 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMObI: Multimodal Object Inpainting Using Diffusion Models
Jan 06, 2025



Safety-critical applications, such as autonomous driving, require extensive multimodal data for rigorous testing. Methods based on synthetic data are gaining prominence due to the cost and complexity of gathering real-world data but require a high degree of realism and controllability in order to be useful. This paper introduces MObI, a novel framework for Multimodal Object Inpainting that leverages a diffusion model to create realistic and controllable object inpaintings across perceptual modalities, demonstrated for both camera and lidar simultaneously. Using a single reference RGB image, MObI enables objects to be seamlessly inserted into existing multimodal scenes at a 3D location specified by a bounding box, while maintaining semantic consistency and multimodal coherence. Unlike traditional inpainting methods that rely solely on edit masks, our 3D bounding box conditioning gives objects accurate spatial positioning and realistic scaling. As a result, our approach can be used to insert novel objects flexibly into multimodal scenes, providing significant advantages for testing perception models.
Lift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
Dec 26, 2023



Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance and that, strikingly, removing depth estimation altogether does not degrade object detection performance. This suggests that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
Attacking Motion Planners Using Adversarial Perception Errors
Nov 21, 2023



Autonomous driving (AD) systems are often built and tested in a modular fashion, where the performance of different modules is measured using task-specific metrics. These metrics should be chosen so as to capture the downstream impact of each module and the performance of the system as a whole. For example, high perception quality should enable prediction and planning to be performed safely. Even though this is true in general, we show here that it is possible to construct planner inputs that score very highly on various perception quality metrics but still lead to planning failures. In an analogy to adversarial attacks on image classifiers, we call such inputs \textbf{adversarial perception errors} and show they can be systematically constructed using a simple boundary-attack algorithm. We demonstrate the effectiveness of this algorithm by finding attacks for two different black-box planners in several urban and highway driving scenarios using the CARLA simulator. Finally, we analyse the properties of these attacks and show that they are isolated in the input space of the planner, and discuss their implications for AD system deployment and testing.
Comparison of Pedestrian Prediction Models from Trajectory and Appearance Data for Autonomous Driving
May 25, 2023
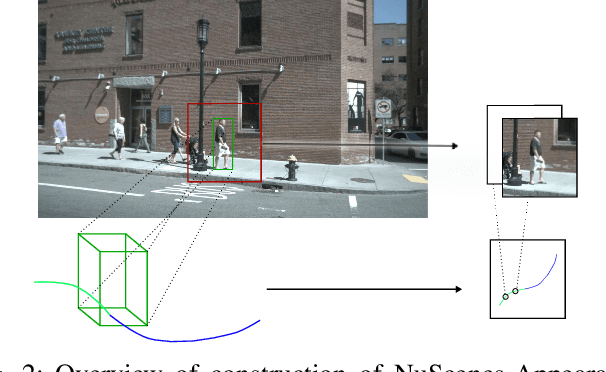
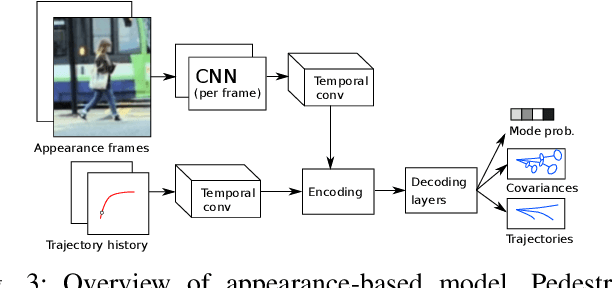
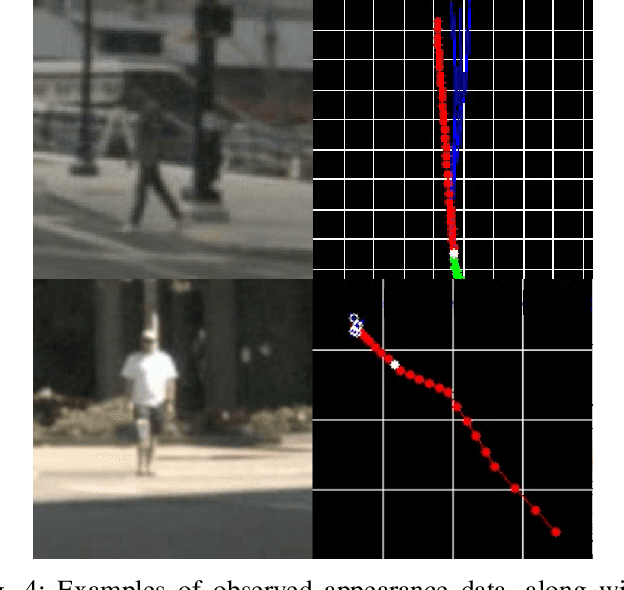
