 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOncoReg: Medical Image Registration for Oncological Challenges
Apr 01, 2025In modern cancer research, the vast volume of medical data generated is often underutilised due to challenges related to patient privacy. The OncoReg Challenge addresses this issue by enabling researchers to develop and validate image registration methods through a two-phase framework that ensures patient privacy while fostering the development of more generalisable AI models. Phase one involves working with a publicly available dataset, while phase two focuses on training models on a private dataset within secure hospital networks. OncoReg builds upon the foundation established by the Learn2Reg Challenge by incorporating the registration of interventional cone-beam computed tomography (CBCT) with standard planning fan-beam CT (FBCT) images in radiotherapy. Accurate image registration is crucial in oncology, particularly for dynamic treatment adjustments in image-guided radiotherapy, where precise alignment is necessary to minimise radiation exposure to healthy tissues while effectively targeting tumours. This work details the methodology and data behind the OncoReg Challenge and provides a comprehensive analysis of the competition entries and results. Findings reveal that feature extraction plays a pivotal role in this registration task. A new method emerging from this challenge demonstrated its versatility, while established approaches continue to perform comparably to newer techniques. Both deep learning and classical approaches still play significant roles in image registration, with the combination of methods - particularly in feature extraction - proving most effective.
WiNet: Wavelet-based Incremental Learning for Efficient Medical Image Registration
Jul 18, 2024Deep image registration has demonstrated exceptional accuracy and fast inference. Recent advances have adopted either multiple cascades or pyramid architectures to estimate dense deformation fields in a coarse-to-fine manner. However, due to the cascaded nature and repeated composition/warping operations on feature maps, these methods negatively increase memory usage during training and testing. Moreover, such approaches lack explicit constraints on the learning process of small deformations at different scales, thus lacking explainability. In this study, we introduce a model-driven WiNet that incrementally estimates scale-wise wavelet coefficients for the displacement/velocity field across various scales, utilizing the wavelet coefficients derived from the original input image pair. By exploiting the properties of the wavelet transform, these estimated coefficients facilitate the seamless reconstruction of a full-resolution displacement/velocity field via our devised inverse discrete wavelet transform (IDWT) layer. This approach avoids the complexities of cascading networks or composition operations, making our WiNet an explainable and efficient competitor with other coarse-to-fine methods. Extensive experimental results from two 3D datasets show that our WiNet is accurate and GPU efficient. The code is available at https://github.com/x-xc/WiNet .
EPL: Empirical Prototype Learning for Deep Face Recognition
May 21, 2024Prototype learning is widely used in face recognition, which takes the row vectors of coefficient matrix in the last linear layer of the feature extraction model as the prototypes for each class. When the prototypes are updated using the facial sample feature gradients in the model training, they are prone to being pulled away from the class center by the hard samples, resulting in decreased overall model performance. In this paper, we explicitly define prototypes as the expectations of sample features in each class and design the empirical prototypes using the existing samples in the dataset. We then devise a strategy to adaptively update these empirical prototypes during the model training based on the similarity between the sample features and the empirical prototypes. Furthermore, we propose an empirical prototype learning (EPL) method, which utilizes an adaptive margin parameter with respect to sample features. EPL assigns larger margins to the normal samples and smaller margins to the hard samples, allowing the learned empirical prototypes to better reflect the class center dominated by the normal samples and finally pull the hard samples towards the empirical prototypes through the learning. The extensive experiments on MFR, IJB-C, LFW, CFP-FP, AgeDB, and MegaFace demonstrate the effectiveness of EPL. Our code is available at $\href{https://github.com/WakingHours-GitHub/EPL}{https://github.com/WakingHours-GitHub/EPL}$.
