 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMObI: Multimodal Object Inpainting Using Diffusion Models
Jan 06, 2025



Safety-critical applications, such as autonomous driving, require extensive multimodal data for rigorous testing. Methods based on synthetic data are gaining prominence due to the cost and complexity of gathering real-world data but require a high degree of realism and controllability in order to be useful. This paper introduces MObI, a novel framework for Multimodal Object Inpainting that leverages a diffusion model to create realistic and controllable object inpaintings across perceptual modalities, demonstrated for both camera and lidar simultaneously. Using a single reference RGB image, MObI enables objects to be seamlessly inserted into existing multimodal scenes at a 3D location specified by a bounding box, while maintaining semantic consistency and multimodal coherence. Unlike traditional inpainting methods that rely solely on edit masks, our 3D bounding box conditioning gives objects accurate spatial positioning and realistic scaling. As a result, our approach can be used to insert novel objects flexibly into multimodal scenes, providing significant advantages for testing perception models.
Lift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
Dec 26, 2023



Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance and that, strikingly, removing depth estimation altogether does not degrade object detection performance. This suggests that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
Attacking Motion Planners Using Adversarial Perception Errors
Nov 21, 2023



Autonomous driving (AD) systems are often built and tested in a modular fashion, where the performance of different modules is measured using task-specific metrics. These metrics should be chosen so as to capture the downstream impact of each module and the performance of the system as a whole. For example, high perception quality should enable prediction and planning to be performed safely. Even though this is true in general, we show here that it is possible to construct planner inputs that score very highly on various perception quality metrics but still lead to planning failures. In an analogy to adversarial attacks on image classifiers, we call such inputs \textbf{adversarial perception errors} and show they can be systematically constructed using a simple boundary-attack algorithm. We demonstrate the effectiveness of this algorithm by finding attacks for two different black-box planners in several urban and highway driving scenarios using the CARLA simulator. Finally, we analyse the properties of these attacks and show that they are isolated in the input space of the planner, and discuss their implications for AD system deployment and testing.
Bayesian Quadrature for Probability Threshold Robustness of Partially Undefined Functions
Oct 05, 2022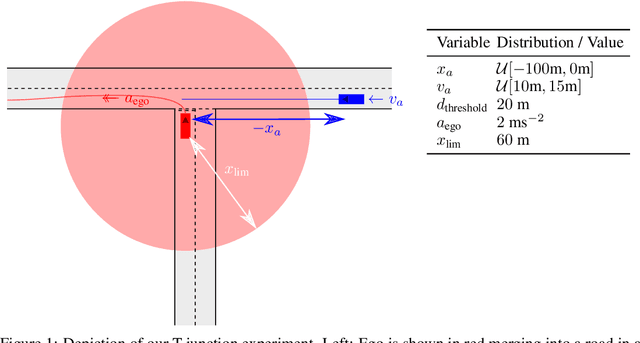
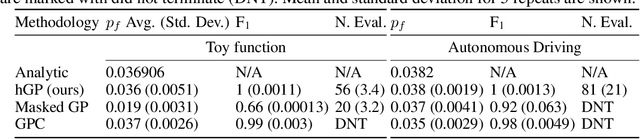
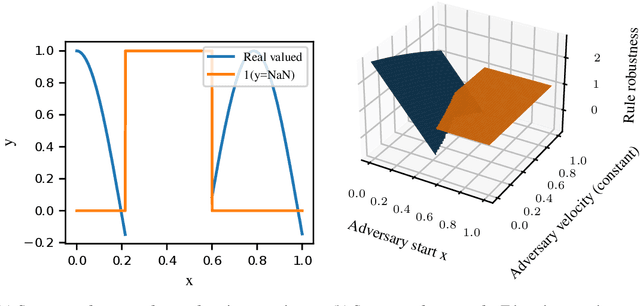
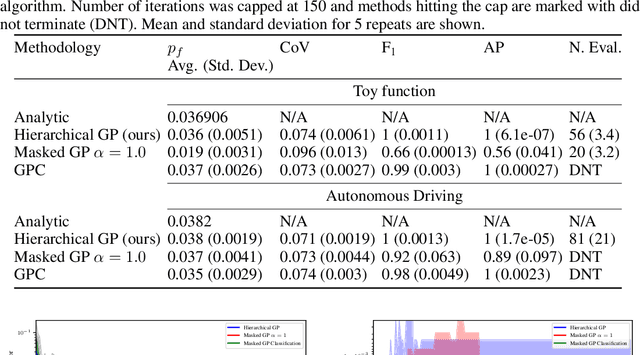
In engineering design, one often wishes to calculate the probability that the performance of a system is satisfactory under uncertainty. State of the art algorithms exist to solve this problem using active learning with Gaussian process models. However, these algorithms cannot be applied to problems which often occur in the autonomous vehicle domain where the performance of a system may be undefined under certain circumstances. Na\"ive modification of existing algorithms by simply masking undefined values will introduce a discontinuous system performance function, and would be unsuccessful because these algorithms are known to fail for discontinuous performance functions. We solve this problem using a hierarchical model for the system performance, where undefined performance is classified before the performance is regressed. This enables active learning Gaussian process methods to be applied to problems where the performance of the system is sometimes undefined, and we demonstrate this by testing our methodology on synthetic numerical examples for the autonomous driving domain.
