 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Kernel Power K-means: Scalable and Robust Clustering with Random Fourier Features and Possibilistic Method
Nov 13, 2025Kernel power $k$-means (KPKM) leverages a family of means to mitigate local minima issues in kernel $k$-means. However, KPKM faces two key limitations: (1) the computational burden of the full kernel matrix restricts its use on extensive data, and (2) the lack of authentic centroid-sample assignment learning reduces its noise robustness. To overcome these challenges, we propose RFF-KPKM, introducing the first approximation theory for applying random Fourier features (RFF) to KPKM. RFF-KPKM employs RFF to generate efficient, low-dimensional feature maps, bypassing the need for the whole kernel matrix. Crucially, we are the first to establish strong theoretical guarantees for this combination: (1) an excess risk bound of $\mathcal{O}(\sqrt{k^3/n})$, (2) strong consistency with membership values, and (3) a $(1+\varepsilon)$ relative error bound achievable using the RFF of dimension $\mathrm{poly}(\varepsilon^{-1}\log k)$. Furthermore, to improve robustness and the ability to learn multiple kernels, we propose IP-RFF-MKPKM, an improved possibilistic RFF-based multiple kernel power $k$-means. IP-RFF-MKPKM ensures the scalability of MKPKM via RFF and refines cluster assignments by combining the merits of the possibilistic membership and fuzzy membership. Experiments on large-scale datasets demonstrate the superior efficiency and clustering accuracy of the proposed methods compared to the state-of-the-art alternatives.
Generalized Deep Multi-view Clustering via Causal Learning with Partially Aligned Cross-view Correspondence
Sep 19, 2025Multi-view clustering (MVC) aims to explore the common clustering structure across multiple views. Many existing MVC methods heavily rely on the assumption of view consistency, where alignments for corresponding samples across different views are ordered in advance. However, real-world scenarios often present a challenge as only partial data is consistently aligned across different views, restricting the overall clustering performance. In this work, we consider the model performance decreasing phenomenon caused by data order shift (i.e., from fully to partially aligned) as a generalized multi-view clustering problem. To tackle this problem, we design a causal multi-view clustering network, termed CauMVC. We adopt a causal modeling approach to understand multi-view clustering procedure. To be specific, we formulate the partially aligned data as an intervention and multi-view clustering with partially aligned data as an post-intervention inference. However, obtaining invariant features directly can be challenging. Thus, we design a Variational Auto-Encoder for causal learning by incorporating an encoder from existing information to estimate the invariant features. Moreover, a decoder is designed to perform the post-intervention inference. Lastly, we design a contrastive regularizer to capture sample correlations. To the best of our knowledge, this paper is the first work to deal generalized multi-view clustering via causal learning. Empirical experiments on both fully and partially aligned data illustrate the strong generalization and effectiveness of CauMVC.
SMILENet: Unleashing Extra-Large Capacity Image Steganography via a Synergistic Mosaic InvertibLE Hiding Network
Mar 07, 2025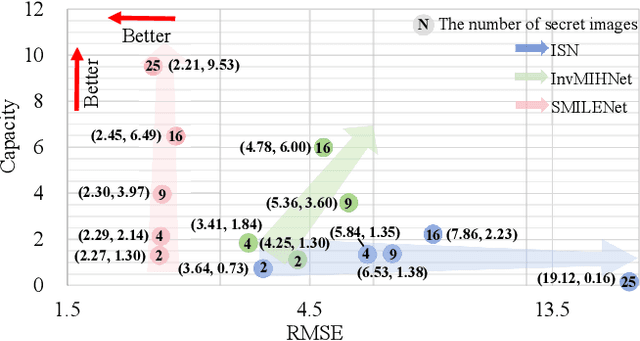
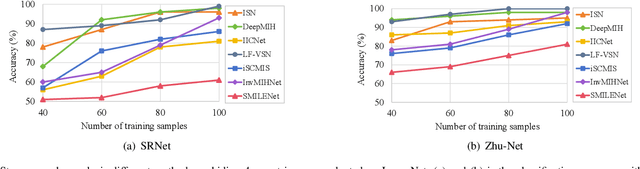

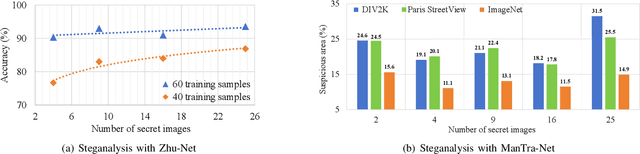
Existing image steganography methods face fundamental limitations in hiding capacity (typically $1\sim7$ images) due to severe information interference and uncoordinated capacity-distortion trade-off. We propose SMILENet, a novel synergistic framework that achieves 25 image hiding through three key innovations: (i) A synergistic network architecture coordinates reversible and non-reversible operations to efficiently exploit information redundancy in both secret and cover images. The reversible Invertible Cover-Driven Mosaic (ICDM) module and Invertible Mosaic Secret Embedding (IMSE) module establish cover-guided mosaic transformations and representation embedding with mathematically guaranteed invertibility for distortion-free embedding. The non-reversible Secret Information Selection (SIS) module and Secret Detail Enhancement (SDE) module implement learnable feature modulation for critical information selection and enhancement. (ii) A unified training strategy that coordinates complementary modules to achieve 3.0x higher capacity than existing methods with superior visual quality. (iii) Last but not least, we introduce a new metric to model Capacity-Distortion Trade-off for evaluating the image steganography algorithms that jointly considers hiding capacity and distortion, and provides a unified evaluation approach for accessing results with different number of secret image. Extensive experiments on DIV2K, Paris StreetView and ImageNet1K show that SMILENet outperforms state-of-the-art methods in terms of hiding capacity, recovery quality as well as security against steganalysis methods.