The ability to anticipate pedestrian motion changes is a critical capability for autonomous vehicles. In urban environments, pedestrians may enter the road area and create a high risk for driving, and it is important to identify these cases. Typical predictors use the trajectory history to predict future motion, however in cases of motion initiation, motion in the trajectory may only be clearly visible after a delay, which can result in the pedestrian has entered the road area before an accurate prediction can be made. Appearance data includes useful information such as changes of gait, which are early indicators of motion changes, and can inform trajectory prediction. This work presents a comparative evaluation of trajectory-only and appearance-based methods for pedestrian prediction, and introduces a new dataset experiment for prediction using appearance. We create two trajectory and image datasets based on the combination of image and trajectory sequences from the popular NuScenes dataset, and examine prediction of trajectories using observed appearance to influence futures. This shows some advantages over trajectory prediction alone, although problems with the dataset prevent advantages of appearance-based models from being shown. We describe methods for improving the dataset and experiment to allow benefits of appearance-based models to be captured.
DiPA: Diverse and Probabilistically Accurate Interactive Prediction
Oct 12, 2022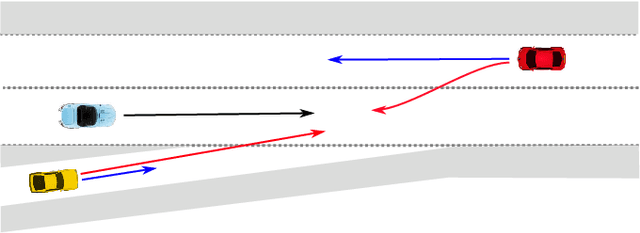
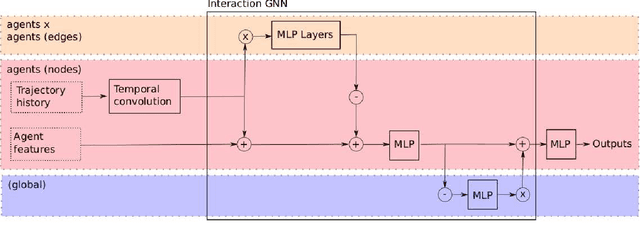

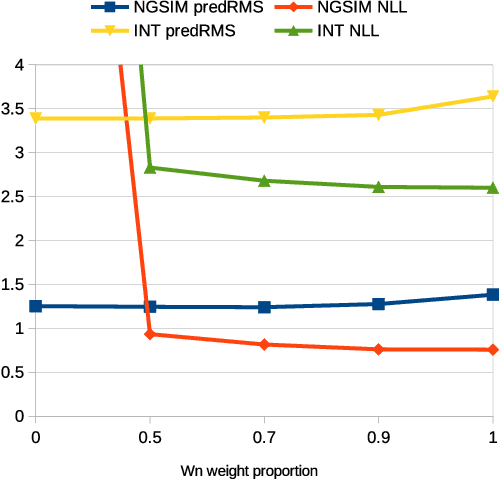
Accurate prediction is important for operating an autonomous vehicle in interactive scenarios. Previous interactive predictors have used closest-mode evaluations, which test if one of a set of predictions covers the ground-truth, but not if additional unlikely predictions are made. The presence of unlikely predictions can interfere with planning, by indicating conflict with the ego plan when it is not likely to occur. Closest-mode evaluations are not sufficient for showing a predictor is useful, an effective predictor also needs to accurately estimate mode probabilities, and to be evaluated using probabilistic measures. These two evaluation approaches, eg. predicted-mode RMS and minADE/FDE, are analogous to precision and recall in binary classification, and there is a challenging trade-off between prediction strategies for each. We present DiPA, a method for producing diverse predictions while also capturing accurate probabilistic estimates. DiPA uses a flexible representation that captures interactions in widely varying road topologies, and uses a novel training regime for a Gaussian Mixture Model that supports diversity of predicted modes, along with accurate spatial distribution and mode probability estimates. DiPA achieves state-of-the-art performance on INTERACTION and NGSIM, and improves over a baseline (MFP) when both closest-mode and probabilistic evaluations are used at the same time.
