 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Calibration of Object Detectors: Pitfalls, Evaluation and Baselines
May 30, 2024Reliable usage of object detectors require them to be calibrated -- a crucial problem that requires careful attention. Recent approaches towards this involve (1) designing new loss functions to obtain calibrated detectors by training them from scratch, and (2) post-hoc Temperature Scaling (TS) that learns to scale the likelihood of a trained detector to output calibrated predictions. These approaches are then evaluated based on a combination of Detection Expected Calibration Error (D-ECE) and Average Precision. In this work, via extensive analysis and insights, we highlight that these recent evaluation frameworks, evaluation metrics, and the use of TS have notable drawbacks leading to incorrect conclusions. As a step towards fixing these issues, we propose a principled evaluation framework to jointly measure calibration and accuracy of object detectors. We also tailor efficient and easy-to-use post-hoc calibration approaches such as Platt Scaling and Isotonic Regression specifically for object detection task. Contrary to the common notion, our experiments show that once designed and evaluated properly, post-hoc calibrators, which are extremely cheap to build and use, are much more powerful and effective than the recent train-time calibration methods. To illustrate, D-DETR with our post-hoc Isotonic Regression calibrator outperforms the recent train-time state-of-the-art calibration method Cal-DETR by more than 7 D-ECE on the COCO dataset. Additionally, we propose improved versions of the recently proposed Localization-aware ECE and show the efficacy of our method on these metrics as well. Code is available at: https://github.com/fiveai/detection_calibration.
Attacking Motion Planners Using Adversarial Perception Errors
Nov 21, 2023



