 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHeart: A Conditional Spatio-Temporal Generative Model for Cardiac Anatomy
Jan 30, 2023Two key questions in cardiac image analysis are to assess the anatomy and motion of the heart from images; and to understand how they are associated with non-imaging clinical factors such as gender, age and diseases. While the first question can often be addressed by image segmentation and motion tracking algorithms, our capability to model and to answer the second question is still limited. In this work, we propose a novel conditional generative model to describe the 4D spatio-temporal anatomy of the heart and its interaction with non-imaging clinical factors. The clinical factors are integrated as the conditions of the generative modelling, which allows us to investigate how these factors influence the cardiac anatomy. We evaluate the model performance in mainly two tasks, anatomical sequence completion and sequence generation. The model achieves a high performance in anatomical sequence completion, comparable to or outperforming other state-of-the-art generative models. In terms of sequence generation, given clinical conditions, the model can generate realistic synthetic 4D sequential anatomies that share similar distributions with the real data.
MulViMotion: Shape-aware 3D Myocardial Motion Tracking from Multi-View Cardiac MRI
Jul 29, 2022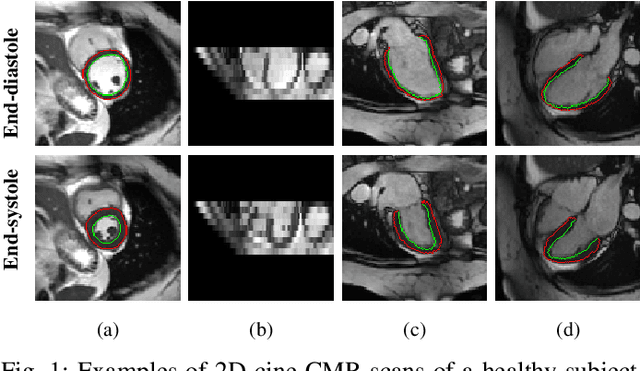
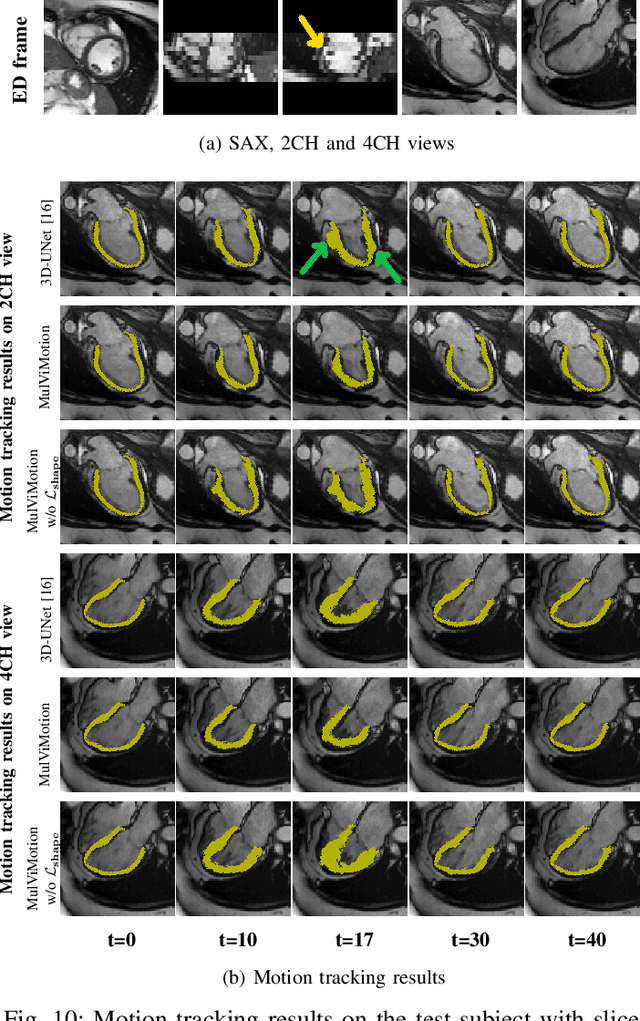
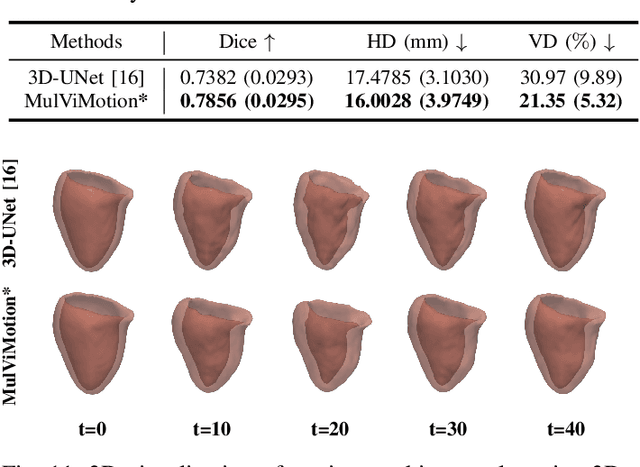
Recovering the 3D motion of the heart from cine cardiac magnetic resonance (CMR) imaging enables the assessment of regional myocardial function and is important for understanding and analyzing cardiovascular disease. However, 3D cardiac motion estimation is challenging because the acquired cine CMR images are usually 2D slices which limit the accurate estimation of through-plane motion. To address this problem, we propose a novel multi-view motion estimation network (MulViMotion), which integrates 2D cine CMR images acquired in short-axis and long-axis planes to learn a consistent 3D motion field of the heart. In the proposed method, a hybrid 2D/3D network is built to generate dense 3D motion fields by learning fused representations from multi-view images. To