 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Archives Metadata Generation with GPT-4o: Challenges and Insights
Nov 08, 2024



Current metadata creation for web archives is time consuming and costly due to reliance on human effort. This paper explores the use of gpt-4o for metadata generation within the Web Archive Singapore, focusing on scalability, efficiency, and cost effectiveness. We processed 112 Web ARChive (WARC) files using data reduction techniques, achieving a notable 99.9% reduction in metadata generation costs. By prompt engineering, we generated titles and abstracts, which were evaluated both intrinsically using Levenshtein Distance and BERTScore, and extrinsically with human cataloguers using McNemar's test. Results indicate that while our method offers significant cost savings and efficiency gains, human curated metadata maintains an edge in quality. The study identifies key challenges including content inaccuracies, hallucinations, and translation issues, suggesting that Large Language Models (LLMs) should serve as complements rather than replacements for human cataloguers. Future work will focus on refining prompts, improving content filtering, and addressing privacy concerns through experimentation with smaller models. This research advances the integration of LLMs in web archiving, offering valuable insights into their current capabilities and outlining directions for future enhancements. The code is available at https://github.com/masamune-prog/warc2summary for further development and use by institutions facing similar challenges.
GraphVL: Graph-Enhanced Semantic Modeling via Vision-Language Models for Generalized Class Discovery
Nov 04, 2024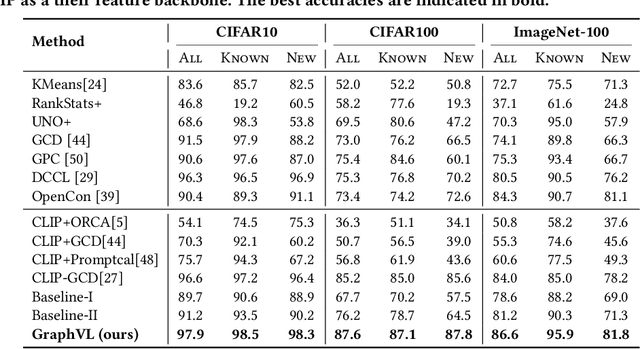



Generalized Category Discovery (GCD) aims to cluster unlabeled images into known and novel categories using labeled images from known classes. To address the challenge of transferring features from known to unknown classes while mitigating model bias, we introduce GraphVL, a novel approach for vision-language modeling in GCD, leveraging CLIP. Our method integrates a graph convolutional network (GCN) with CLIP's text encoder to preserve class neighborhood structure. We also employ a lightweight visual projector for image data, ensuring discriminative features through margin-based contrastive losses for image-text mapping. This neighborhood preservation criterion effectively regulates the semantic space, making it less sensitive to known classes. Additionally, we learn textual prompts from known classes and align them to create a more contextually meaningful semantic feature space for the GCN layer using a contextual similarity loss. Finally, we represent unlabeled samples based on their semantic distance to class prompts from the GCN, enabling semi-supervised clustering for class discovery and minimizing errors. Our experiments on seven benchmark datasets consistently demonstrate the superiority of GraphVL when integrated with the CLIP backbone.
