 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphVL: Graph-Enhanced Semantic Modeling via Vision-Language Models for Generalized Class Discovery
Paper and Code
Nov 04, 2024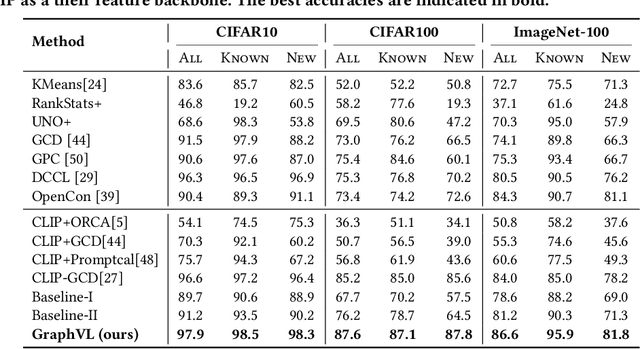



Generalized Category Discovery (GCD) aims to cluster unlabeled images into known and novel categories using labeled images from known classes. To address the challenge of transferring features from known to unknown classes while mitigating model bias, we introduce GraphVL, a novel approach for vision-language modeling in GCD, leveraging CLIP. Our method integrates a graph convolutional network (GCN) with CLIP's text encoder to preserve class neighborhood structure. We also employ a lightweight visual projector for image data, ensuring discriminative features through margin-based contrastive losses for image-text mapping. This neighborhood preservation criterion effectively regulates the semantic space, making it less sensitive to known classes. Additionally, we learn textual prompts from known classes and align them to create a more contextually meaningful semantic feature space for the GCN layer using a contextual similarity loss. Finally, we represent unlabeled samples based on their semantic distance to class prompts from the GCN, enabling semi-supervised clustering for class discovery and minimizing errors. Our experiments on seven benchmark datasets consistently demonstrate the superiority of GraphVL when integrated with the CLIP backbone.