ensure that the motion estimation is consistent in 3D, a shape regularization module is introduced during training, where shape information from multi-view images is exploited to provide weak supervision to 3D motion estimation. We extensively evaluate the proposed method on 2D cine CMR images from 580 subjects of the UK Biobank study for 3D motion tracking of the left ventricular myocardium. Experimental results show that the proposed method quantitatively and qualitatively outperforms competing methods.
Nesterov Accelerated ADMM for Fast Diffeomorphic Image Registration
Sep 26, 2021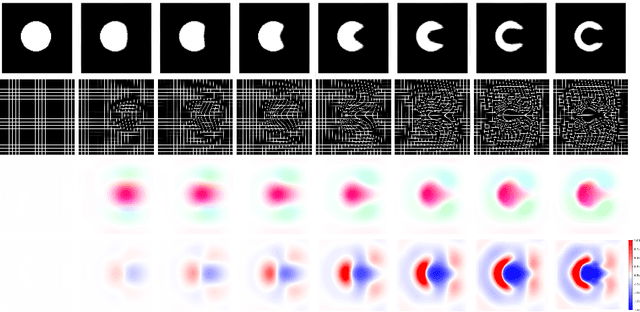
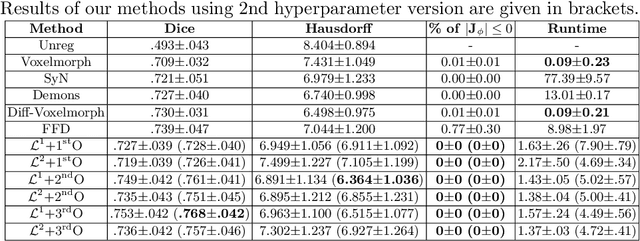
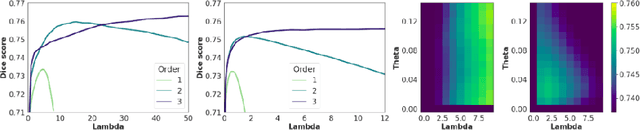
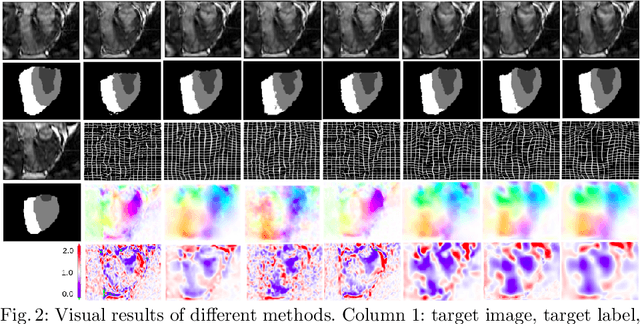
Deterministic approaches using iterative optimisation have been historically successful in diffeomorphic image registration (DiffIR). Although these approaches are highly accurate, they typically carry a significant computational burden. Recent developments in stochastic approaches based on deep learning have achieved sub-second runtimes for DiffIR with competitive registration accuracy, offering a fast alternative to conventional iterative methods. In this paper, we attempt to reduce this difference in speed whilst retaining the performance advantage of iterative approaches in DiffIR. We first propose a simple iterative scheme that functionally composes intermediate non-stationary velocity fields to handle large deformations in images whilst guaranteeing diffeomorphisms in the resultant deformation. We then propose a convex optimisation model that uses a regularisation term of arbitrary order to impose smoothness on these velocity fields and solve this model with a fast algorithm that combines Nesterov gradient descent and the alternating direction method of multipliers (ADMM). Finally, we leverage the computational power of GPU to implement this accelerated ADMM solver on a 3D cardiac MRI dataset, further reducing runtime to less than 2 seconds. In addition to producing strictly diffeomorphic deformations, our methods outperform both state-of-the-art deep learning-based and iterative DiffIR approaches in terms of dice and Hausdorff scores, with speed approaching the inference time of deep learning-based methods.
