 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
Dec 26, 2023



Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance and that, strikingly, removing depth estimation altogether does not degrade object detection performance. This suggests that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
A Step Towards Efficient Evaluation of Complex Perception Tasks in Simulation
Sep 28, 2021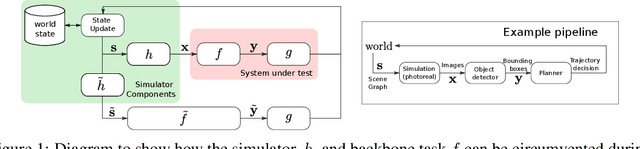
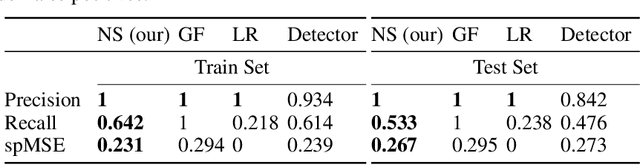
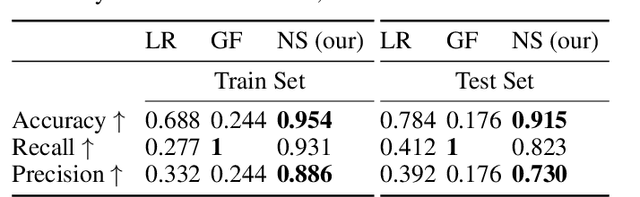
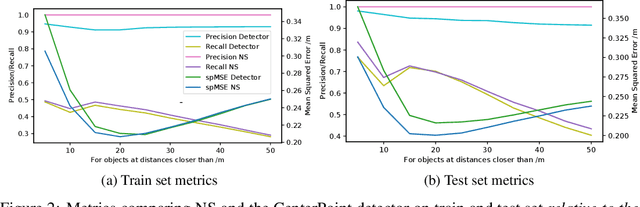
There has been increasing interest in characterising the error behaviour of systems which contain deep learning models before deploying them into any safety-critical scenario. However, characterising such behaviour usually requires large-scale testing of the model that can be extremely computationally expensive for complex real-world tasks. For example, tasks involving compute intensive object detectors as one of their components. In this work, we propose an approach that enables efficient large-scale testing using simplified low-fidelity simulators and without the computational cost of executing expensive deep learning models. Our approach relies on designing an efficient surrogate model corresponding to the compute intensive components of the task under test. We demonstrate the efficacy of our methodology by evaluating the performance of an autonomous driving task in the Carla simulator with reduced computational expense by training efficient surrogate models for PIXOR and CenterPoint LiDAR detectors, whilst demonstrating that the accuracy of the simulation is maintained.