Rediscovering BCE Loss for Uniform Classification
Mar 12, 2024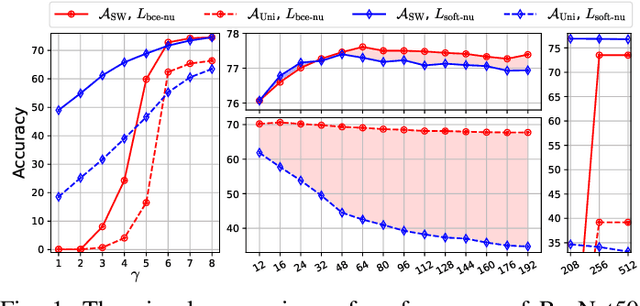
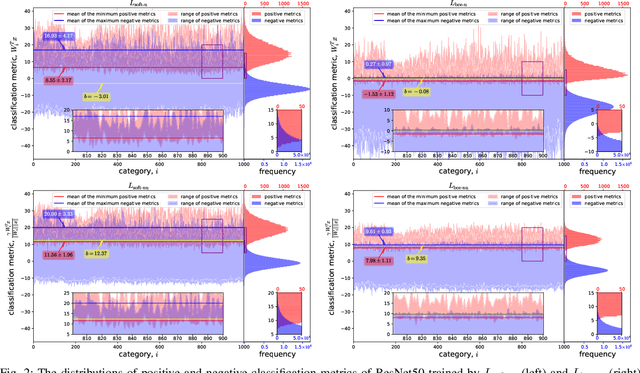

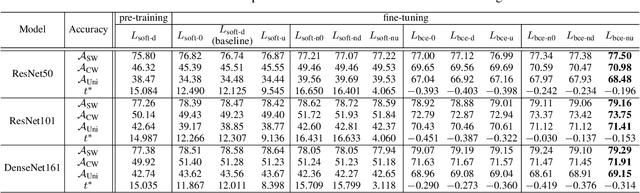
This paper introduces the concept of uniform classification, which employs a unified threshold to classify all samples rather than adaptive threshold classifying each individual sample. We also propose the uniform classification accuracy as a metric to measure the model's performance in uniform classification. Furthermore, begin with a naive loss, we mathematically derive a loss function suitable for the uniform classification, which is the BCE function integrated with a unified bias. We demonstrate the unified threshold could be learned via the bias. The extensive experiments on six classification datasets and three feature extraction models show that, compared to the SoftMax loss, the models trained with the BCE loss not only exhibit higher uniform classification accuracy but also higher sample-wise classification accuracy. In addition, the learned bias from BCE loss is very close to the unified threshold used in the uniform classification. The features extracted by the models trained with BCE loss not only possess uniformity but also demonstrate better intra-class compactness and inter-class distinctiveness, yielding superior performance on open-set tasks such as face recognition.
Decoder-Only Image Registration
Feb 05, 2024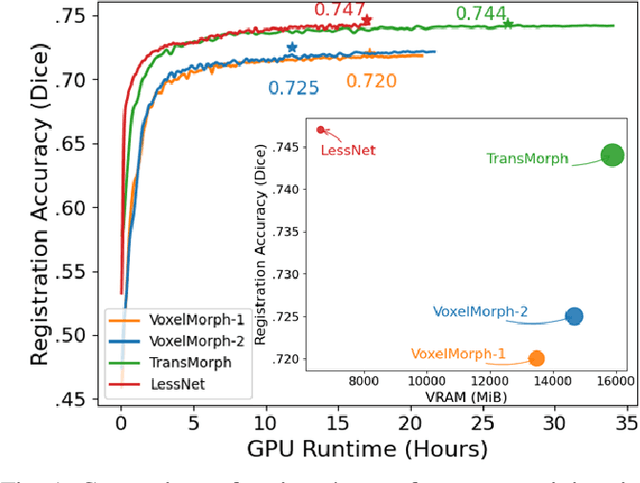
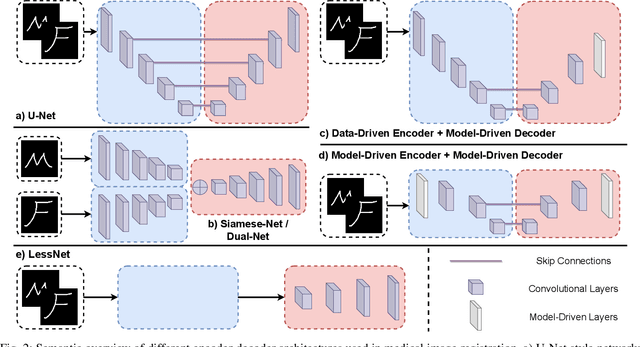
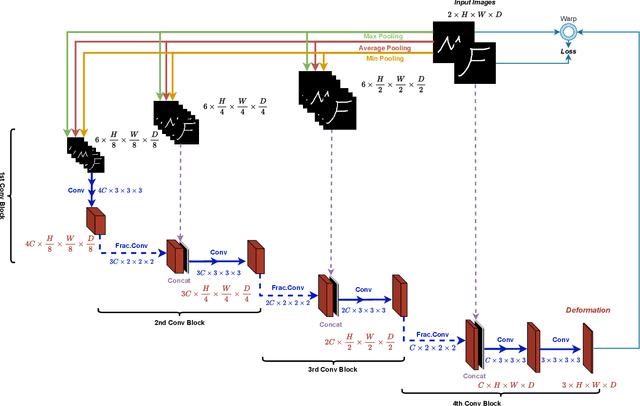
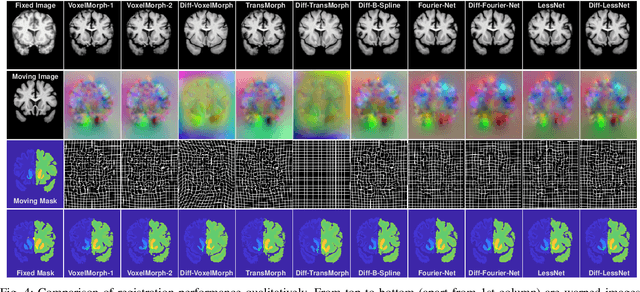
In unsupervised medical image registration, the predominant approaches involve the utilization of a encoder-decoder network architecture, allowing for precise prediction of dense, full-resolution displacement fields from given paired images. Despite its widespread use in the literature, we argue for the necessity of making both the encoder and decoder learnable in such an architecture. For this, we propose a novel network architecture, termed LessNet in this paper, which contains only a learnable decoder, while entirely omitting the utilization