 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
May 28, 2026Large Vision-Language Models (LVLMs) map visual inputs into dense token sequences, imposing a quadratic computational bottleneck for inference. Elastic visual-token compression addresses this by training a single model that can run at multiple visual-token budgets. However, existing approaches struggle under aggressive compression. Spatial-only compression, as in nested pooling, behaves as an imperfect low-pass filter and induces spectral aliasing that obscures fine-grained detail. Query-only compression, as in nested query resampling, replaces explicit grid-aligned tokens with non-local summaries and substantially degrades spatial grounding. To resolve this representational conflict, we introduce PARCEL (Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding), a visual tokenization architecture that dynamically partitions the labor of feature extraction. PARCEL establishes spatial pool tokens as low-frequency layout anchors and conditions elastic query tokens on these anchors through Pool-Conditioned Query Resampling. This encourages query tokens to focus on complementary visual features rather than redundant spatial mapping. Extensive evaluations across 27 benchmarks show that PARCEL improves the performance-efficiency Pareto frontier, consistently outperforming existing matryoshka baselines across visual-token budgets while preserving the "train once, deploy anywhere" paradigm.
On Calibration of Object Detectors: Pitfalls, Evaluation and Baselines
May 30, 2024Reliable usage of object detectors require them to be calibrated -- a crucial problem that requires careful attention. Recent approaches towards this involve (1) designing new loss functions to obtain calibrated detectors by training them from scratch, and (2) post-hoc Temperature Scaling (TS) that learns to scale the likelihood of a trained detector to output calibrated predictions. These approaches are then evaluated based on a combination of Detection Expected Calibration Error (D-ECE) and Average Precision. In this work, via extensive analysis and insights, we highlight that these recent evaluation frameworks, evaluation metrics, and the use of TS have notable drawbacks leading to incorrect conclusions. As a step towards fixing these issues, we propose a principled evaluation framework to jointly measure calibration and accuracy of object detectors. We also tailor efficient and easy-to-use post-hoc calibration approaches such as Platt Scaling and Isotonic Regression specifically for object detection task. Contrary to the common notion, our experiments show that once designed and evaluated properly, post-hoc calibrators, which are extremely cheap to build and use, are much more powerful and effective than the recent train-time calibration methods. To illustrate, D-DETR with our post-hoc Isotonic Regression calibrator outperforms the recent train-time state-of-the-art calibration method Cal-DETR by more than 7 D-ECE on the COCO dataset. Additionally, we propose improved versions of the recently proposed Localization-aware ECE and show the efficacy of our method on these metrics as well. Code is available at: https://github.com/fiveai/detection_calibration.
Uncertainty-based Fairness Measures
Dec 18, 2023



Unfair predictions of machine learning (ML) models impede their broad acceptance in real-world settings. Tackling this arduous challenge first necessitates defining what it means for an ML model to be fair. This has been addressed by the ML community with various measures of fairness that depend on the prediction outcomes of the ML models, either at the group level or the individual level. These fairness measures are limited in that they utilize point predictions, neglecting their variances, or uncertainties, making them susceptible to noise, missingness and shifts in data. In this paper, we first show that an ML model may appear to be fair with existing point-based fairness measures but biased against a demographic group in terms of prediction uncertainties. Then, we introduce new fairness measures based on different types of uncertainties, namely, aleatoric uncertainty and epistemic uncertainty. We demonstrate on many datasets that (i) our uncertainty-based measures are complementary to existing measures of fairness, and (ii) they provide more insights about the underlying issues leading to bias.