Joint Semi-supervised 3D Super-Resolution and Segmentation with Mixed Adversarial Gaussian Domain Adaptation
Jul 16, 2021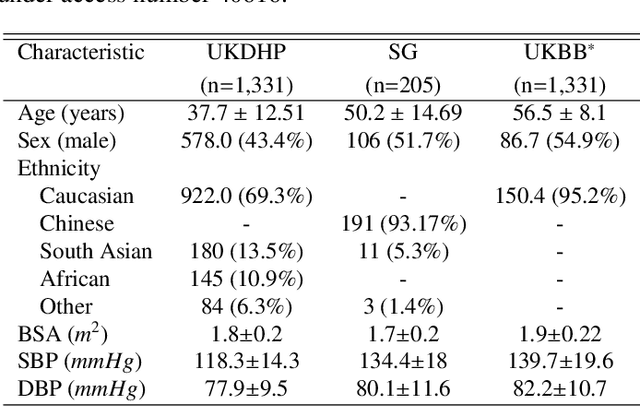
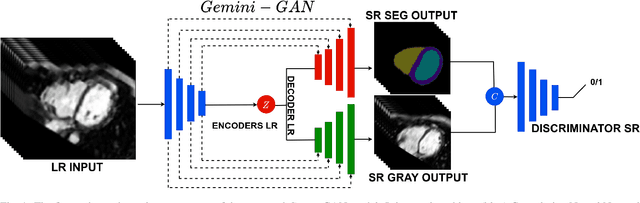
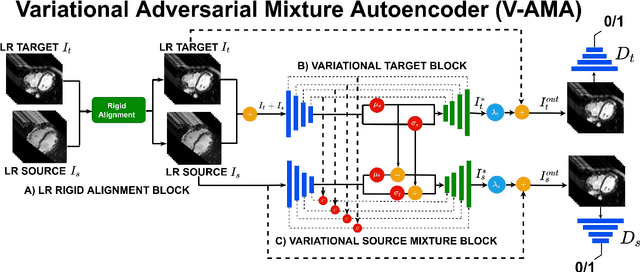

Optimising the analysis of cardiac structure and function requires accurate 3D representations of shape and motion. However, techniques such as cardiac magnetic resonance imaging are conventionally limited to acquiring contiguous cross-sectional slices with low through-plane resolution and potential inter-slice spatial misalignment. Super-resolution in medical imaging aims to increase the resolution of images but is conventionally trained on features from low resolution datasets and does not super-resolve corresponding segmentations. Here we propose a semi-supervised multi-task generative adversarial network (Gemini-GAN) that performs joint super-resolution of the images and their labels using a ground truth of high resolution 3D cines and segmentations, while an unsupervised variational adversarial mixture autoencoder (V-AMA) is used for continuous domain adaptation. Our proposed approach is extensively evaluated on two transnational multi-ethnic populations of 1,331 and 205 adults respectively, delivering an improvement on state of the art methods in terms of Dice index, peak signal to noise ratio, and structural similarity index measure. This framework also exceeds the performance of state of the art generative domain adaptation models on external validation (Dice index 0.81 vs 0.74 for the left ventricle). This demonstrates how joint super-resolution and segmentation, trained on 3D ground-truth data with cross-domain generalization, enables robust precision phenotyping in diverse populations.