of a learnable encoder. LessNet substitutes the learnable encoder with simple, handcrafted features, eliminating the need to learn (optimize) network parameters in the encoder altogether. Consequently, this leads to a compact, efficient, and decoder-only architecture for 3D medical image registration. Evaluated on two publicly available brain MRI datasets, we demonstrate that our decoder-only LessNet can effectively and efficiently learn both dense displacement and diffeomorphic deformation fields in 3D. Furthermore, our decoder-only LessNet can achieve comparable registration performance to state-of-the-art methods such as VoxelMorph and TransMorph, while requiring significantly fewer computational resources. Our code and pre-trained models are available at https://github.com/xi-jia/LessNet.
UniTSFace: Unified Threshold Integrated Sample-to-Sample Loss for Face Recognition
Nov 04, 2023



Sample-to-class-based face recognition models can not fully explore the cross-sample relationship among large amounts of facial images, while sample-to-sample-based models require sophisticated pairing processes for training. Furthermore, neither method satisfies the requirements of real-world face verification applications, which expect a unified threshold separating positive from negative facial pairs. In this paper, we propose a unified threshold integrated sample-to-sample based loss (USS loss), which features an explicit unified threshold for distinguishing positive from negative pairs. Inspired by our USS loss, we also derive the sample-to-sample based softmax and BCE losses, and discuss their relationship. Extensive evaluation on multiple benchmark datasets, including MFR, IJB-C, LFW, CFP-FP, AgeDB, and MegaFace, demonstrates that the proposed USS loss is highly efficient and can work seamlessly with sample-to-class-based losses. The embedded loss (USS and sample-to-class Softmax loss) overcomes the pitfalls of previous approaches and the trained facial model UniTSFace exhibits exceptional performance, outperforming state-of-the-art methods, such as CosFace, ArcFace, VPL, AnchorFace, and UNPG. Our code is available.
