strategy. Results demonstrate a 2.2x reduction in fragmentation rate compared to prior approaches. Our results highlight the importance of temporal awareness in polyp counting, establishing a new state-of-the-art. Code is available at https://github.com/lparolari/temporally-aware-polyp-counting.
Hard-Attention Gates with Gradient Routing for Endoscopic Image Computing
Jul 05, 2024To address overfitting and enhance model generalization in gastroenterological polyp size assessment, our study introduces Feature-Selection Gates (FSG) or Hard-Attention Gates (HAG) alongside Gradient Routing (GR) for dynamic feature selection. This technique aims to boost Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) by promoting sparse connectivity, thereby reducing overfitting and enhancing generalization. HAG achieves this through sparsification with learnable weights, serving as a regularization strategy. GR further refines this process by optimizing HAG parameters via dual forward passes, independently from the main model, to improve feature re-weighting. Our evaluation spanned multiple datasets, including CIFAR-100 for a broad impact assessment and specialized endoscopic datasets (REAL-Colon, Misawa, and SUN) focusing on polyp size estimation, covering over 200 polyps in more than 370,000 frames. The findings indicate that our HAG-enhanced networks substantially enhance performance in both binary and triclass classification tasks related to polyp sizing. Specifically, CNNs experienced an F1 Score improvement to 87.8% in binary classification, while in triclass classification, the ViT-T model reached an F1 Score of 76.5%, outperforming traditional CNNs and ViT-T models. To facilitate further research, we are releasing our codebase, which includes implementations for CNNs, multistream CNNs, ViT, and HAG-augmented variants. This resource aims to standardize the use of endoscopic datasets, providing public training-validation-testing splits for reliable and comparable research in gastroenterological polyp size estimation. The codebase is available at github.com/cosmoimd/feature-selection-gates.
* Attention Gates, Hard-Attention Gates, Gradient Routing, Feature Selection Gates, Endoscopy, Medical Image Processing, Computer Vision
REAL-Colon: A dataset for developing real-world AI applications in colonoscopy
Mar 04, 2024Detection and diagnosis of colon polyps are key to preventing colorectal cancer. Recent evidence suggests that AI-based computer-aided detection (CADe) and computer-aided diagnosis (CADx) systems can enhance endoscopists' performance and boost colonoscopy effectiveness. However, most available public datasets primarily consist of still images or video clips, often at a down-sampled resolution, and do not accurately represent real-world colonoscopy procedures. We introduce the REAL-Colon (Real-world multi-center Endoscopy Annotated video Library) dataset: a compilation of 2.7M native video frames from sixty full-resolution, real-world colonoscopy recordings across multiple centers. The dataset contains 350k bounding-box annotations, each created under the supervision of expert gastroenterologists. Comprehensive patient clinical data, colonoscopy acquisition information, and polyp histopathological information are also included in each video. With its unprecedented size, quality, and heterogeneity, the REAL-Colon dataset is a unique resource for researchers and developers aiming to advance AI research in colonoscopy. Its openness and transparency facilitate rigorous and reproducible research, fostering the development and benchmarking of more accurate and reliable colonoscopy-related algorithms and models.