Learning a Model-Driven Variational Network for Deformable Image Registration
May 25, 2021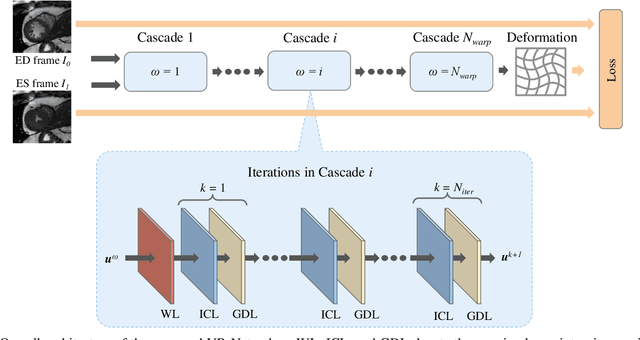
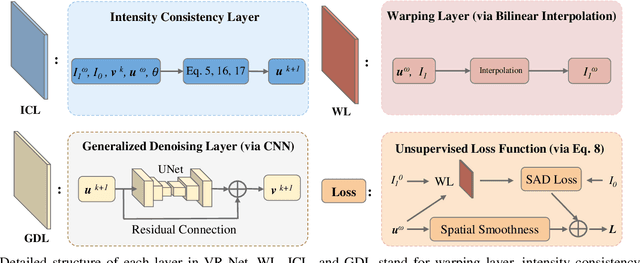
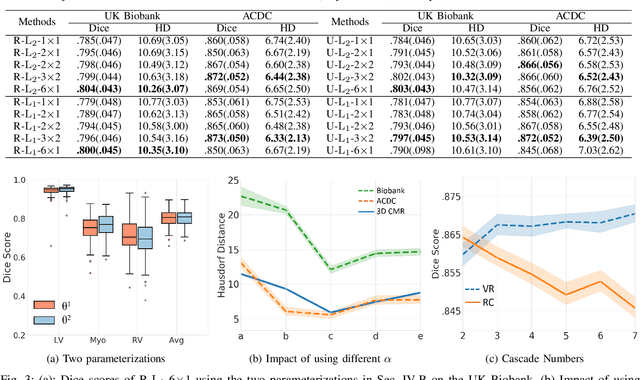
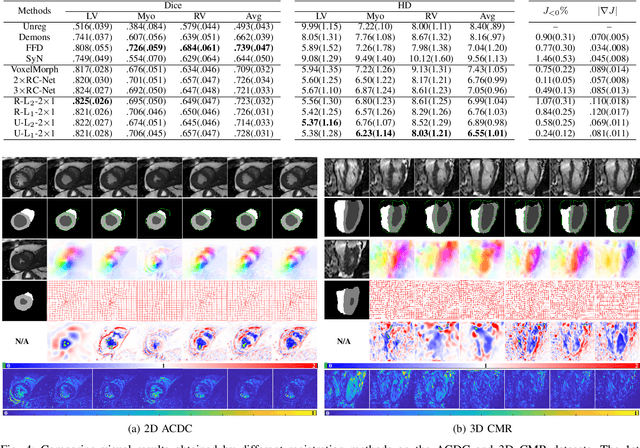
Data-driven deep learning approaches to image registration can be less accurate than conventional iterative approaches, especially when training data is limited. To address this whilst retaining the fast inference speed of deep learning, we propose VR-Net, a novel cascaded variational network for unsupervised deformable image registration. Using the variable splitting optimization scheme, we first convert the image registration problem, established in a generic variational framework, into two sub-problems, one with a point-wise, closed-form solution while the other one is a denoising problem. We then propose two neural layers (i.e. warping layer and intensity consistency layer) to model the analytical solution and a residual U-Net to formulate the denoising problem (i.e. generalized denoising layer). Finally, we cascade the warping layer, intensity consistency layer, and generalized denoising layer to form the VR-Net. Extensive experiments on three (two 2D and one 3D) cardiac magnetic resonance imaging datasets show that VR-Net outperforms state-of-the-art deep learning methods on registration accuracy, while maintains the fast inference speed of deep learning and the data-efficiency of variational model.