Fourier-Net+: Leveraging Band-Limited Representation for Efficient 3D Medical Image Registration
Jul 06, 2023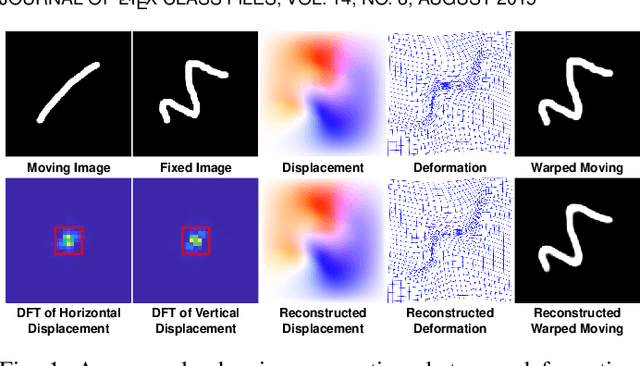
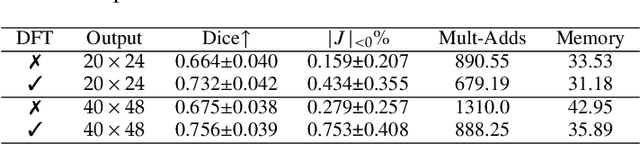
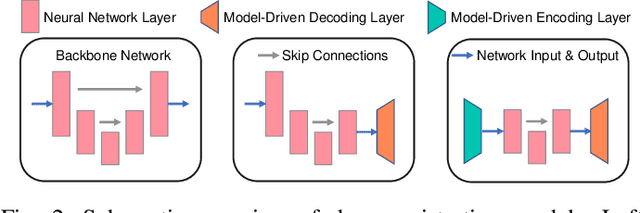
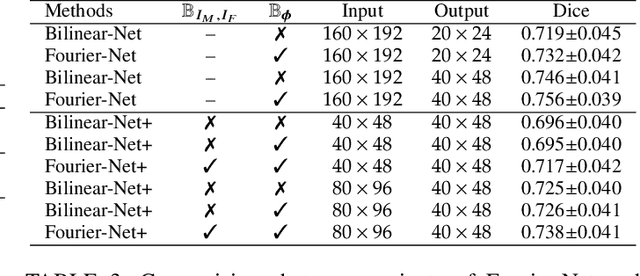
U-Net style networks are commonly utilized in unsupervised image registration to predict dense displacement fields, which for high-resolution volumetric image data is a resource-intensive and time-consuming task. To tackle this challenge, we first propose Fourier-Net, which replaces the costly U-Net style expansive path with a parameter-free model-driven decoder. Instead of directly predicting a full-resolution displacement field, our Fourier-Net learns a low-dimensional representation of the displacement field in the band-limited Fourier domain which our model-driven decoder converts to a full-resolution displacement field in the spatial domain. Expanding upon Fourier-Net, we then introduce Fourier-Net+, which additionally takes the band-limited spatial representation of the images as input and further reduces the number of convolutional layers in the U-Net style network's contracting path. Finally, to enhance the registration performance, we propose a cascaded version of Fourier-Net+. We evaluate our proposed methods on three datasets, on which our proposed Fourier-Net and its variants achieve comparable results with current state-of-the art methods, while exhibiting faster inference speeds, lower memory footprint, and fewer multiply-add operations. With such small computational cost, our Fourier-Net+ enables the efficient training of large-scale 3D registration on low-VRAM GPUs. Our code is publicly available at \url{https://github.com/xi-jia/Fourier-Net}.
Category-Level 6D Object Pose Estimation with Flexible Vector-Based Rotation Representation
Dec 09, 2022



In this paper, we propose a novel 3D graph convolution based pipeline for category-level 6D pose and size estimation from monocular RGB-D images. The proposed method leverages an efficient 3D data augmentation and a novel vector-based decoupled rotation representation. Specifically, we first design an orientation-aware autoencoder with 3D graph convolution for latent feature learning. The learned latent feature is insensitive to point shift and size thanks to the shift and scale-invariance properties of the 3D graph convolution. Then, to efficiently decode the rotation information from the latent feature, we design a novel flexible vector-based decomposable rotation representation that employs two decoders to complementarily access the rotation information. The proposed rotation representation has two major advantages: 1) decoupled characteristic that makes the rotation estimation easier; 2) flexible length and rotated angle of the vectors allow us to find a more suitable vector representation for specific pose estimation task. Finally, we propose a 3D deformation mechanism to increase the generalization ability of the pipeline. Extensive experiments show that the proposed pipeline achieves state-of-the-art performance on category-level tasks. Further, the experiments demonstrate that the proposed rotation representation is more suitable for the pose estimation tasks than other rotation representations.