Many-shot from Low-shot: Learning to Annotate using Mixed Supervision for Object Detection
Aug 26, 2020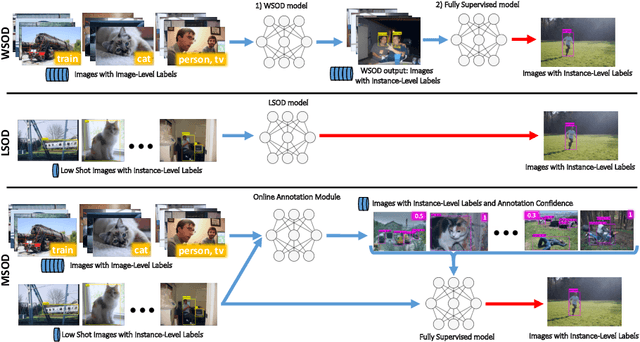
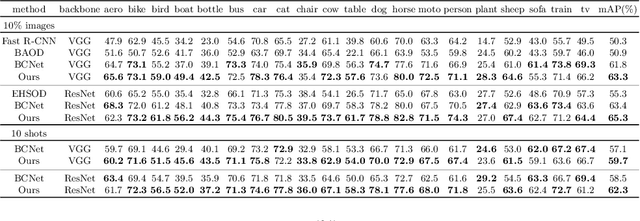
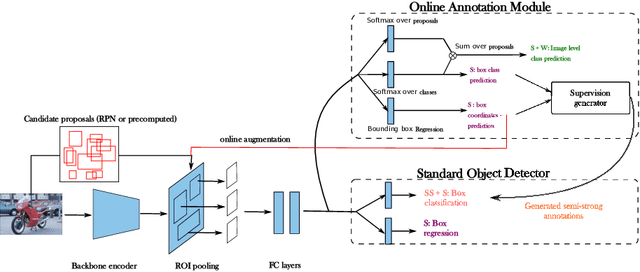
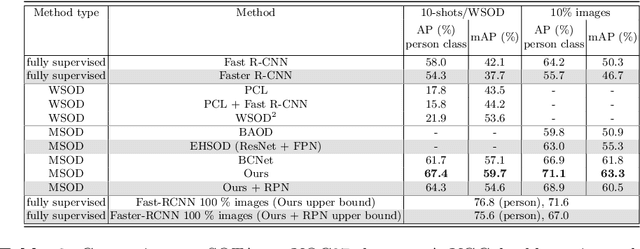
Object detection has witnessed significant progress by relying on large, manually annotated datasets. Annotating such datasets is highly time consuming and expensive, which motivates the development of weakly supervised and few-shot object detection methods. However, these methods largely underperform with respect to their strongly supervised counterpart, as weak training signals \emph{often} result in partial or oversized detections. Towards solving this problem we introduce, for the first time, an online annotation module (OAM) that learns to generate a many-shot set of \emph{reliable} annotations from a larger volume of weakly labelled images. Our OAM can be jointly trained with any fully supervised two-stage object detection method, providing additional training annotations on the fly. This results in a fully end-to-end strategy that only requires a low-shot set of fully annotated images. The integration of the OAM with Fast(er) R-CNN improves their performance by $17\%$ mAP, $9\%$ AP50 on PASCAL VOC 2007 and MS-COCO benchmarks, and significantly outperforms competing methods using mixed supervision.
Self-Supervision with Superpixels: Training Few-shot Medical Image Segmentation without Annotation
Jul 20, 2020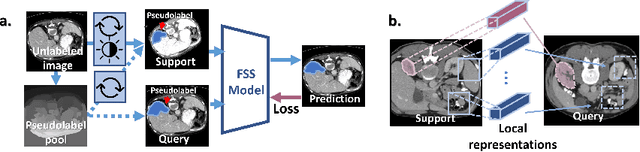
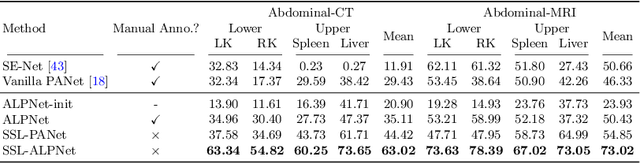
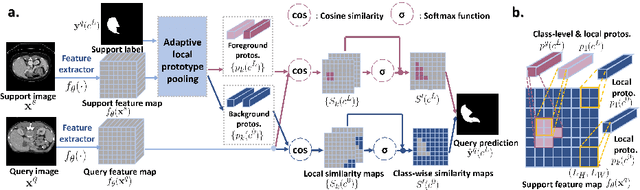
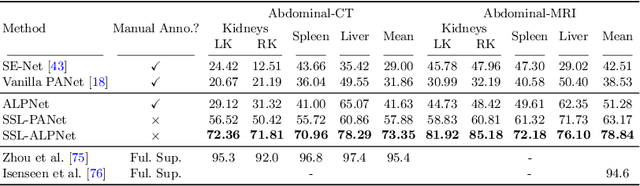
Few-shot semantic segmentation (FSS) has great potential for medical imaging applications. Most of the existing FSS techniques require abundant annotated semantic classes for training. However, these methods may not be applicable for medical images due to the lack of annotations. To address this problem we make several contributions: (1) A novel self-supervised FSS framework for medical images in order to eliminate the requirement for annotations during training. Additionally, superpixel-based pseudo-labels are generated to provide supervision; (2) An adaptive local prototype pooling module plugged into prototypical networks, to solve the common challenging foreground-background imbalance problem in medical image segmentation; (3) We demonstrate the general applicability of the proposed approach for medical images using three different tasks: abdominal organ segmentation for CT and MRI, as well as cardiac segmentation for MRI. Our results show that, for medical image segmentation, the proposed method outperforms conventional FSS methods which require manual annotations for training.