Query-based Hard-Image Retrieval for Object Detection at Test Time
Sep 23, 2022
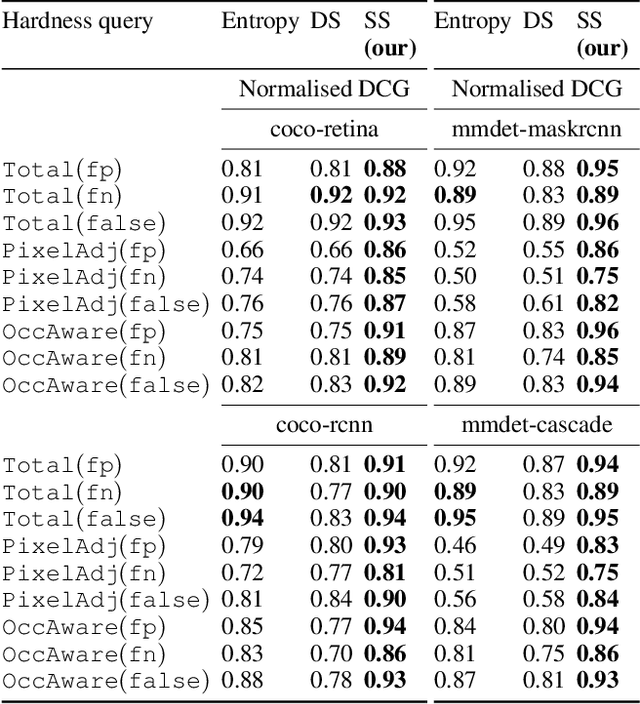
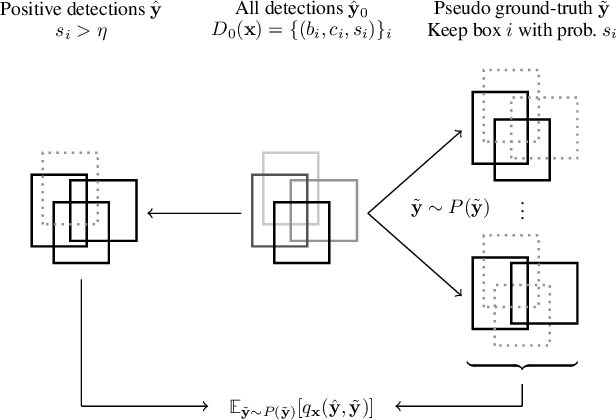
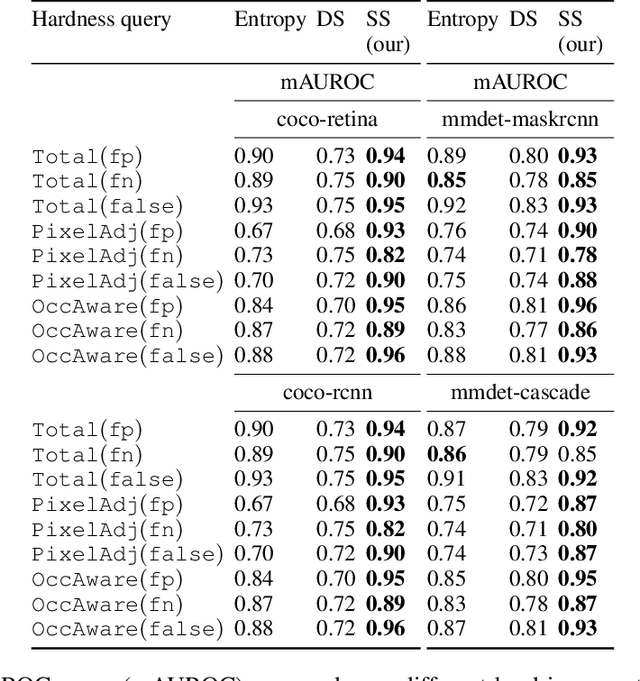
There is a longstanding interest in capturing the error behaviour of object detectors by finding images where their performance is likely to be unsatisfactory. In real-world applications such as autonomous driving, it is also crucial to characterise potential failures beyond simple requirements of detection performance. For example, a missed detection of a pedestrian close to an ego vehicle will generally require closer inspection than a missed detection of a car in the distance. The problem of predicting such potential failures at test time has largely been overlooked in the literature and conventional approaches based on detection uncertainty fall short in that they are agnostic to such fine-grained characterisation of errors. In this work, we propose to reformulate the problem of finding "hard" images as a query-based hard image retrieval task, where queries are specific definitions of "hardness", and offer a simple and intuitive method that can solve this task for a large family of queries. Our method is entirely post-hoc, does not require ground-truth annotations, is independent of the choice of a detector, and relies on an efficient Monte Carlo estimation that uses a simple stochastic model in place of the ground-truth. We show experimentally that it can be applied successfully to a wide variety of queries for which it can reliably identify hard images for a given detector without any labelled data. We provide results on ranking and classification tasks using the widely used RetinaNet, Faster-RCNN, Mask-RCNN, and Cascade Mask-RCNN object detectors.