Bayesian Quadrature for Probability Threshold Robustness of Partially Undefined Functions
Oct 05, 2022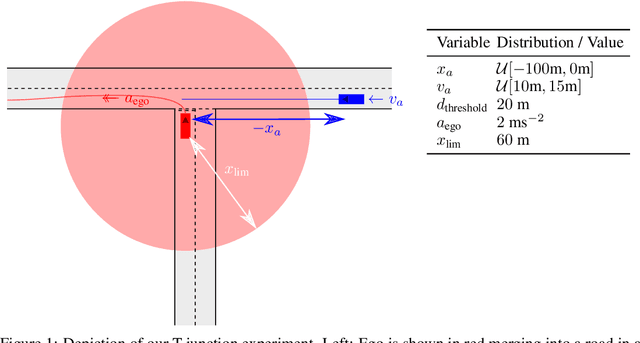
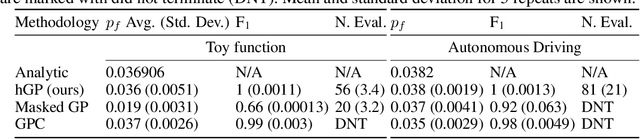
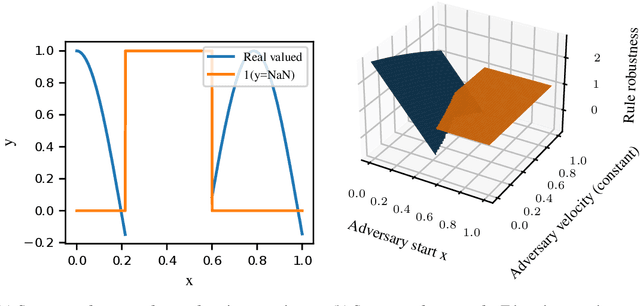
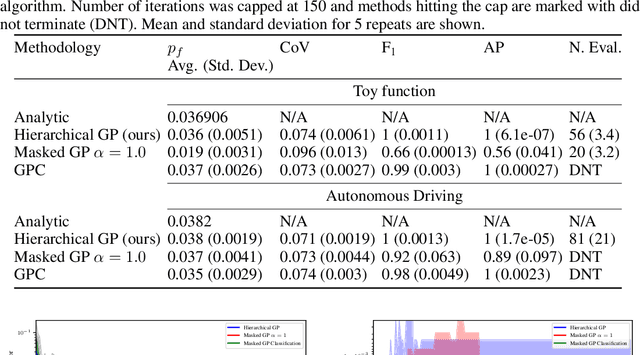
In engineering design, one often wishes to calculate the probability that the performance of a system is satisfactory under uncertainty. State of the art algorithms exist to solve this problem using active learning with Gaussian process models. However, these algorithms cannot be applied to problems which often occur in the autonomous vehicle domain where the performance of a system may be undefined under certain circumstances. Na\"ive modification of existing algorithms by simply masking undefined values will introduce a discontinuous system performance function, and would be unsuccessful because these algorithms are known to fail for discontinuous performance functions. We solve this problem using a hierarchical model for the system performance, where undefined performance is classified before the performance is regressed. This enables active learning Gaussian process methods to be applied to problems where the performance of the system is sometimes undefined, and we demonstrate this by testing our methodology on synthetic numerical examples for the autonomous driving domain.