A Lightweight Deep Exclusion Unfolding Network for Single Image Reflection Removal
Mar 03, 2025Single Image Reflection Removal (SIRR) is a canonical blind source separation problem and refers to the issue of separating a reflection-contaminated image into a transmission and a reflection image. The core challenge lies in minimizing the commonalities among different sources. Existing deep learning approaches either neglect the significance of feature interactions or rely on heuristically designed architectures. In this paper, we propose a novel Deep Exclusion unfolding Network (DExNet), a lightweight, interpretable, and effective network architecture for SIRR. DExNet is principally constructed by unfolding and parameterizing a simple iterative Sparse and Auxiliary Feature Update (i-SAFU) algorithm, which is specifically designed to solve a new model-based SIRR optimization formulation incorporating a general exclusion prior. This general exclusion prior enables the unfolded SAFU module to inherently identify and penalize commonalities between the transmission and reflection features, ensuring more accurate separation. The principled design of DExNet not only enhances its interpretability but also significantly improves its performance. Comprehensive experiments on four benchmark datasets demonstrate that DExNet achieves state-of-the-art visual and quantitative results while utilizing only approximately 8\% of the parameters required by leading methods.
Web Archives Metadata Generation with GPT-4o: Challenges and Insights
Nov 08, 2024



Current metadata creation for web archives is time consuming and costly due to reliance on human effort. This paper explores the use of gpt-4o for metadata generation within the Web Archive Singapore, focusing on scalability, efficiency, and cost effectiveness. We processed 112 Web ARChive (WARC) files using data reduction techniques, achieving a notable 99.9% reduction in metadata generation costs. By prompt engineering, we generated titles and abstracts, which were evaluated both intrinsically using Levenshtein Distance and BERTScore, and extrinsically with human cataloguers using McNemar's test. Results indicate that while our method offers significant cost savings and efficiency gains, human curated metadata maintains an edge in quality. The study identifies key challenges including content inaccuracies, hallucinations, and translation issues, suggesting that Large Language Models (LLMs) should serve as complements rather than replacements for human cataloguers. Future work will focus on refining prompts, improving content filtering, and addressing privacy concerns through experimentation with smaller models. This research advances the integration of LLMs in web archiving, offering valuable insights into their current capabilities and outlining directions for future enhancements. The code is available at https://github.com/masamune-prog/warc2summary for further development and use by institutions facing similar challenges.