Joint analysis of clinical risk factors and 4D cardiac motion for survival prediction using a hybrid deep learning network
Oct 07, 2019
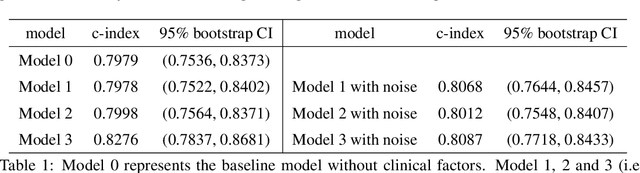
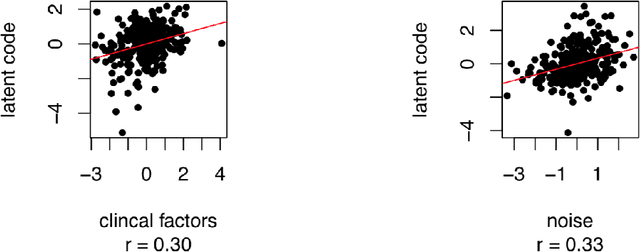

In this work, a novel approach is proposed for joint analysis of high dimensional time-resolved cardiac motion features obtained from segmented cardiac MRI and low dimensional clinical risk factors to improve survival prediction in heart failure. Different methods are evaluated to find the optimal way to insert conventional covariates into deep prediction networks. Correlation analysis between autoencoder latent codes and covariate features is used to examine how these predictors interact. We believe that similar approaches could also be used to introduce knowledge of genetic variants to such survival networks to improve outcome prediction by jointly analysing cardiac motion traits with inheritable risk factors.
* 4 pages, 2 figures
Explainable Shape Analysis through Deep Hierarchical Generative Models: Application to Cardiac Remodeling
Jun 28, 2019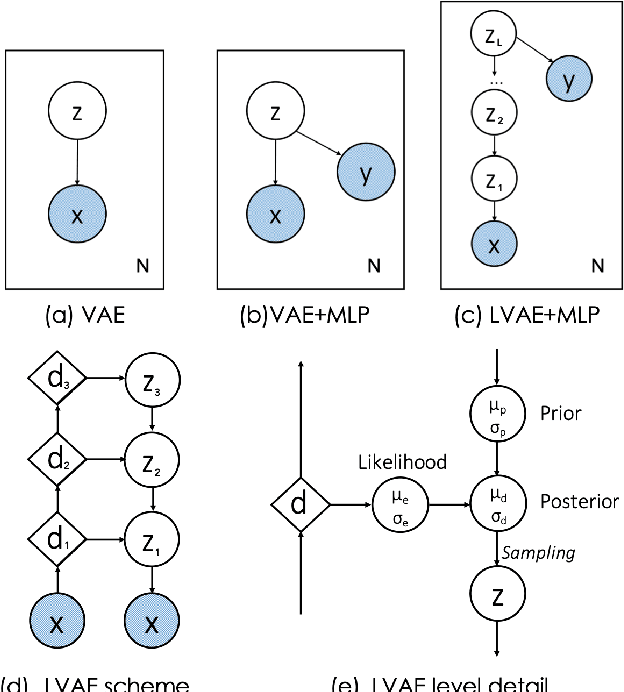
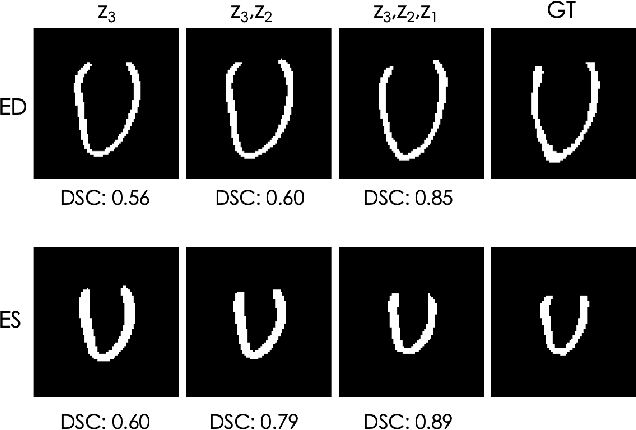


Quantification of anatomical shape changes still relies on scalar global indexes which are largely insensitive to regional or asymmetric modifications. Accurate assessment of pathology-driven anatomical remodeling is a crucial step for the diagnosis and treatment of heart conditions. Deep learning approaches have recently achieved wide success in the analysis of medical images, but they lack interpretability in the feature extraction and decision processes. In this work, we propose a new interpretable deep learning model for shape analysis. In particular, we exploit deep generative networks to model a population of anatomical segmentations through a hierarchy of conditional latent variables. At the highest level of this hierarchy, a two-dimensional latent space is simultaneously optimised to discriminate distinct clinical conditions, enabling the direct visualisation of the classification space. Moreover, the anatomical variability encoded by this discriminative latent space can be visualised in the segmentation space thanks to the generative properties of the model, making the classification task transparent. This approach yielded high accuracy in the categorisation of healthy and remodelled hearts when tested on unseen segmentations from our own multi-centre dataset as well as in an external validation set. More importantly, it enabled the visualisation in three-dimensions of the most discriminative anatomical features between the two conditions. The proposed approach scales effectively to large populations, facilitating high-throughput analysis of normal anatomy and pathology in large-scale studies of volumetric imaging.