Query-based Hard-Image Retrieval for Object Detection at Test Time
Sep 23, 2022
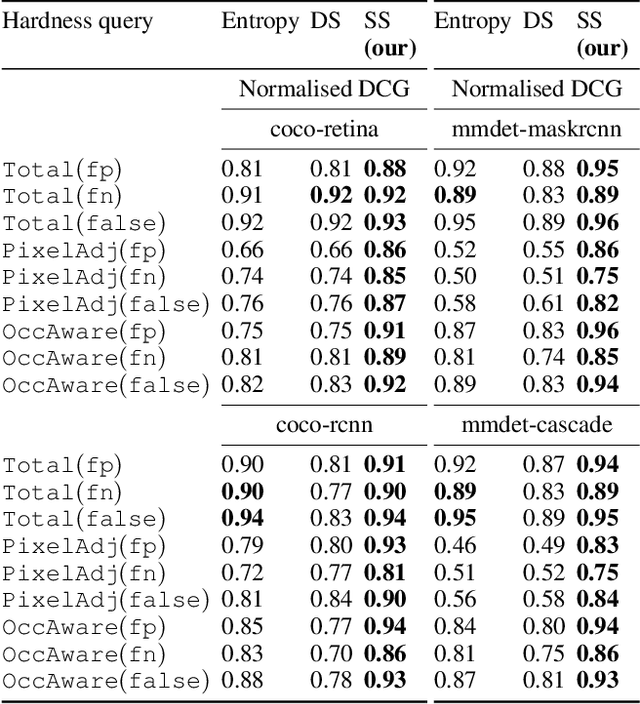
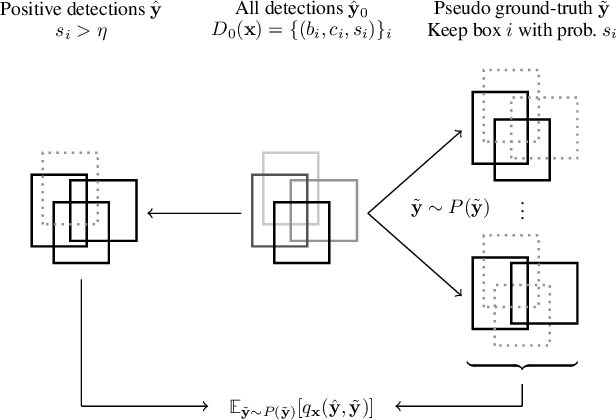
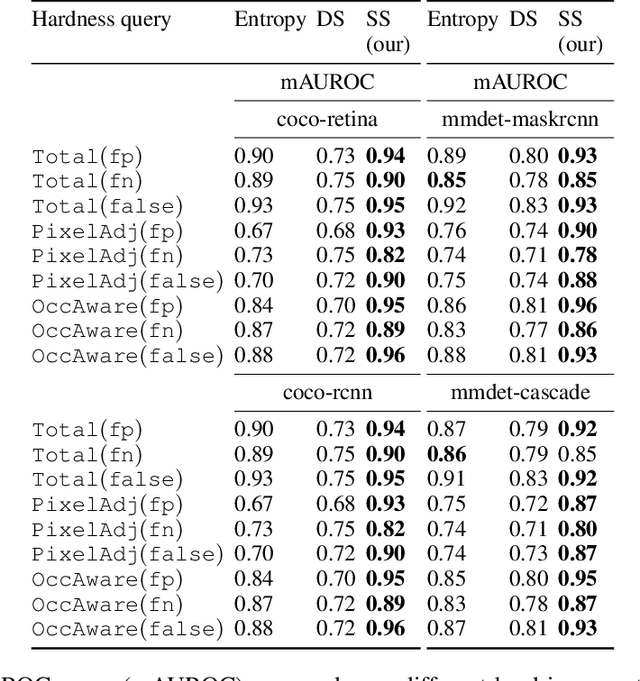
There is a longstanding interest in capturing the error behaviour of object detectors by finding images where their performance is likely to be unsatisfactory. In real-world applications such as autonomous driving, it is also crucial to characterise potential failures beyond simple requirements of detection performance. For example, a missed detection of a pedestrian close to an ego vehicle will generally require closer inspection than a missed detection of a car in the distance. The problem of predicting such potential failures at test time has largely been overlooked in the literature and conventional approaches based on detection uncertainty fall short in that they are agnostic to such fine-grained characterisation of errors. In this work, we propose to reformulate the problem of finding "hard" images as a query-based hard image retrieval task, where queries are specific definitions of "hardness", and offer a simple and intuitive method that can solve this task for a large family of queries. Our method is entirely post-hoc, does not require ground-truth annotations, is independent of the choice of a detector, and relies on an efficient Monte Carlo estimation that uses a simple stochastic model in place of the ground-truth. We show experimentally that it can be applied successfully to a wide variety of queries for which it can reliably identify hard images for a given detector without any labelled data. We provide results on ranking and classification tasks using the widely used RetinaNet, Faster-RCNN, Mask-RCNN, and Cascade Mask-RCNN object detectors.