Data Efficient Unsupervised Domain Adaptation for Cross-Modality Image Segmentation
Aug 12, 2019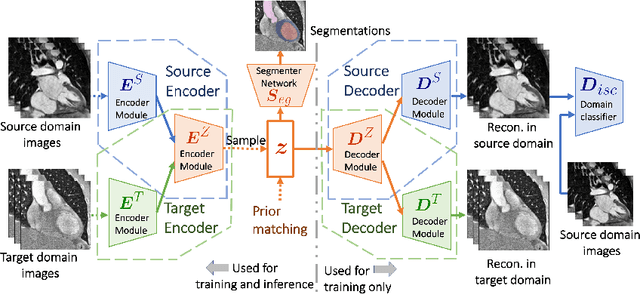


Deep learning models trained on medical images from a source domain (e.g. imaging modality) often fail when deployed on images from a different target domain, despite imaging common anatomical structures. Deep unsupervised domain adaptation (UDA) aims to improve the performance of a deep neural network model on a target domain, using solely unlabelled target domain data and labelled source domain data. However, current state-of-the-art methods exhibit reduced performance when target data is scarce. In this work, we introduce a new data efficient UDA method for multi-domain medical image segmentation. The proposed method combines a novel VAE-based feature prior matching, which is data-efficient, and domain adversarial training to learn a shared domain-invariant latent space which is exploited during segmentation. Our method is evaluated on a public multi-modality cardiac image segmentation dataset by adapting from the labelled source domain (3D MRI) to the unlabelled target domain (3D CT). We show that by using only one single unlabelled 3D CT scan, the proposed architecture outperforms the state-of-the-art in the same setting. Finally, we perform ablation studies on prior matching and domain adversarial training to shed light on the theoretical grounding of the proposed method.
Learning Shape Priors for Robust Cardiac MR Segmentation from Multi-view Images
Jul 23, 2019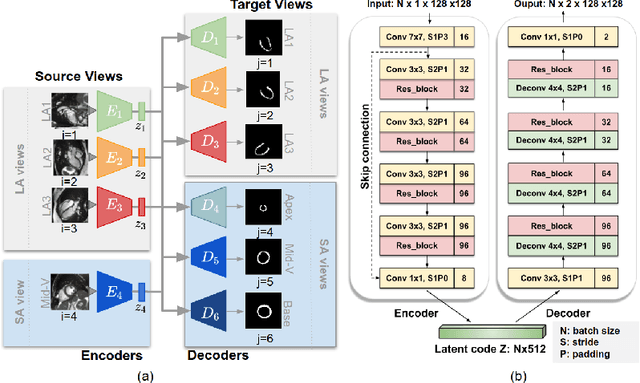
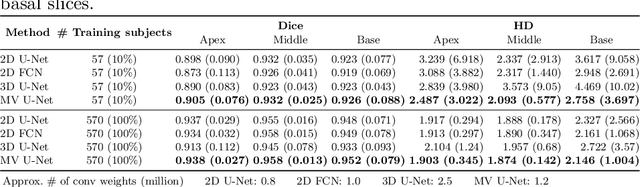
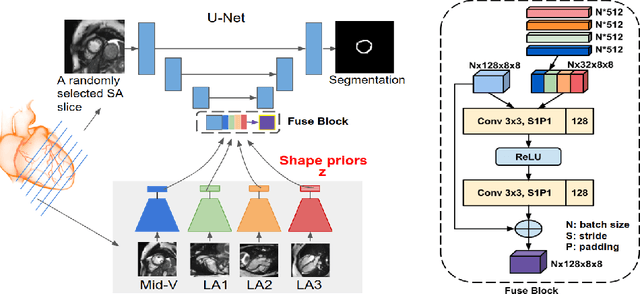
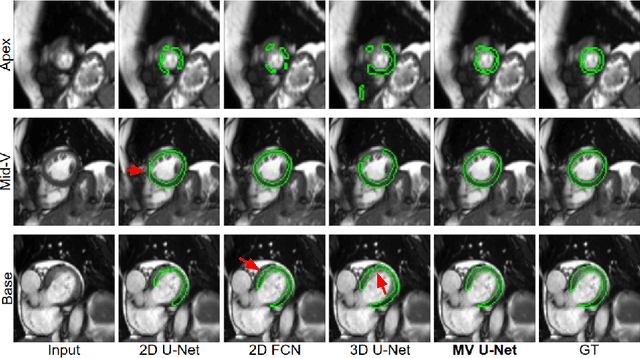
Cardiac MR image segmentation is essential for the morphological and functional analysis of the heart. Inspired by how experienced clinicians assess the cardiac morphology and function across multiple standard views (i.e. long- and short-axis views), we propose a novel approach which learns anatomical shape priors across different 2D standard views and leverages these priors to segment the left ventricular (LV) myocardium from short-axis MR image stacks. The proposed segmentation method has the advantage of being a 2D network but at the same time incorporates spatial context from multiple, complementary views that span a 3D space. Our method achieves accurate and robust segmentation of the myocardium across different short-axis slices (from apex to base), outperforming baseline models (e.g. 2D U-Net, 3D U-Net) while achieving higher data efficiency. Compared to the 2D U-Net, the proposed method reduces the mean Hausdorff distance (mm) from 3.24 to 2.49 on the apical slices, from 2.34 to 2.09 on the middle slices and from 3.62 to 2.76 on the basal slices on the test set, when only 10% of the training data was used.