Fourier-Net: Fast Image Registration with Band-limited Deformation
Nov 29, 2022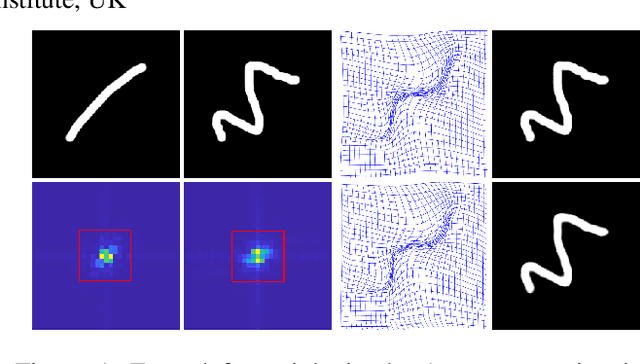
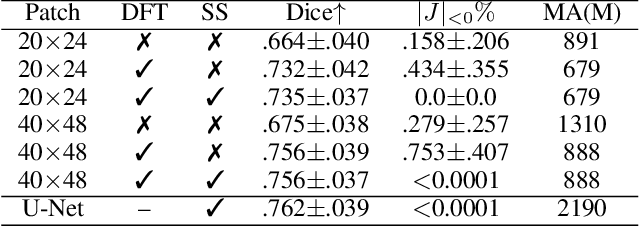
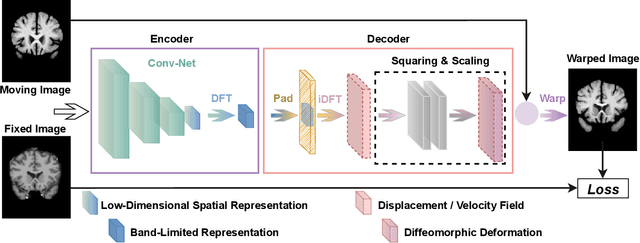
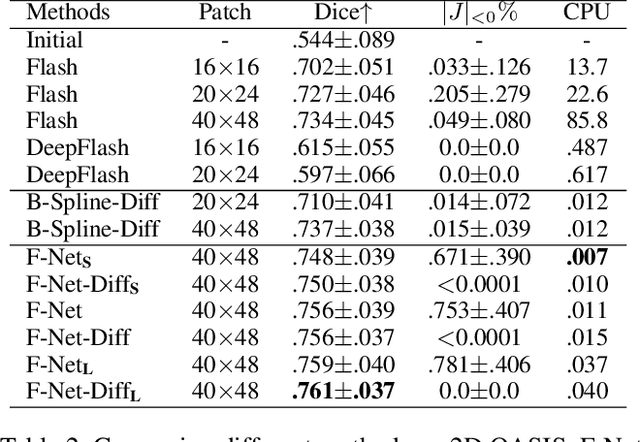
Unsupervised image registration commonly adopts U-Net style networks to predict dense displacement fields in the full-resolution spatial domain. For high-resolution volumetric image data, this process is however resource intensive and time-consuming. To tackle this problem, we propose the Fourier-Net, replacing the expansive path in a U-Net style network with a parameter-free model-driven decoder. Specifically, instead of our Fourier-Net learning to output a full-resolution displacement field in the spatial domain, we learn its low-dimensional representation in a band-limited Fourier domain. This representation is then decoded by our devised model-driven decoder (consisting of a zero padding layer and an inverse discrete Fourier transform layer) to the dense, full-resolution displacement field in the spatial domain. These changes allow our unsupervised Fourier-Net to contain fewer parameters and computational operations, resulting in faster inference speeds. Fourier-Net is then evaluated on two public 3D brain datasets against various state-of-the-art approaches. For example, when compared to a recent transformer-based method, i.e., TransMorph, our Fourier-Net, only using 0.22$\%$ of its parameters and 6.66$\%$ of the mult-adds, achieves a 0.6\% higher Dice score and an 11.48$\times$ faster inference speed. Code is available at \url{https://github.com/xi-jia/Fourier-Net}.
GRATIS: Deep Learning Graph Representation with Task-specific Topology and Multi-dimensional Edge Features
Nov 19, 2022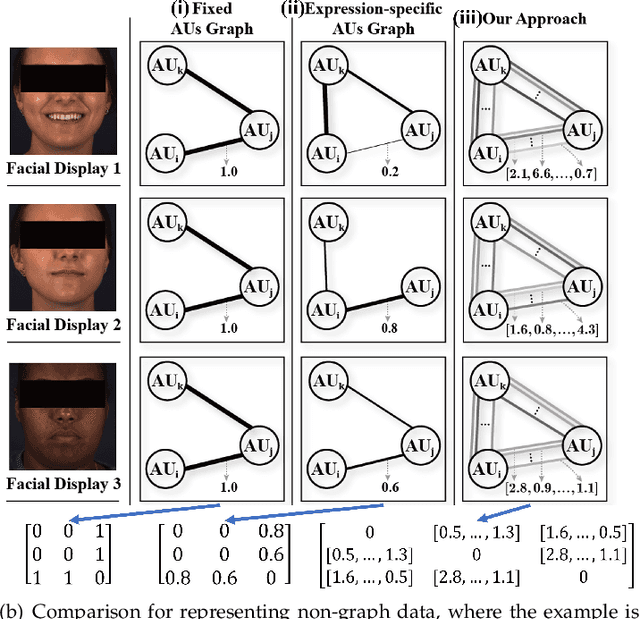
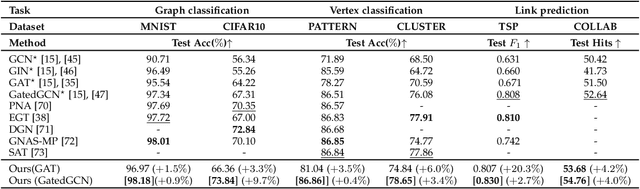
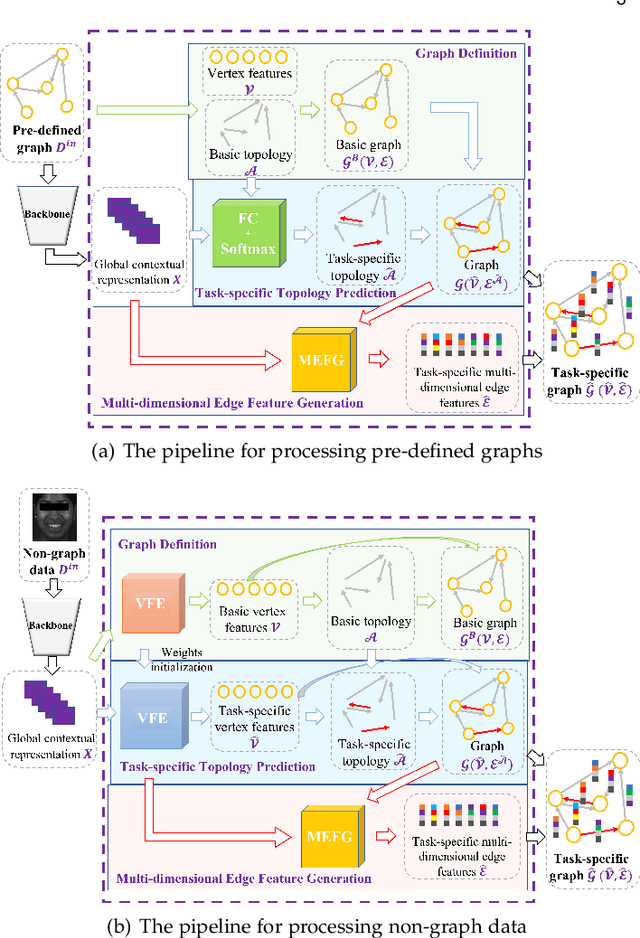
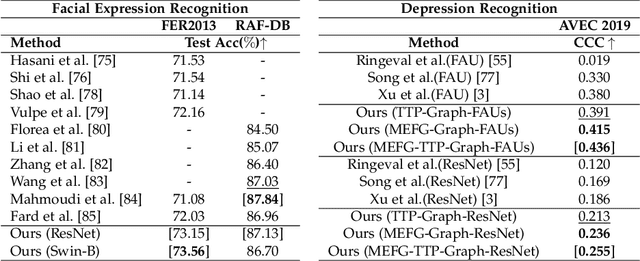