Perspectives on the System-level Design of a Safe Autonomous Driving Stack
Jul 29, 2022
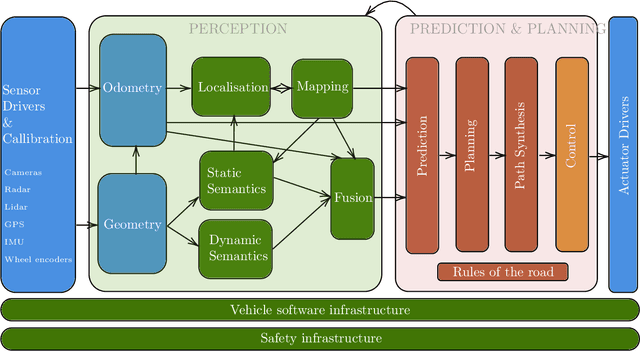
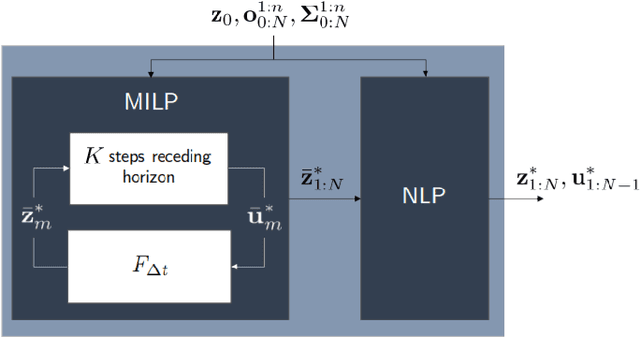
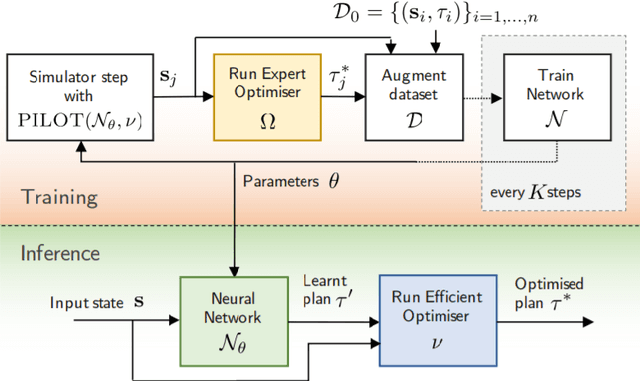
Achieving safe and robust autonomy is the key bottleneck on the path towards broader adoption of autonomous vehicles technology. This motivates going beyond extrinsic metrics such as miles between disengagement, and calls for approaches that embody safety by design. In this paper, we address some aspects of this challenge, with emphasis on issues of motion planning and prediction. We do this through description of novel approaches taken to solving selected sub-problems within an autonomous driving stack, in the process introducing the design philosophy being adopted within Five. This includes safe-by-design planning, interpretable as well as verifiable prediction, and modelling of perception errors to enable effective sim-to-real and real-to-sim transfer within the testing pipeline of a realistic autonomous system.
Beyond RMSE: Do machine-learned models of road user interaction produce human-like behavior?