3D High-Resolution Cardiac Segmentation Reconstruction from 2D Views using Conditional Variational Autoencoders
Feb 28, 2019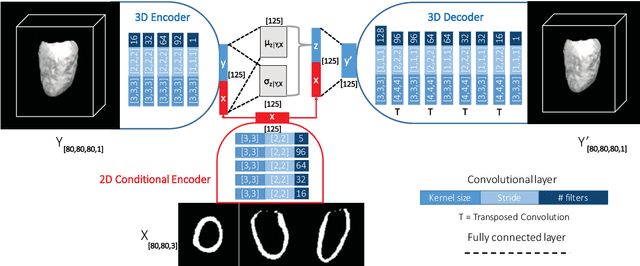


Accurate segmentation of heart structures imaged by cardiac MR is key for the quantitative analysis of pathology. High-resolution 3D MR sequences enable whole-heart structural imaging but are time-consuming, expensive to acquire and they often require long breath holds that are not suitable for patients. Consequently, multiplanar breath-hold 2D cine sequences are standard practice but are disadvantaged by lack of whole-heart coverage and low through-plane resolution. To address this, we propose a conditional variational autoencoder architecture able to learn a generative model of 3D high-resolution left ventricular (LV) segmentations which is conditioned on three 2D LV segmentations of one short-axis and two long-axis images. By only employing these three 2D segmentations, our model can efficiently reconstruct the 3D high-resolution LV segmentation of a subject. When evaluated on 400 unseen healthy volunteers, our model yielded an average Dice score of $87.92 \pm 0.15$ and outperformed competing architectures.
Deep learning cardiac motion analysis for human survival prediction
Oct 08, 2018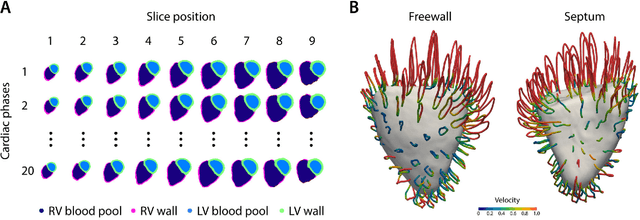


Motion analysis is used in computer vision to understand the behaviour of moving objects in sequences of images. Optimising the interpretation of dynamic biological systems requires accurate and precise motion tracking as well as efficient representations of high-dimensional motion trajectories so that these can be used for prediction tasks. Here we use image sequences of the heart, acquired using cardiac magnetic resonance imaging, to create time-resolved three-dimensional segmentations using a fully convolutional network trained on anatomical shape priors. This dense motion model formed the input to a supervised denoising autoencoder (4Dsurvival), which is a hybrid network consisting of an autoencoder that learns a task-specific latent code representation trained on observed outcome data, yielding a latent representation optimised for survival prediction. To handle right-censored survival outcomes, our network used a Cox partial likelihood loss function. In a study of 302 patients the predictive accuracy (quantified by Harrell's C-index) was significantly higher (p < .0001) for our model C=0.73 (95$\%$ CI: 0.68 - 0.78) than the human benchmark of C=0.59 (95$\%$ CI: 0.53 - 0.65). This work demonstrates how a complex computer vision task using high-dimensional medical image data can efficiently predict human survival.