Attacking deep networks with surrogate-based adversarial black-box methods is easy
Mar 16, 2022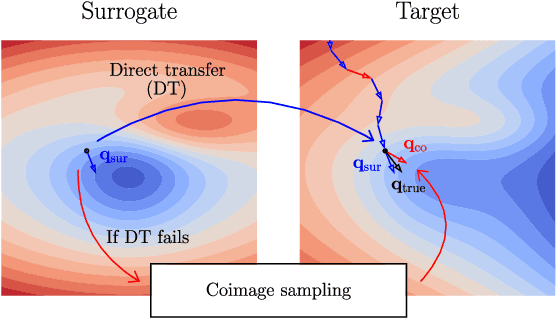
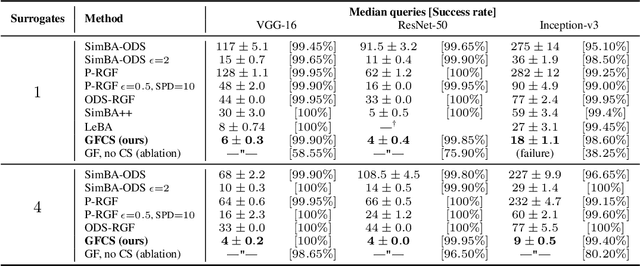
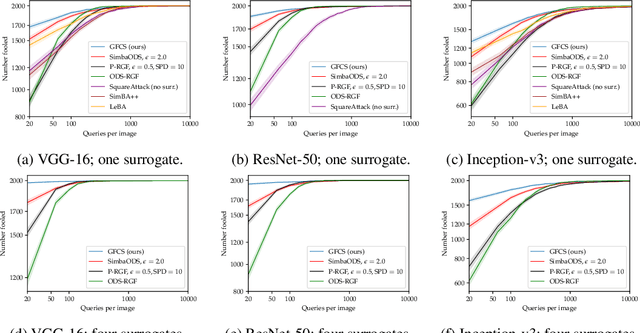
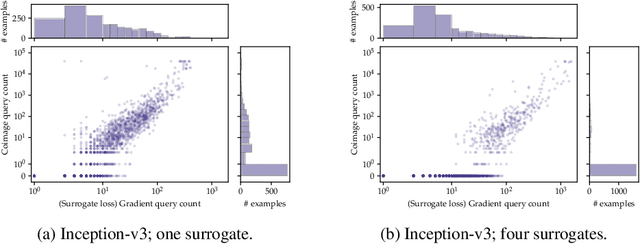
A recent line of work on black-box adversarial attacks has revived the use of transfer from surrogate models by integrating it into query-based search. However, we find that existing approaches of this type underperform their potential, and can be overly complicated besides. Here, we provide a short and simple algorithm which achieves state-of-the-art results through a search which uses the surrogate network's class-score gradients, with no need for other priors or heuristics. The guiding assumption of the algorithm is that the studied networks are in a fundamental sense learning similar functions, and that a transfer attack from one to the other should thus be fairly "easy". This assumption is validated by the extremely low query counts and failure rates achieved: e.g. an untargeted attack on a VGG-16 ImageNet network using a ResNet-152 as the surrogate yields a median query count of 6 at a success rate of 99.9%. Code is available at https://github.com/fiveai/GFCS.