Rumor Detection with a novel graph neural network approach
Apr 02, 2024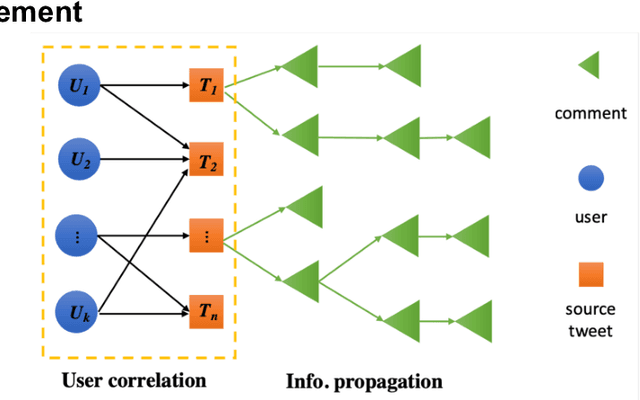
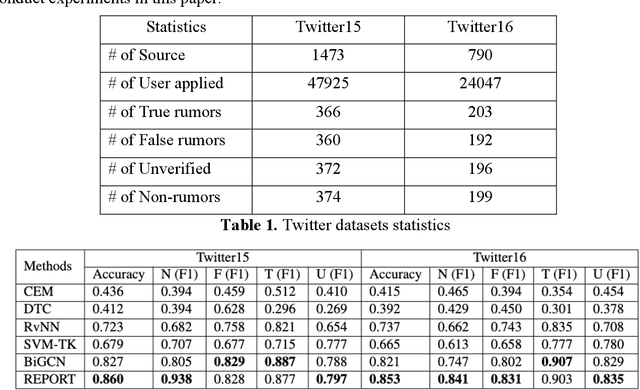

The wide spread of rumors on social media has caused a negative impact on people's daily life, leading to potential panic, fear, and mental health problems for the public. How to debunk rumors as early as possible remains a challenging problem. Existing studies mainly leverage information propagation structure to detect rumors, while very few works focus on correlation among users that they may coordinate to spread rumors in order to gain large popularity. In this paper, we propose a new detection model, that jointly learns both the representations of user correlation and information propagation to detect rumors on social media. Specifically, we leverage graph neural networks to learn the representations of user correlation from a bipartite graph that describes the correlations between users and source tweets, and the representations of information propagation with a tree structure. Then we combine the learned representations from these two modules to classify the rumors. Since malicious users intend to subvert our model after deployment, we further develop a greedy attack scheme to analyze the cost of three adversarial attacks: graph attack, comment attack, and joint attack. Evaluation results on two public datasets illustrate that the proposed MODEL outperforms the state-of-the-art rumor detection models. We also demonstrate our method performs well for early rumor detection. Moreover, the proposed detection method is more robust to adversarial attacks compared to the best existing method. Importantly, we show that it requires a high cost for attackers to subvert user correlation pattern, demonstrating the importance of considering user correlation for rumor detection.
Image Captioning in news report scenario
Apr 02, 2024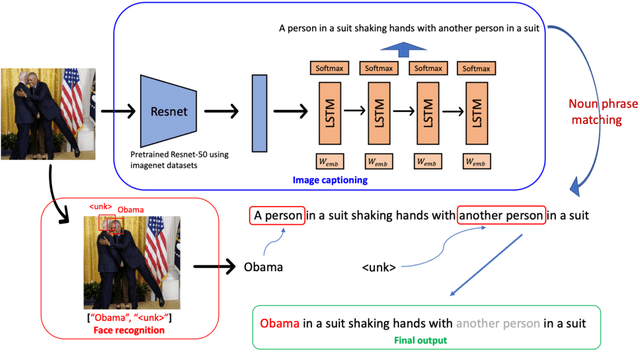
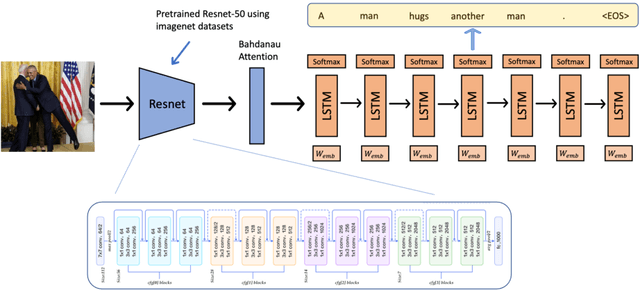


Image captioning strives to generate pertinent captions for specified images, situating itself at the crossroads of Computer Vision (CV) and Natural Language Processing (NLP). This endeavor is of paramount importance with far-reaching applications in recommendation systems, news outlets, social media, and beyond. Particularly within the realm of news reporting, captions are expected to encompass detailed information, such as the identities of celebrities captured in the images. However, much of the existing body of work primarily centers around understanding scenes and actions. In this paper, we explore the realm of image captioning specifically tailored for celebrity photographs, illustrating its broad potential for enhancing news industry practices. This exploration aims to augment automated news content generation, thereby facilitating a more nuanced dissemination of information. Our endeavor shows a broader horizon, enriching the narrative in news reporting through a more intuitive image captioning framework.
News Recommendation with Attention Mechanism
Feb 20, 2024This paper explores the area of news recommendation, a key component of online information sharing. Initially, we provide a clear introduction to news recommendation, defining the core problem and summarizing current methods and notable recent algorithms. We then present our work on implementing the NRAM (News Recommendation with Attention Mechanism), an attention-based approach for news recommendation, and assess its effectiveness. Our evaluation shows that NRAM has the potential to significantly improve how news content is personalized for users on digital news platforms.