Graph is powerful for representing various types of real-world data. The topology (edges' presence) and edges' features of a graph decides the message passing mechanism among vertices within the graph. While most existing approaches only manually define a single-value edge to describe the connectivity or strength of association between a pair of vertices, task-specific and crucial relationship cues may be disregarded by such manually defined topology and single-value edge features. In this paper, we propose the first general graph representation learning framework (called GRATIS) which can generate a strong graph representation with a task-specific topology and task-specific multi-dimensional edge features from any arbitrary input. To learn each edge's presence and multi-dimensional feature, our framework takes both of the corresponding vertices pair and their global contextual information into consideration, enabling the generated graph representation to have a globally optimal message passing mechanism for different down-stream tasks. The principled investigation results achieved for various graph analysis tasks on 11 graph and non-graph datasets show that our GRATIS can not only largely enhance pre-defined graphs but also learns a strong graph representation for non-graph data, with clear performance improvements on all tasks. In particular, the learned topology and multi-dimensional edge features provide complementary task-related cues for graph analysis tasks. Our framework is effective, robust and flexible, and is a plug-and-play module that can be combined with different backbones and Graph Neural Networks (GNNs) to generate a task-specific graph representation from various graph and non-graph data. Our code is made publicly available at https://github.com/SSYSteve/Learning-Graph-Representation-with-Task-specific-Topology-and-Multi-dimensional-Edge-Features.