VS-Net: Variable splitting network for accelerated parallel MRI reconstruction
Jul 19, 2019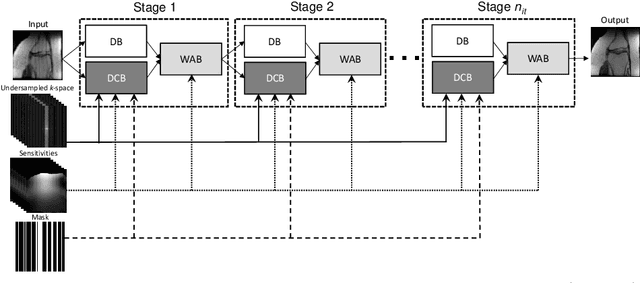
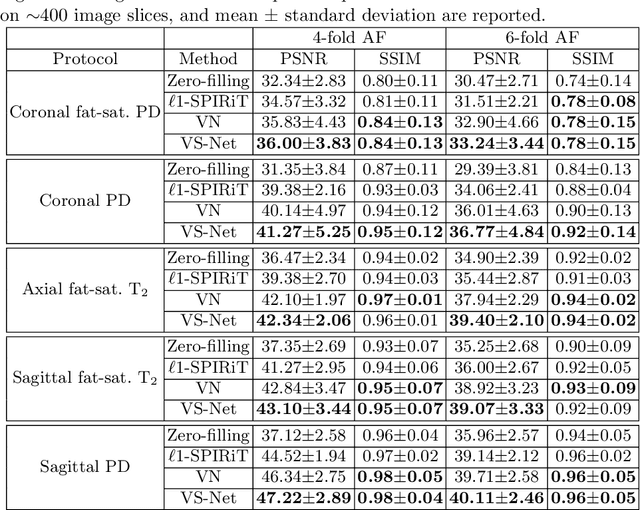

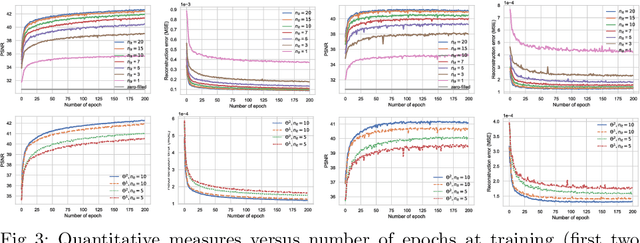
In this work, we propose a deep learning approach for parallel magnetic resonance imaging (MRI) reconstruction, termed a variable splitting network (VS-Net), for an efficient, high-quality reconstruction of undersampled multi-coil MR data. We formulate the generalized parallel compressed sensing reconstruction as an energy minimization problem, for which a variable splitting optimization method is derived. Based on this formulation we propose a novel, end-to-end trainable deep neural network architecture by unrolling the resulting iterative process of such variable splitting scheme. VS-Net is evaluated on complex valued multi-coil knee images for 4-fold and 6-fold acceleration factors. We show that VS-Net outperforms state-of-the-art deep learning reconstruction algorithms, in terms of reconstruction accuracy and perceptual quality. Our code is publicly available at https://github.com/j-duan/VS-Net.