Jun 22, 2022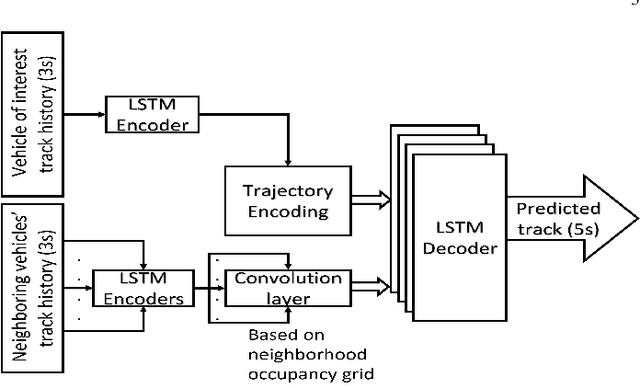
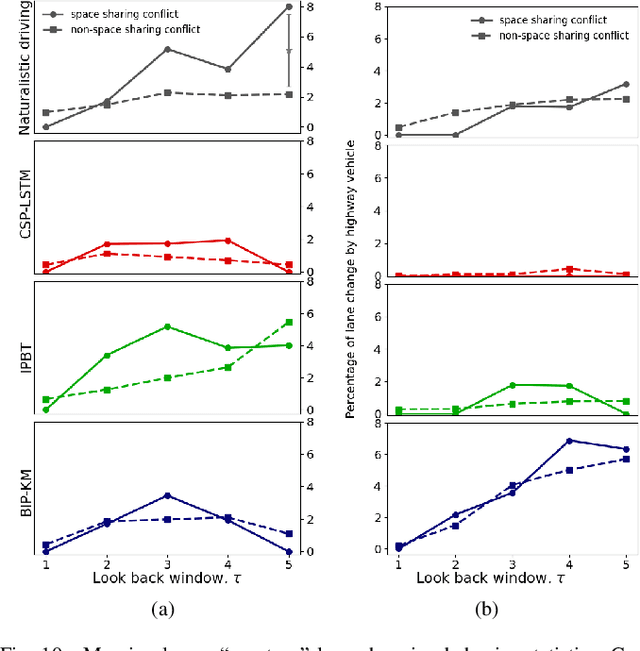
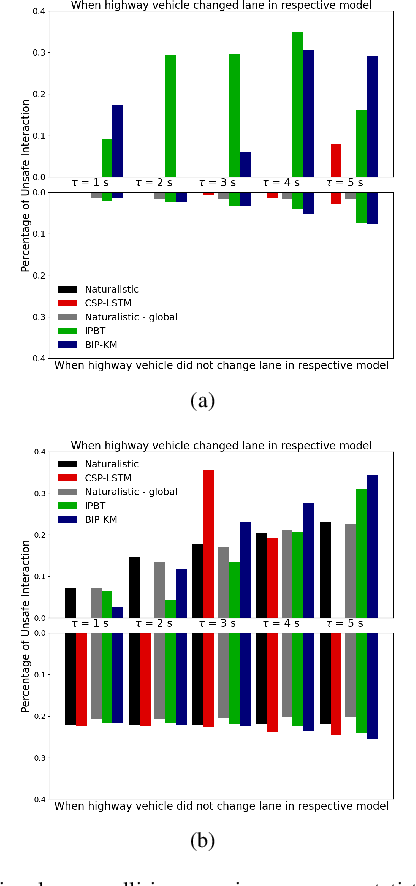
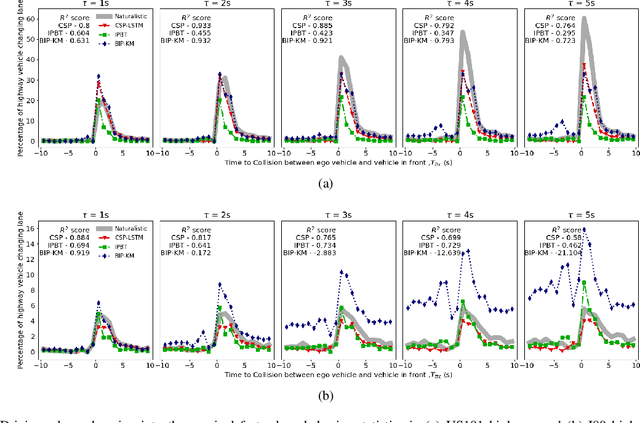
Autonomous vehicles use a variety of sensors and machine-learned models to predict the behavior of surrounding road users. Most of the machine-learned models in the literature focus on quantitative error metrics like the root mean square error (RMSE) to learn and report their models' capabilities. This focus on quantitative error metrics tends to ignore the more important behavioral aspect of the models, raising the question of whether these models really predict human-like behavior. Thus, we propose to analyze the output of machine-learned models much like we would analyze human data in conventional behavioral research. We introduce quantitative metrics to demonstrate presence of three different behavioral phenomena in a naturalistic highway driving dataset: 1) The kinematics-dependence of who passes a merging point first 2) Lane change by an on-highway vehicle to accommodate an on-ramp vehicle 3) Lane changes by vehicles on the highway to avoid lead vehicle conflicts. Then, we analyze the behavior of three machine-learned models using the same metrics. Even though the models' RMSE value differed, all the models captured the kinematic-dependent merging behavior but struggled at varying degrees to capture the more nuanced courtesy lane change and highway lane change behavior. Additionally, the collision aversion analysis during lane changes showed that the models struggled to capture the physical aspect of human driving: leaving adequate gap between the vehicles. Thus, our analysis highlighted the inadequacy of simple quantitative metrics and the need to take a broader behavioral perspective when analyzing machine-learned models of human driving predictions.