MoCaE: Mixture of Calibrated Experts Significantly Improves Object Detection
Sep 27, 2023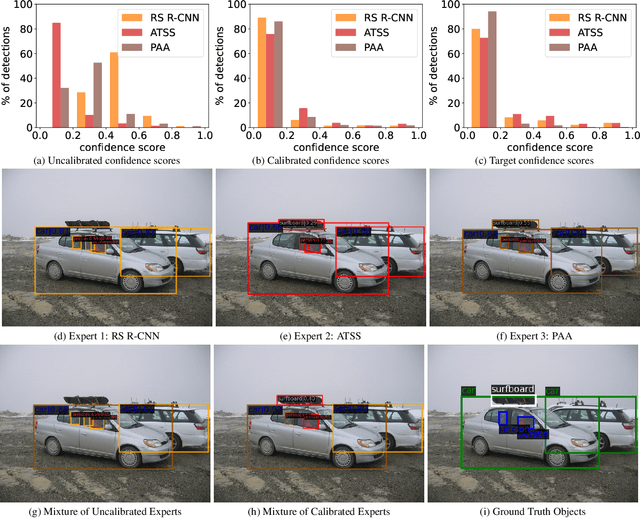
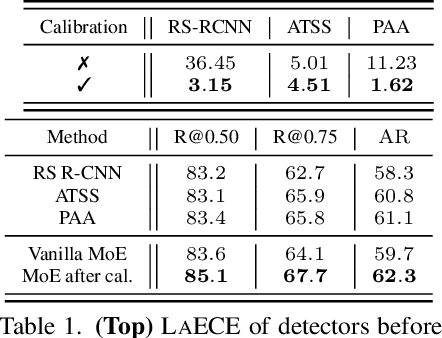
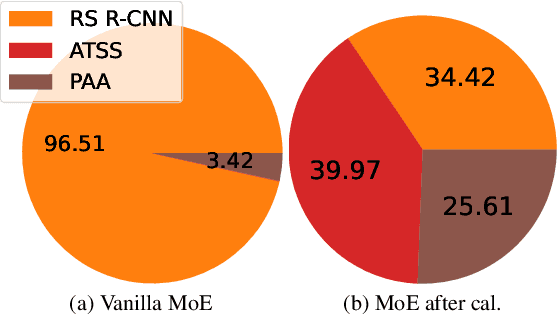
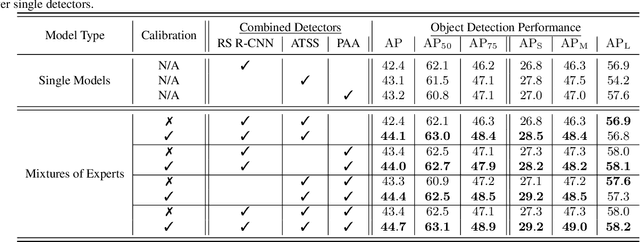
We propose an extremely simple and highly effective approach to faithfully combine different object detectors to obtain a Mixture of Experts (MoE) that has a superior accuracy to the individual experts in the mixture. We find that naively combining these experts in a similar way to the well-known Deep Ensembles (DEs), does not result in an effective MoE. We identify the incompatibility between the confidence score distribution of different detectors to be the primary reason for such failure cases. Therefore, to construct the MoE, our proposal is to first calibrate each individual detector against a target calibration function. Then, filter and refine all the predictions from different detectors in the mixture. We term this approach as MoCaE and demonstrate its effectiveness through extensive experiments on object detection, instance segmentation and rotated object detection tasks. Specifically, MoCaE improves (i) three strong object detectors on COCO test-dev by $2.4$ $\mathrm{AP}$ by reaching $59.0$ $\mathrm{AP}$; (ii) instance segmentation methods on the challenging long-tailed LVIS dataset by $2.3$ $\mathrm{AP}$; and (iii) all existing rotated object detectors by reaching $82.62$ $\mathrm{AP_{50}}$ on DOTA dataset, establishing a new state-of-the-art (SOTA). Code will be made public.
GRATIS: Deep Learning Graph Representation with Task-specific Topology and Multi-dimensional Edge Features
Nov 19, 2022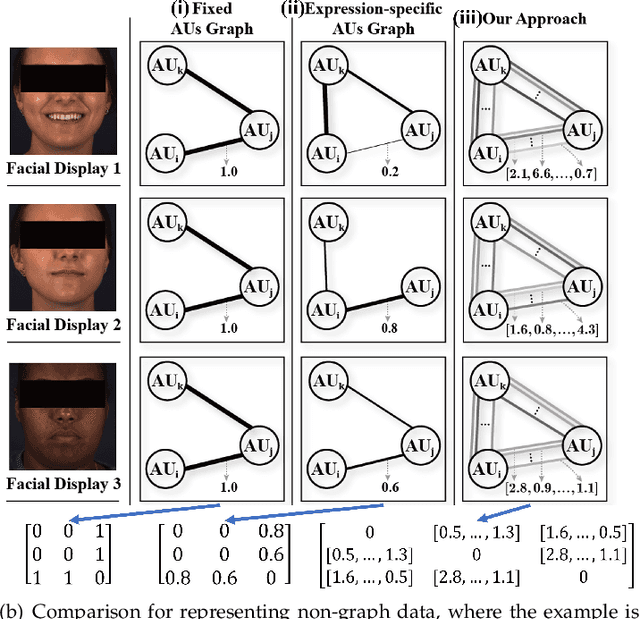
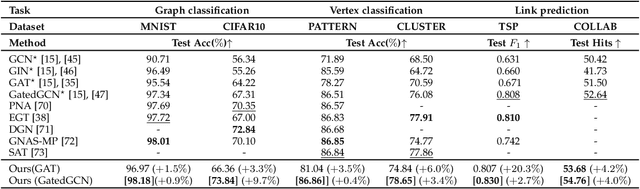
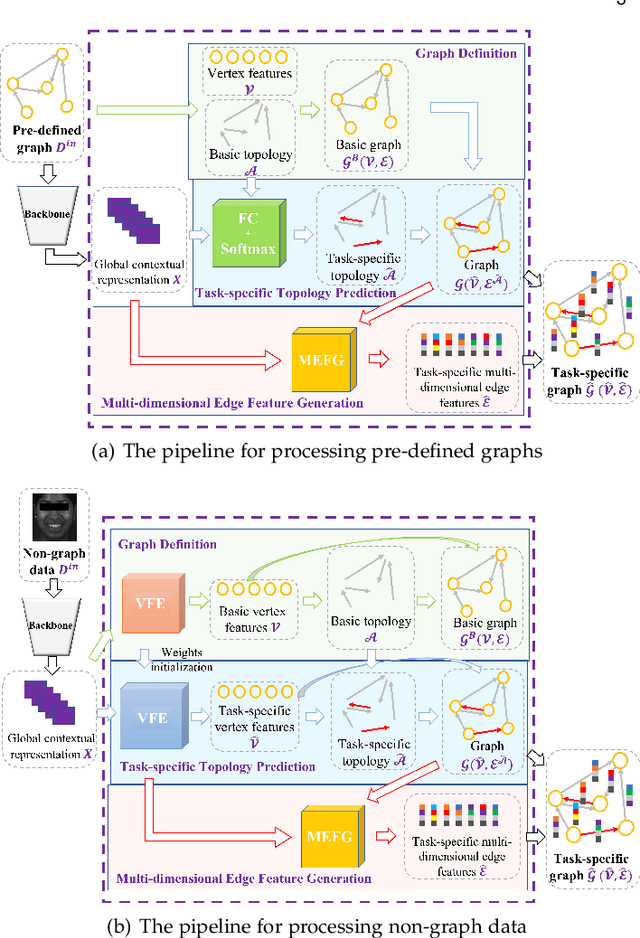
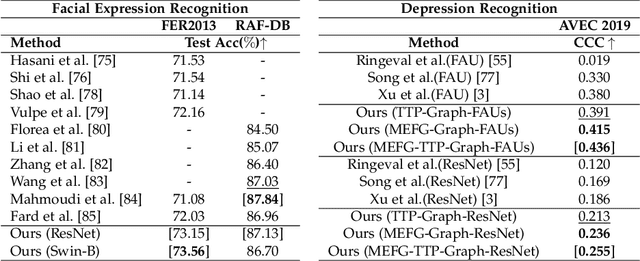