Unknown Prompt, the only Lacuna: Unveiling CLIP's Potential for Open Domain Generalization
Mar 31, 2024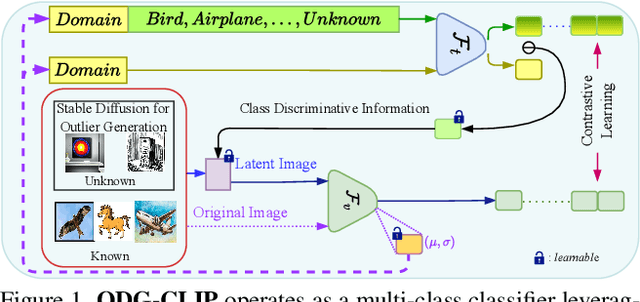
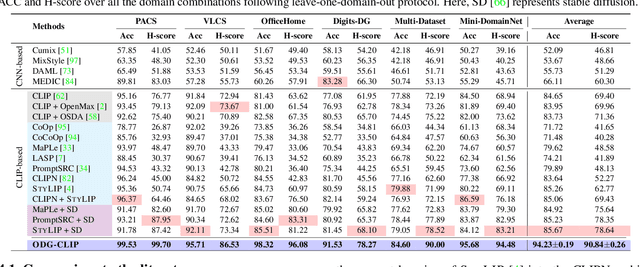
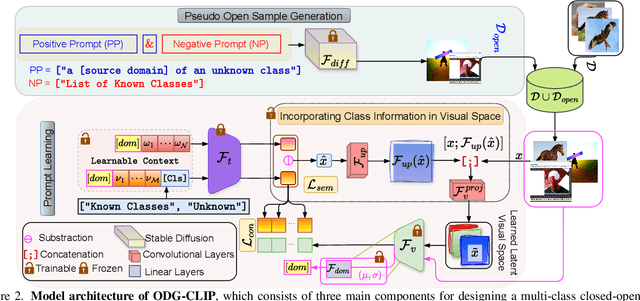
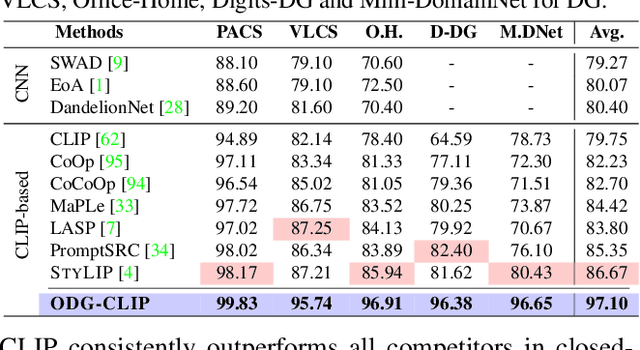
We delve into Open Domain Generalization (ODG), marked by domain and category shifts between training's labeled source and testing's unlabeled target domains. Existing solutions to ODG face limitations due to constrained generalizations of traditional CNN backbones and errors in detecting target open samples in the absence of prior knowledge. Addressing these pitfalls, we introduce ODG-CLIP, harnessing the semantic prowess of the vision-language model, CLIP. Our framework brings forth three primary innovations: Firstly, distinct from prevailing paradigms, we conceptualize ODG as a multi-class classification challenge encompassing both known and novel categories. Central to our approach is modeling a unique prompt tailored for detecting unknown class samples, and to train this, we employ a readily accessible stable diffusion model, elegantly generating proxy images for the open class. Secondly, aiming for domain-tailored classification (prompt) weights while ensuring a balance of precision and simplicity, we devise a novel visual stylecentric prompt learning mechanism. Finally, we infuse images with class-discriminative knowledge derived from the prompt space to augment the fidelity of CLIP's visual embeddings. We introduce a novel objective to safeguard the continuity of this infused semantic intel across domains, especially for the shared classes. Through rigorous testing on diverse datasets, covering closed and open-set DG contexts, ODG-CLIP demonstrates clear supremacy, consistently outpacing peers with performance boosts between 8%-16%. Code will be available at https://github.com/mainaksingha01/ODG-CLIP.
Inclusive Design: Accessibility Settings for People with Cognitive Disabilities
Oct 12, 2021
The advancement of technology has progressed faster than any other field in the world and with the development of these new technologies, it is important to make sure that these tools can be used by everyone, including people with disabilities. Accessibility options in computing devices help ensure that everyone has the same access to advanced technologies. Unfortunately, for those who require more unique and sometimes challenging accommodations, such as people with Amyotrophic lateral sclerosis ( ALS), the most commonly used accessibility features are simply not enough. While assistive technology for those with ALS does exist, it requires multiple peripheral devices that can become quite expensive collectively. The purpose of this paper is to suggest a more affordable and readily available option for ALS assistive technology that can be implemented on a smartphone or tablet.