* 7 pages, Journal of Industrial Engineering and Applied Science
Particle Filter SLAM for Vehicle Localization
Feb 20, 2024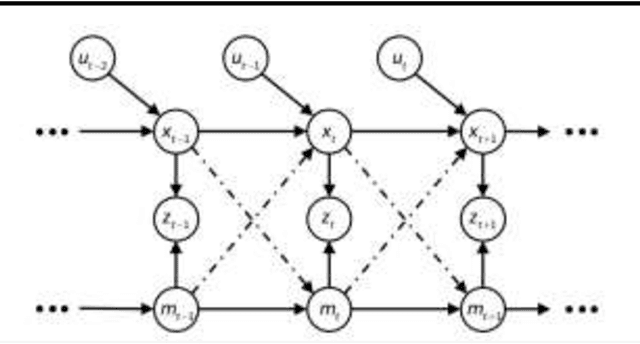
Simultaneous Localization and Mapping (SLAM) presents a formidable challenge in robotics, involving the dynamic construction of a map while concurrently determining the precise location of the robotic agent within an unfamiliar environment. This intricate task is further compounded by the inherent "chicken-and-egg" dilemma, where accurate mapping relies on a dependable estimation of the robot's location, and vice versa. Moreover, the computational intensity of SLAM adds an additional layer of complexity, making it a crucial yet demanding topic in the field. In our research, we address the challenges of SLAM by adopting the Particle Filter SLAM method. Our approach leverages encoded data and fiber optic gyro (FOG) information to enable precise estimation of vehicle motion, while lidar technology contributes to environmental perception by providing detailed insights into surrounding obstacles. The integration of these data streams culminates in the establishment of a Particle Filter SLAM framework, representing a key endeavor in this paper to effectively navigate and overcome the complexities associated with simultaneous localization and mapping in robotic systems.
* 6 pages, Journal of Industrial Engineering and Applied Science
Mesh-based 3D Motion Tracking in Cardiac MRI using Deep Learning
Sep 05, 2022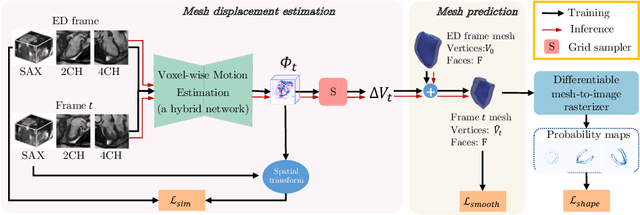
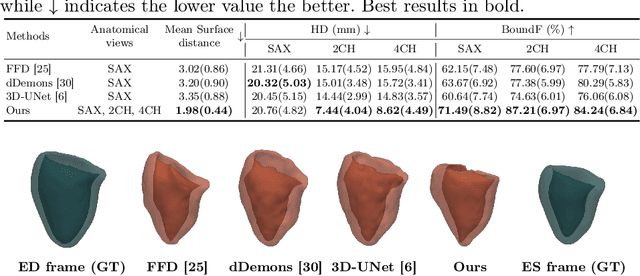
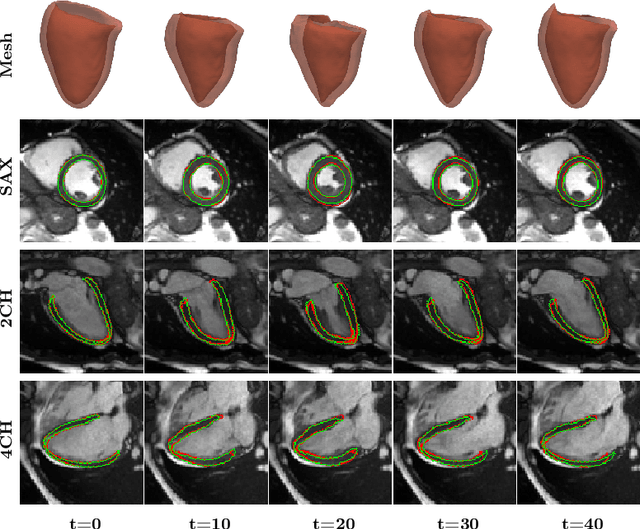

3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and diagnosis of cardiovascular diseases. Most of the previous methods focus on estimating pixel-/voxel-wise motion fields in the full image space, which ignore the fact that motion estimation is mainly relevant and useful within the object of interest, e.g., the heart. In this work, we model the heart as a 3D geometric mesh and propose a novel deep learning-based method that can estimate 3D motion of the heart mesh from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, the method is able to leverage the anatomical shape information from 2D multi-view CMR images for 3D motion estimation. The differentiability of the rasterizer enables us to train the method end-to-end. One advantage of the proposed method is that by tracking the motion of each vertex, it is able to keep the vertex correspondence of 3D meshes between time frames, which is important for quantitative assessment of the cardiac function on the mesh. We evaluate the proposed method on CMR images acquired from the UK Biobank study. Experimental results show that the proposed method quantitatively and qualitatively outperforms both conventional and learning-based cardiac motion tracking methods.