A Comprehensive Approach for Learning-based Fully-Automated Inter-slice Motion Correction for Short-Axis Cine Cardiac MR Image Stacks
Oct 03, 2018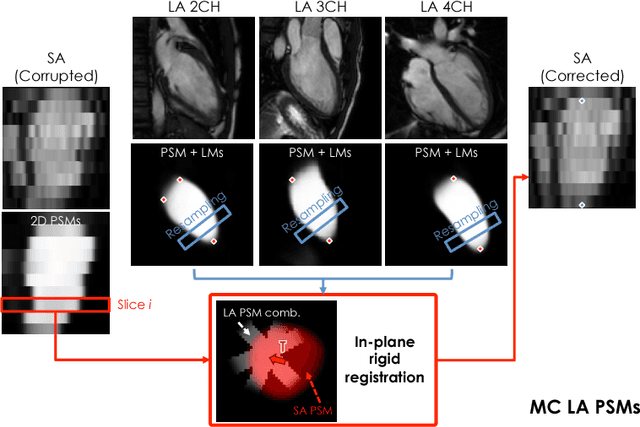
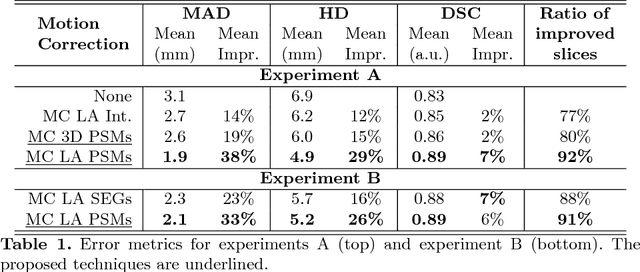
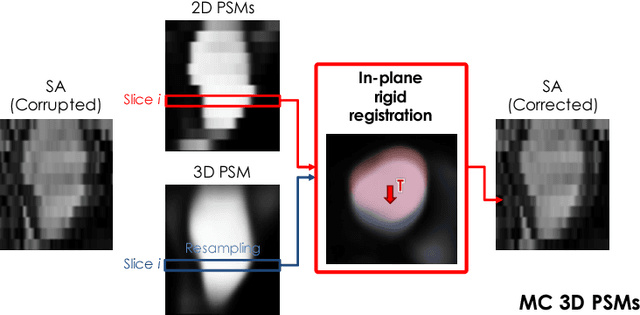
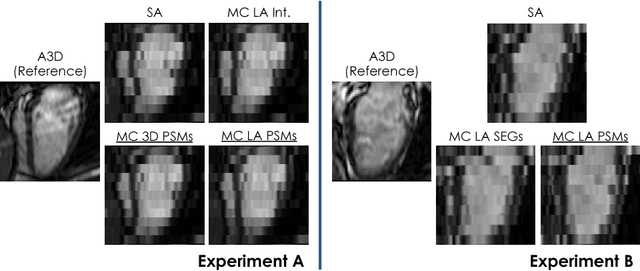
In the clinical routine, short axis (SA) cine cardiac MR (CMR) image stacks are acquired during multiple subsequent breath-holds. If the patient cannot consistently hold the breath at the same position, the acquired image stack will be affected by inter-slice respiratory motion and will not correctly represent the cardiac volume, introducing potential errors in the following analyses and visualisations. We propose an approach to automatically correct inter-slice respiratory motion in SA CMR image stacks. Our approach makes use of probabilistic segmentation maps (PSMs) of the left ventricular (LV) cavity generated with decision forests. PSMs are generated for each slice of the SA stack and rigidly registered in-plane to a target PSM. If long axis (LA) images are available, PSMs are generated for them and combined to create the target PSM; if not, the target PSM is produced from the same stack using a 3D model trained from motion-free stacks. The proposed approach was tested on a dataset of SA stacks acquired from 24 healthy subjects (for which anatomical 3D cardiac images were also available as reference) and compared to two techniques which use LA intensity images and LA segmentations as targets, respectively. The results show the accuracy and robustness of the proposed approach in motion compensation.