Flash: Fast and Light Motion Prediction for Autonomous Driving with Bayesian Inverse Planning and Learned Motion Profiles
Mar 15, 2022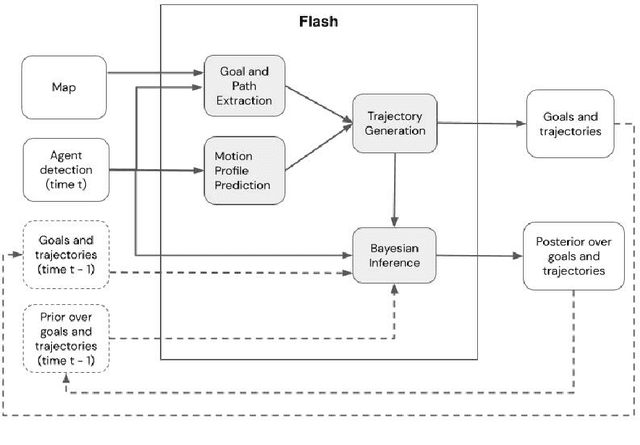
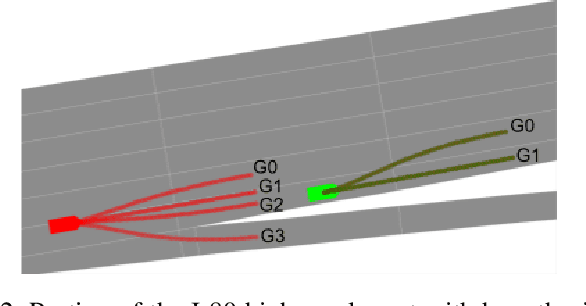
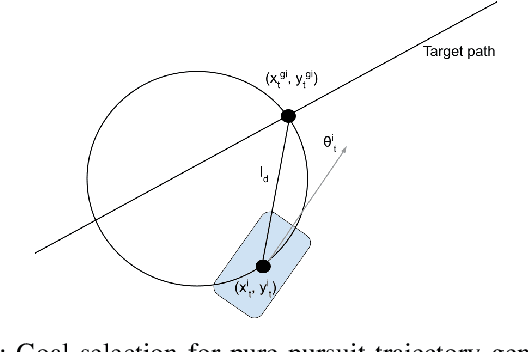
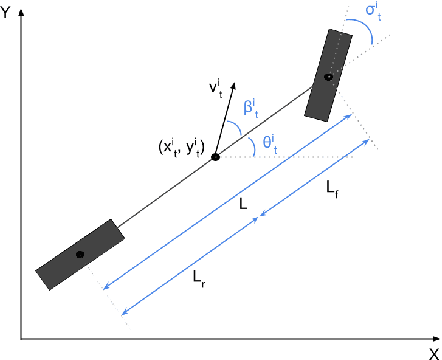
Motion prediction of road users in traffic scenes is critical for autonomous driving systems that must take safe and robust decisions in complex dynamic environments. We present a novel motion prediction system for autonomous driving. Our system is based on the Bayesian inverse planning framework, which efficiently orchestrates map-based goal extraction, a classical control-based trajectory generator and an ensemble of light-weight neural networks specialised in motion profile prediction. In contrast to many alternative methods, this modularity helps isolate performance factors and better interpret results, without compromising performance. This system addresses multiple aspects of interest, namely multi-modality, motion profile uncertainty and trajectory physical feasibility. We report on several experiments with the popular highway dataset NGSIM, demonstrating state-of-the-art performance in terms of trajectory error. We also perform a detailed analysis of our system's components, along with experiments that stratify the data based on behaviours, such as change lane versus follow lane, to provide insights into the challenges in this domain. Finally, we present a qualitative analysis to show other benefits of our approach, such as the ability to interpret the outputs.