Autonomous driving (AD) systems are often built and tested in a modular fashion, where the performance of different modules is measured using task-specific metrics. These metrics should be chosen so as to capture the downstream impact of each module and the performance of the system as a whole. For example, high perception quality should enable prediction and planning to be performed safely. Even though this is true in general, we show here that it is possible to construct planner inputs that score very highly on various perception quality metrics but still lead to planning failures. In an analogy to adversarial attacks on image classifiers, we call such inputs \textbf{adversarial perception errors} and show they can be systematically constructed using a simple boundary-attack algorithm. We demonstrate the effectiveness of this algorithm by finding attacks for two different black-box planners in several urban and highway driving scenarios using the CARLA simulator. Finally, we analyse the properties of these attacks and show that they are isolated in the input space of the planner, and discuss their implications for AD system deployment and testing.
Bayesian Quadrature for Probability Threshold Robustness of Partially Undefined Functions
Oct 05, 2022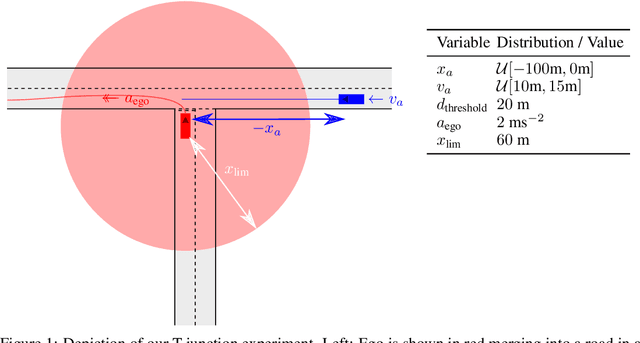
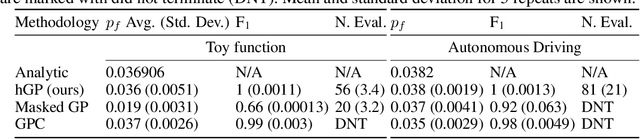
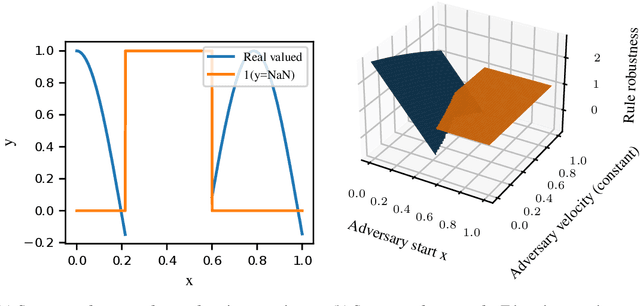
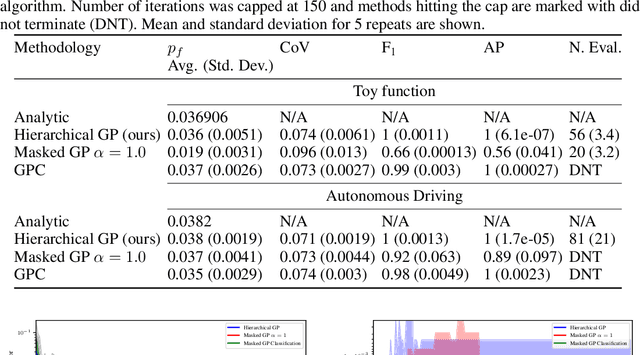
In engineering design, one often wishes to calculate the probability that the performance of a system is satisfactory under uncertainty. State of the art algorithms exist to solve this problem using active learning with Gaussian process models. However, these algorithms cannot be applied to problems which often occur in the autonomous vehicle domain where the performance of a system may be undefined under certain circumstances. Na\"ive modification of existing algorithms by simply masking undefined values will introduce a discontinuous system performance function, and would be unsuccessful because these algorithms are known to fail for discontinuous performance functions. We solve this problem using a hierarchical model for the system performance, where undefined performance is classified before the performance is regressed. This enables active learning Gaussian process methods to be applied to problems where the performance of the system is sometimes undefined, and we demonstrate this by testing our methodology on synthetic numerical examples for the autonomous driving domain.