Parameter-free Online Test-time Adaptation
Jan 15, 2022



Training state-of-the-art vision models has become prohibitively expensive for researchers and practitioners. For the sake of accessibility and resource reuse, it is important to focus on adapting these models to a variety of downstream scenarios. An interesting and practical paradigm is online test-time adaptation, according to which training data is inaccessible, no labelled data from the test distribution is available, and adaptation can only happen at test time and on a handful of samples. In this paper, we investigate how test-time adaptation methods fare for a number of pre-trained models on a variety of real-world scenarios, significantly extending the way they have been originally evaluated. We show that they perform well only in narrowly-defined experimental setups and sometimes fail catastrophically when their hyperparameters are not selected for the same scenario in which they are being tested. Motivated by the inherent uncertainty around the conditions that will ultimately be encountered at test time, we propose a particularly "conservative" approach, which addresses the problem with a Laplacian Adjusted Maximum-likelihood Estimation (LAME) objective. By adapting the model's output (not its parameters), and solving our objective with an efficient concave-convex procedure, our approach exhibits a much higher average accuracy across scenarios than existing methods, while being notably faster and have a much lower memory footprint. Code available at https://github.com/fiveai/LAME.
Making Better Mistakes: Leveraging Class Hierarchies with Deep Networks
Dec 19, 2019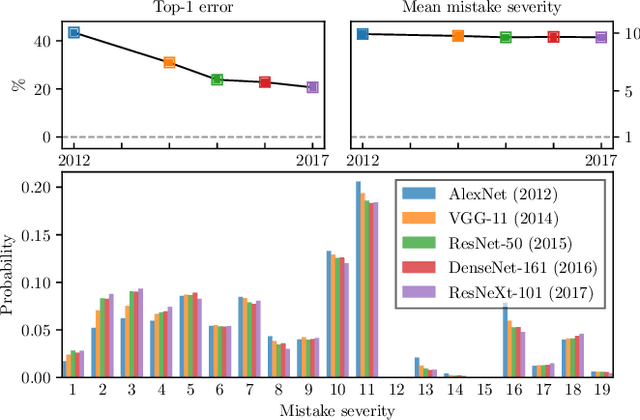
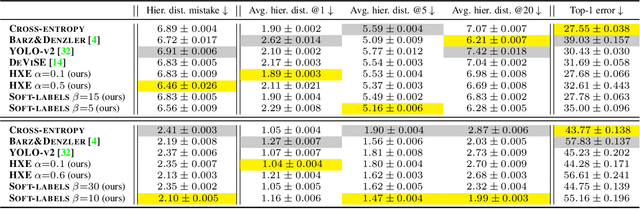
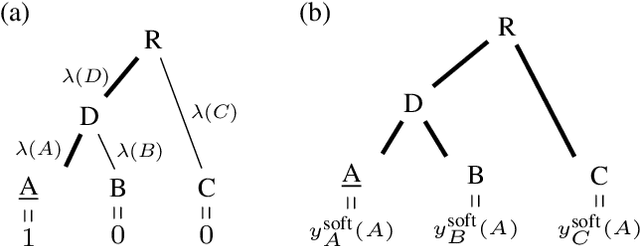
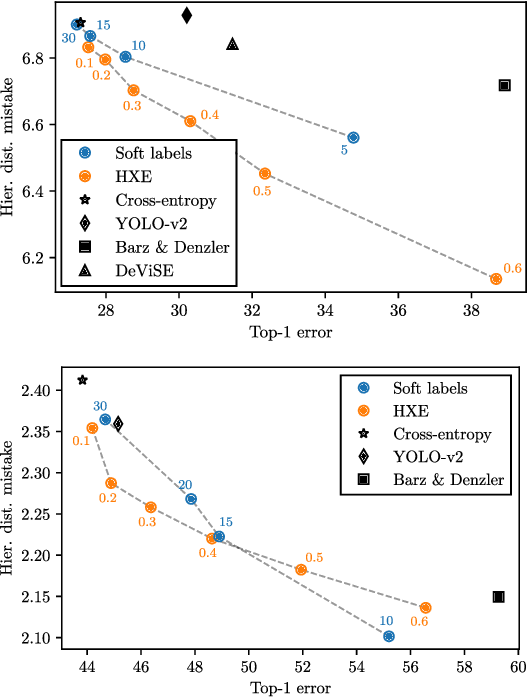
Deep neural networks have improved image classification dramatically over the past decade, but have done so by focusing on performance measures that treat all classes other than the ground truth as equally wrong. This has led to a situation in which mistakes are less likely to be made than before, but are equally likely to be absurd or catastrophic when they do occur. Past works have recognised and tried to address this issue of mistake severity, often by using graph distances in class hierarchies, but this has largely been neglected since the advent of the current deep learning era in computer vision. In this paper, we aim to renew interest in this problem by reviewing past approaches and proposing two simple modifications of the cross-entropy loss which outperform the prior art under several metrics on two large datasets with complex class hierarchies: tieredImageNet and iNaturalist19.