Explainable Shape Analysis through Deep Hierarchical Generative Models: Application to Cardiac Remodeling
Jun 28, 2019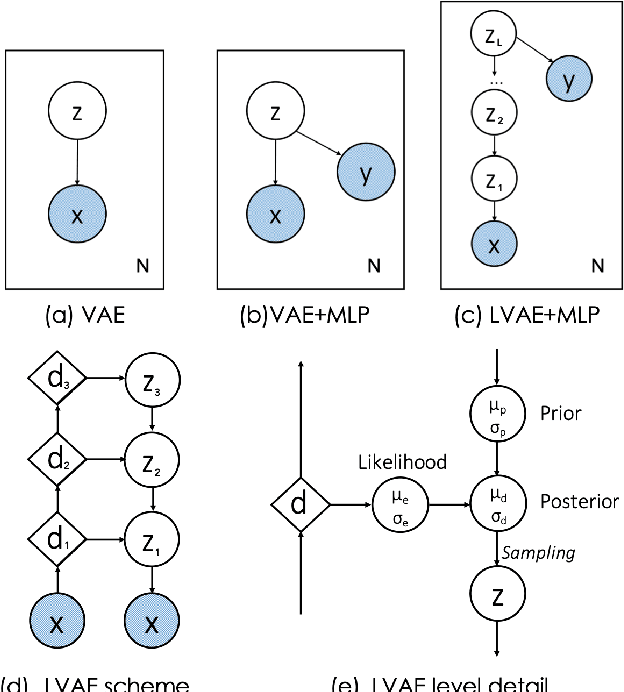
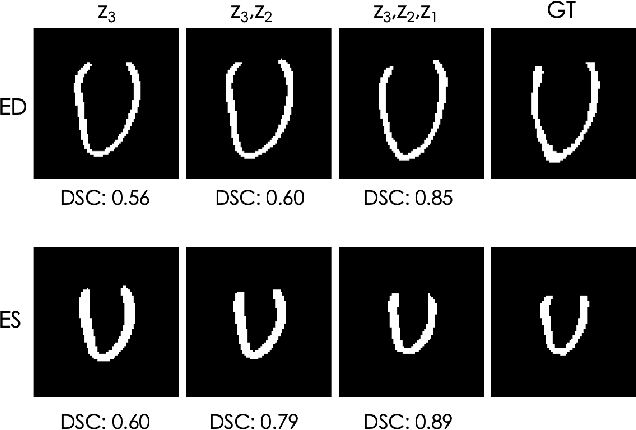


Quantification of anatomical shape changes still relies on scalar global indexes which are largely insensitive to regional or asymmetric modifications. Accurate assessment of pathology-driven anatomical remodeling is a crucial step for the diagnosis and treatment of heart conditions. Deep learning approaches have recently achieved wide success in the analysis of medical images, but they lack interpretability in the feature extraction and decision processes. In this work, we propose a new interpretable deep learning model for shape analysis. In particular, we exploit deep generative networks to model a population of anatomical segmentations through a hierarchy of conditional latent variables. At the highest level of this hierarchy, a two-dimensional latent space is simultaneously optimised to discriminate distinct clinical conditions, enabling the direct visualisation of the classification space. Moreover, the anatomical variability encoded by this discriminative latent space can be visualised in the segmentation space thanks to the generative properties of the model, making the classification task transparent. This approach yielded high accuracy in the categorisation of healthy and remodelled hearts when tested on unseen segmentations from our own multi-centre dataset as well as in an external validation set. More importantly, it enabled the visualisation in three-dimensions of the most discriminative anatomical features between the two conditions. The proposed approach scales effectively to large populations, facilitating high-throughput analysis of normal anatomy and pathology in large-scale studies of volumetric imaging.
3D High-Resolution Cardiac Segmentation Reconstruction from 2D Views using Conditional Variational Autoencoders
Feb 28, 2019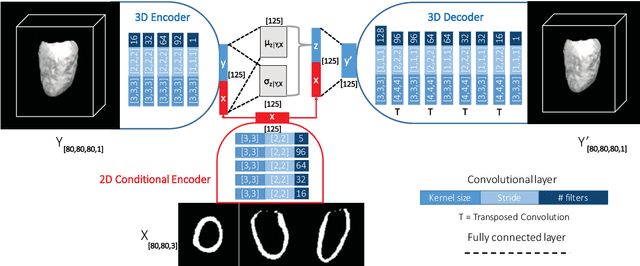


Accurate segmentation of heart structures imaged by cardiac MR is key for the quantitative analysis of pathology. High-resolution 3D MR sequences enable whole-heart structural imaging but are time-consuming, expensive to acquire and they often require long breath holds that are not suitable for patients. Consequently, multiplanar breath-hold 2D cine sequences are standard practice but are disadvantaged by lack of whole-heart coverage and low through-plane resolution. To address this, we propose a conditional variational autoencoder architecture able to learn a generative model of 3D high-resolution left ventricular (LV) segmentations which is conditioned on three 2D LV segmentations of one short-axis and two long-axis images. By only employing these three 2D segmentations, our model can efficiently reconstruct the 3D high-resolution LV segmentation of a subject. When evaluated on 400 unseen healthy volunteers, our model yielded an average Dice score of $87.92 \pm 0.15$ and outperformed competing architectures.