Query-based Hard-Image Retrieval for Object Detection at Test Time
Sep 23, 2022
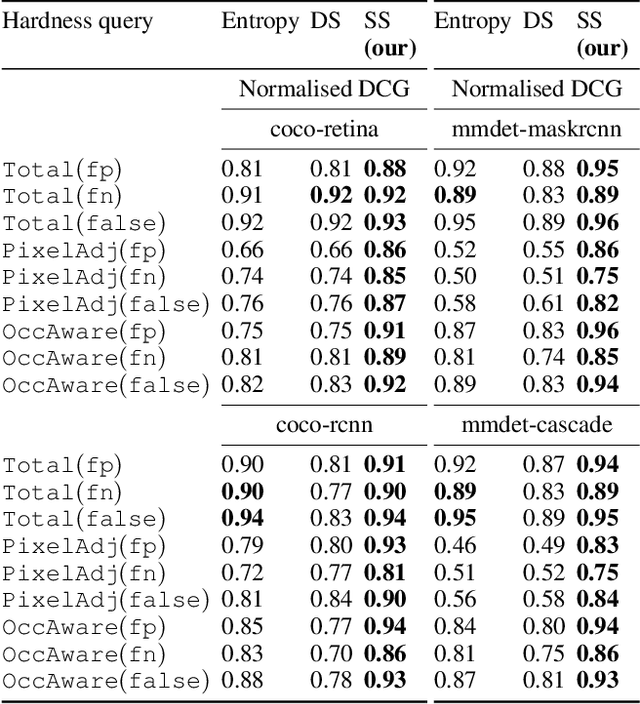
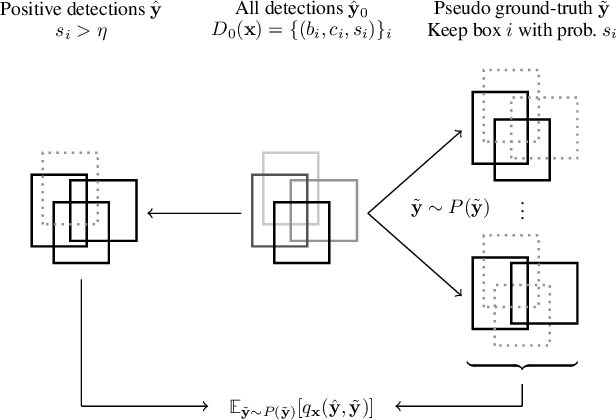
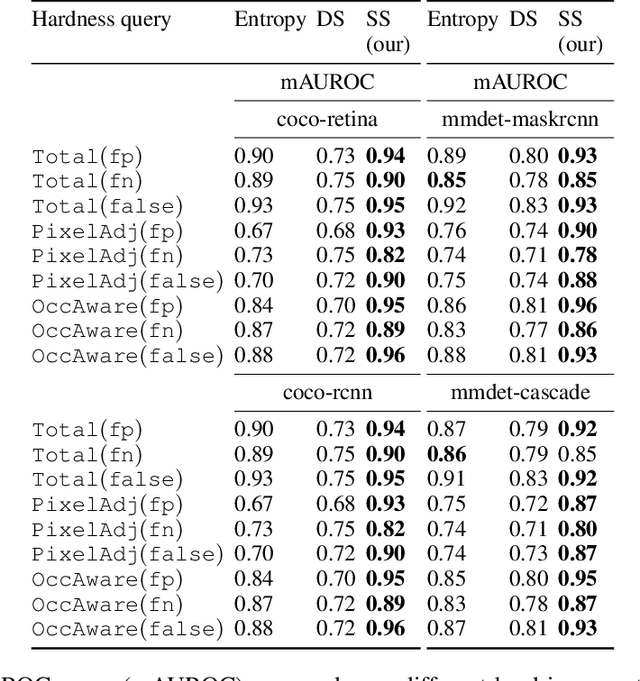
There is a longstanding interest in capturing the error behaviour of object detectors by finding images where their performance is likely to be unsatisfactory. In real-world applications such as autonomous driving, it is also crucial to characterise potential failures beyond simple requirements of detection performance. For example, a missed detection of a pedestrian close to an ego vehicle will generally require closer inspection than a missed detection of a car in the distance. The problem of predicting such potential failures at test time has largely been overlooked in the literature and conventional approaches based on detection uncertainty fall short in that they are agnostic to such fine-grained characterisation of errors. In this work, we propose to reformulate the problem of finding "hard" images as a query-based hard image retrieval task, where queries are specific definitions of "hardness", and offer a simple and intuitive method that can solve this task for a large family of queries. Our method is entirely post-hoc, does not require ground-truth annotations, is independent of the choice of a detector, and relies on an efficient Monte Carlo estimation that uses a simple stochastic model in place of the ground-truth. We show experimentally that it can be applied successfully to a wide variety of queries for which it can reliably identify hard images for a given detector without any labelled data. We provide results on ranking and classification tasks using the widely used RetinaNet, Faster-RCNN, Mask-RCNN, and Cascade Mask-RCNN object detectors.
Perspectives on the System-level Design of a Safe Autonomous Driving Stack
Jul 29, 2022
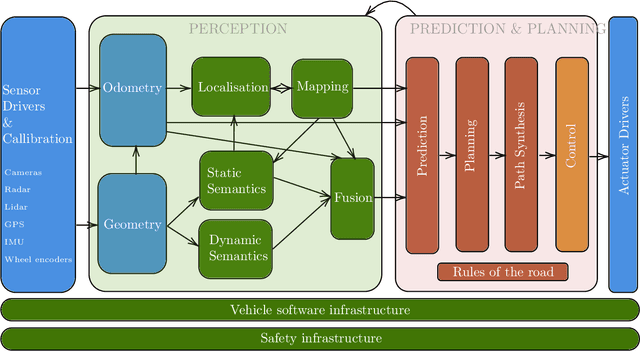
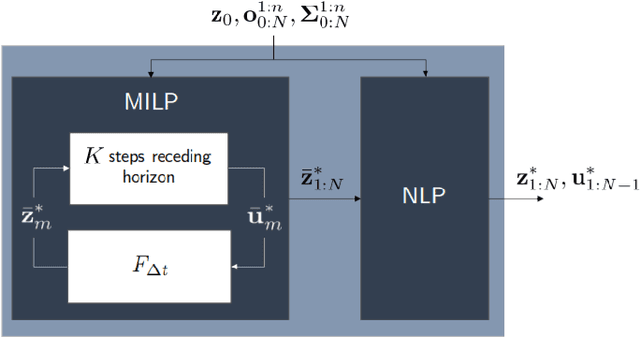
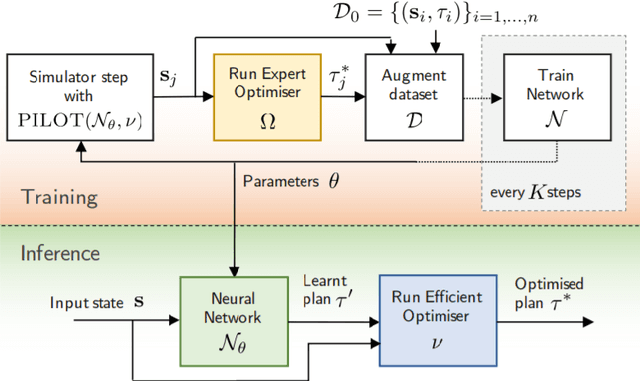