Graph is powerful for representing various types of real-world data. The topology (edges' presence) and edges' features of a graph decides the message passing mechanism among vertices within the graph. While most existing approaches only manually define a single-value edge to describe the connectivity or strength of association between a pair of vertices, task-specific and crucial relationship cues may be disregarded by such manually defined topology and single-value edge features. In this paper, we propose the first general graph representation learning framework (called GRATIS) which can generate a strong graph representation with a task-specific topology and task-specific multi-dimensional edge features from any arbitrary input. To learn each edge's presence and multi-dimensional feature, our framework takes both of the corresponding vertices pair and their global contextual information into consideration, enabling the generated graph representation to have a globally optimal message passing mechanism for different down-stream tasks. The principled investigation results achieved for various graph analysis tasks on 11 graph and non-graph datasets show that our GRATIS can not only largely enhance pre-defined graphs but also learns a strong graph representation for non-graph data, with clear performance improvements on all tasks. In particular, the learned topology and multi-dimensional edge features provide complementary task-related cues for graph analysis tasks. Our framework is effective, robust and flexible, and is a plug-and-play module that can be combined with different backbones and Graph Neural Networks (GNNs) to generate a task-specific graph representation from various graph and non-graph data. Our code is made publicly available at https://github.com/SSYSteve/Learning-Graph-Representation-with-Task-specific-Topology-and-Multi-dimensional-Edge-Features.