Achieving safe and robust autonomy is the key bottleneck on the path towards broader adoption of autonomous vehicles technology. This motivates going beyond extrinsic metrics such as miles between disengagement, and calls for approaches that embody safety by design. In this paper, we address some aspects of this challenge, with emphasis on issues of motion planning and prediction. We do this through description of novel approaches taken to solving selected sub-problems within an autonomous driving stack, in the process introducing the design philosophy being adopted within Five. This includes safe-by-design planning, interpretable as well as verifiable prediction, and modelling of perception errors to enable effective sim-to-real and real-to-sim transfer within the testing pipeline of a realistic autonomous system.
A Step Towards Efficient Evaluation of Complex Perception Tasks in Simulation
Sep 28, 2021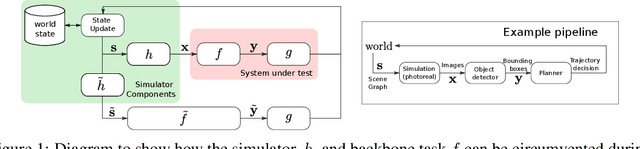
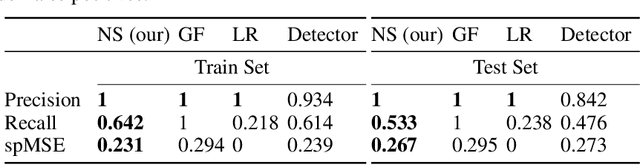
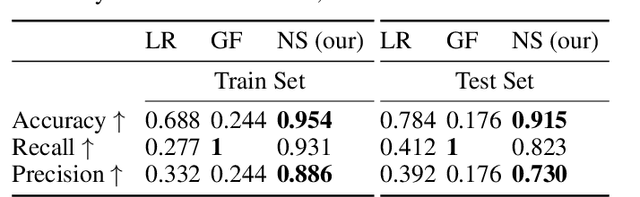
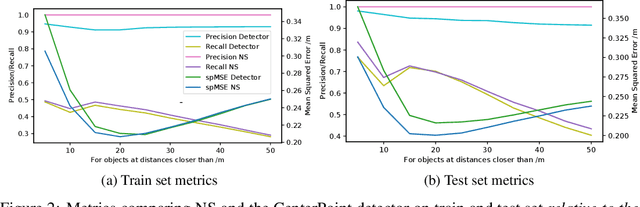
There has been increasing interest in characterising the error behaviour of systems which contain deep learning models before deploying them into any safety-critical scenario. However, characterising such behaviour usually requires large-scale testing of the model that can be extremely computationally expensive for complex real-world tasks. For example, tasks involving compute intensive object detectors as one of their components. In this work, we propose an approach that enables efficient large-scale testing using simplified low-fidelity simulators and without the computational cost of executing expensive deep learning models. Our approach relies on designing an efficient surrogate model corresponding to the compute intensive components of the task under test. We demonstrate the efficacy of our methodology by evaluating the performance of an autonomous driving task in the Carla simulator with reduced computational expense by training efficient surrogate models for PIXOR and CenterPoint LiDAR detectors, whilst demonstrating that the accuracy of the simulation is maintained.